【Day 4】输出之後,BERT转换的Embedding怎麽用?
在此之前,我们已经介绍过BERT的核心概念迁移学习Transfer Learning以及它的输入输出。那麽接下来的问题就是BERT将词语转换为包含了上下文资讯的Embedding之後,怎麽继续使用它们来完成具体的任务。
BERT可以完成哪些任务
理论上BERT系列模型可以做所有的NLP任务,这并非是一句夸张。如果说Google的原始版本BERT仍有一些限制,在部分任务上(例如自然语言生成)表现不佳,但如今BERT家族模型已经大大扩充,许多新的模型例如BART、T5等完全可以用来做生成任务,效果也不亚於GPT-2等。而另一方面,下游任务也仍是一个有待开发的领域,BERT的潜力仍被完全挖掘,所以这边所提的只会是目前最普遍的一些BERT下游任务,但绝不意味着它的界限。
- 序列分类 Sequence Classification:包括单序列分类与多序列分类(通常为2个)。除了大家熟悉的正负情绪分类、多标签分类等,句子关系的判断也可以被当作一个分类问题。简单来说,输入是序列,输出是标量都可以是分类问题。如果要输出的是浮点数,则是回归问题,但其原理与序列分类基本一致,也就不再多做讨论。
- 词分类 Token Classification:序列的单位是Token,一个个词语。一些任务需要从序列中标记特定词语或序列片段。比较知名的当属NER命名实体识别任务,它要求从文本中识别出人物、时间、地点等专有名词。因为每一个词都有可能是专有名词的一部分,所以本质上这种任务是对於每一个Token进行分类,判断其是否是专有名词的组成成分。
- 问答 Question Answering:问答则是一个比较特殊的类别,它其实包括了序列分类,也有可能包括词分类。这主要基於问答的类别而定。如果是撷取式问答(给定情景文本和问题,从情景文本中摘取答案),则偏向词分类;如果是多选项的选择题问答,则更接近序列分类。
- 生成/摘要 Summarization:此处的摘要主要指生成式的摘要任务。通常是给定长文本序列,以生成的方式回应短文本摘要。而其他类的生成问题则有更多应用,包括生成小说、论文、自动撰写新闻等等。
Token选取与Output Layer
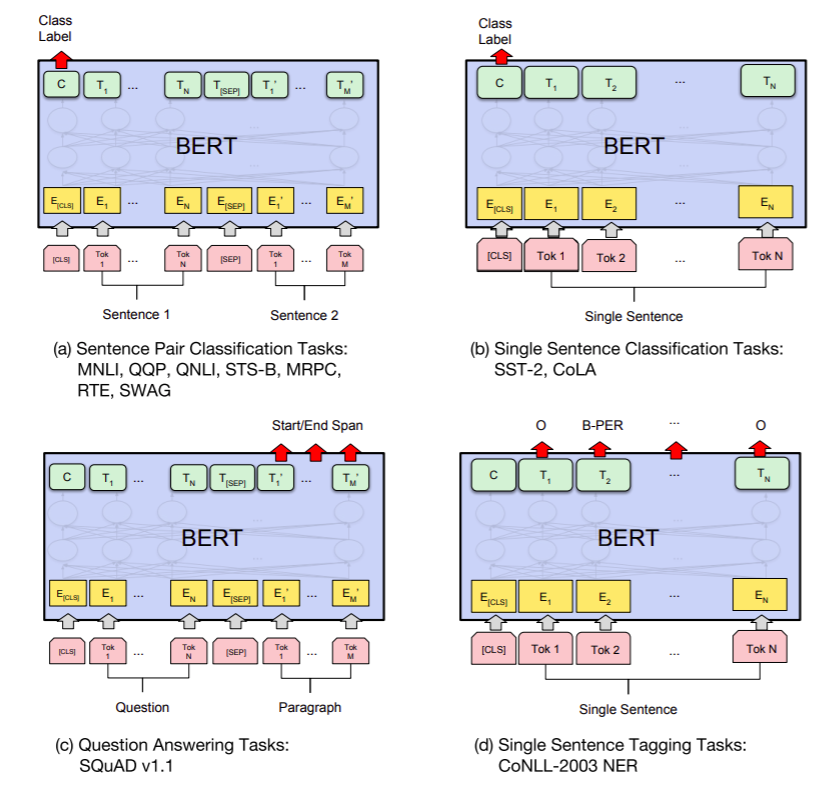
这张图片来自BERT原paper,作者解释了BERT在四大下游任务中应用的方式。主要需要关注的有两个重点:(1)Token选取,哪个Token的Embedding拿来当作我下游任务的data (2)Output Layer设计,Output Layer即将BERT输出的Embedding作为输入,然後直接输出下游任务可用的数值输出的模型。
以下,我会分别简介BERT原文中作者提出的四个任务应用方式:
a.句子对分类
此类任务的输入为两个句子(顾名思义句子对嘛),输出则是这两句话的每一个序列的Token Embeddings。而此任务的输出则是多个标量,也就是此句子对为各类别的可能性。通常会选择最高的值对应的Class当作答案。在这里,BERT作者们推荐的做法是将输出的[CLS]的768维向量Embedding拿去当作这两个句子的语义表示,然後接上一个简单的线性层作为Output Layer。原因是,在BERT模型的设计中,[CLS]会有一个全连接层与其他所有token相连,微调後可以当作聚合了整句的资讯。
不过,这样做是否真的合理呢?我们可以想象到把两句话的Token Embedding做一个平均应该也可以代表完整的语义,又或者在BERT的输出之後接一个LSTM或GRU,让回归神经网络替我们完成Embedding的聚合,这应该也是合理的。确实,近期有相关的研究发现[CLS]有不合理的部分,我会在之後文章中介绍。
b.单句分类
做法基本跟双句一样,取[CLS]过一个线性层即可。
c.撷取式问答
