COVID-19 literature searching (BM25)文献搜寻-BM25方法
今天选个大资料集,来试试看BM25的语义搜寻。(据说BM25不必先做”断词处理”,说错了,是不必处理stopwords)
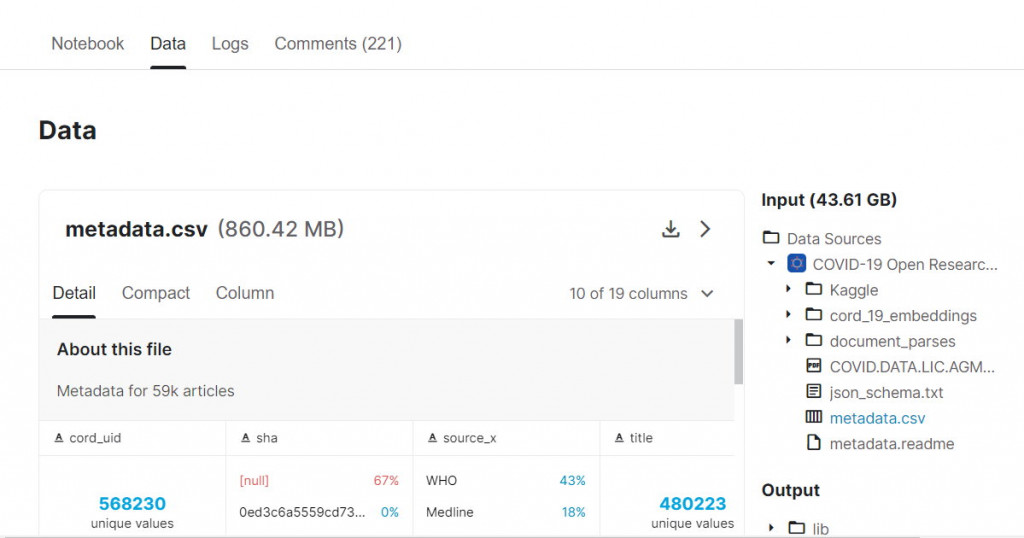
59万笔COVID-19相关文献860MB
资料集来源:Kaggle COVID-19 metadata.csv 568,230笔(不重覆者)(title有内容的有48万笔)
先前两篇请参考 < 语义检索 Semantic Search NLP >
< Semantic search BM25 COVID-19 dataset 自然语言BM25搜寻新冠文献资料>
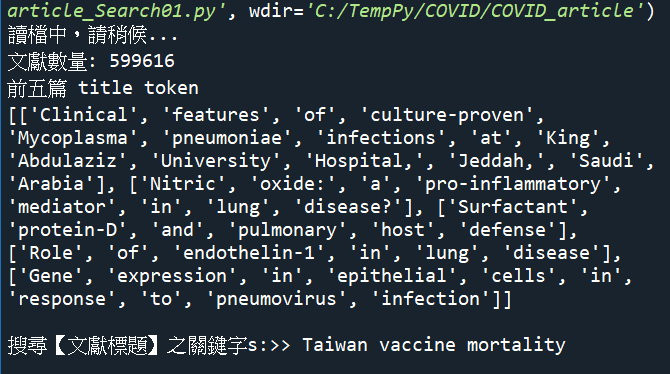
搜寻关键字: Taiwan vaccine mortality
搜寻标的: 文献Title
程序就简单一点,少一点花俏。
- 读档csv (读档较费时,请稍待)
- 取我们要的相关栏位
- 给关键字s (可多词、空白隔开)
- 把文献title tokenize
- 计算 BM25 score
- 列出最高分数前10篇
- 结果存档
Source Code
''' article_search01.py
searching article title
BM25 method '''
from rank_bm25 import BM25Okapi
import pandas as pd
import numpy as np
''' main flow '''
# load csv file
# https://www.kaggle.com/maksimeren/covid-19-literature-clustering/data?select=metadata.csv
print('读档中,请稍候...')
df_raw = pd.read_csv('ArticleCOVID.csv',dtype=object)
# 测试 sample 1万笔
#df = df_raw.sample(n = 10000, random_state=20)
df = df_raw
#print(df.head())
# 取我们要的相关栏位
mtitle = df['title'].astype(str)
mabs = df['abstract'].astype(str)
murl = df['url'].astype(str)
mpubtime = df['publish_time'].astype(str)
mpmcid = df['pmcid'].astype(str)
mauthor = df['authors'].astype(str)
mjournal = df['journal'].astype(str)
mdoi = df['doi'].astype(str)
#print(len(mtitle),mtitle.shape)
#print(mtitle.iloc[5])
#--- 把文献title tokenize
tokenized_corpus = [doc.split(" ") for doc in mtitle]
print(f'文献数量: {len(tokenized_corpus)}')
print(f'前五篇 title token\n{tokenized_corpus[:5]}')
#--- initiate BM25
bm = BM25Okapi(tokenized_corpus)
# query --> 要查询的 keywords 可多词,以空格间隔
query = input('搜寻【文献标题】之关键字s:>> ')
tokenized_query = query.split(" ")
print(f'keywords数目: {len(tokenized_query)}\n tokenized: {tokenized_query}')
# 计算 BM25 score (log)
scores = bm.get_scores(tokenized_query)
# sort scores (take index)
s1 = np.argsort(scores)
sidx = s1[::-1] # reverse s1
print(sidx[:10]) # top 10 highest score papers
fw = open('article_result.txt','w',encoding='utf-8')