撷取式问答属於token级别的分类问题。Question和Paragraph被当作两个单独序列进行输入,然後模型输出的Paragraph部分的Embedding要每个都进行分类,分类也很简单,判断每个Token是答案的开始Start Position的机率以及是答案的结尾End Position的机率。所以每个token都会有两个标量的输出。而後再进行一些规则方式的後处理即可找出答案范围,例如最简单的方式就是取作为Start的机率最高的Token和作为End的纪律最高的Token以及它们中间的所有Token。对於每一个Token进行分类,用简单的线性层也就足够了。
d.命名实体识别NER
NER任务基本跟撷取式问答一致,它的差别主要来自於分类不再只是Start和End,而是分为O、B-PER、I-PER等Class。这种分类标记方法被称为BIO,是最常用的NER标记方法。O的意思是非命名实体,而B-、I-则指的是某命名实体的开始(Begining)或者中间部分(Intermediate)。每一个不同类别的命名实体都有自己特殊的两个对应Class。所以命名实体识别任务如果一次识别多个不同类的专有名词,通常难度就会更高。
以上是BERT原文的四个最常见任务的解决方式,你可能会困惑生成任务去了哪里?为什麽都只用简单的线性层?这些设计是固定的吗?本系列文章只是一点点用最新的研究成果来推翻我们这几天所说的定式。
今天我们可以先来回答前两个问题。
为什麽原始BERT没法做生成任务?
这个问题来自於原始BERT的限制,一方面是预训练任务,BERT的Pretraining Task都与生成无关,这意味着它没有相关的任务基础,如果要强行应用,需要更大的训练成本,可能也会破坏BERT已经学到的文本表示。BERT类型的模型逻辑一直都是,下游任务与上游任务越相近越好。这意味着模型再次适应的成本小,预训练的成果也比较能得以被保留。
为什麽都只用简单的线性层进行分类处理?
BERT的base版本有12层模型叠加,参数量为110M,而large版本的参数量更是三倍。BERT的输出部分使用简单线性层是因为BERT模型作为Encoder已经过於庞大和复杂,只用简单的线性层进行分类就能获得很好的效果了。而相反,如果後面使用了更复杂的模型例如LSTM,则会因为後接模型完全没有经过训练,而导致BERT的良好效果无法得到反馈。甚至,BERT学习到的参数还在反向传播过程中被破坏了。这就好像你把大学生和小学生都送去写报告,而大学生负责撰写报告初稿,小学生则在报告初稿基础上进行PPT报告,结果很可能两者都被惩罚,只是因为小学生的报告无法体现大学生的写作水平。
解决的办法当然也有,两个思路,要麽一开始就乾脆冻结BERT模型的参数更新,只让後接模型进行学习,到一定阶段後再引入BERT模型的更新。要麽就是让两者取不同的学习率,後接模型的学习率要远大於BERT模型(至少10倍),每次报告差的时候严厉惩罚小学生,让其改进,而对大学生则只是略微提醒。
>>: 从 JavaScript 角度学 Python(7) - 条件与回圈
Day08 Kibana - Query DSL 查询语法介绍
Elasticsearch提供了许多的搜寻语法,让我们能透过这些语法的组合,可以查询出各式各样的结果...
Azure - Day6 Azure Function
Hi~大家好,我今天想要介绍包括如下: < Azure Function > 基本介绍 ...
Day28:HTML(26) form(5)
“datalist”元素 “datalist”元素指定的一个预先定义的选项的列表”input”元素。...
DAY14:Toast显示讯息之简介
今天要来说到显示讯息,从我们使用电脑的过程中,很常会遇到跳出对话框让我们选择是或否或取消,或是当我们...
[Day - 05] - Spring Bean 运作与原理
Abstract 在前面章节我们已有进行模拟Spring框架之实作范例及介绍,使用者可理解到所有服务...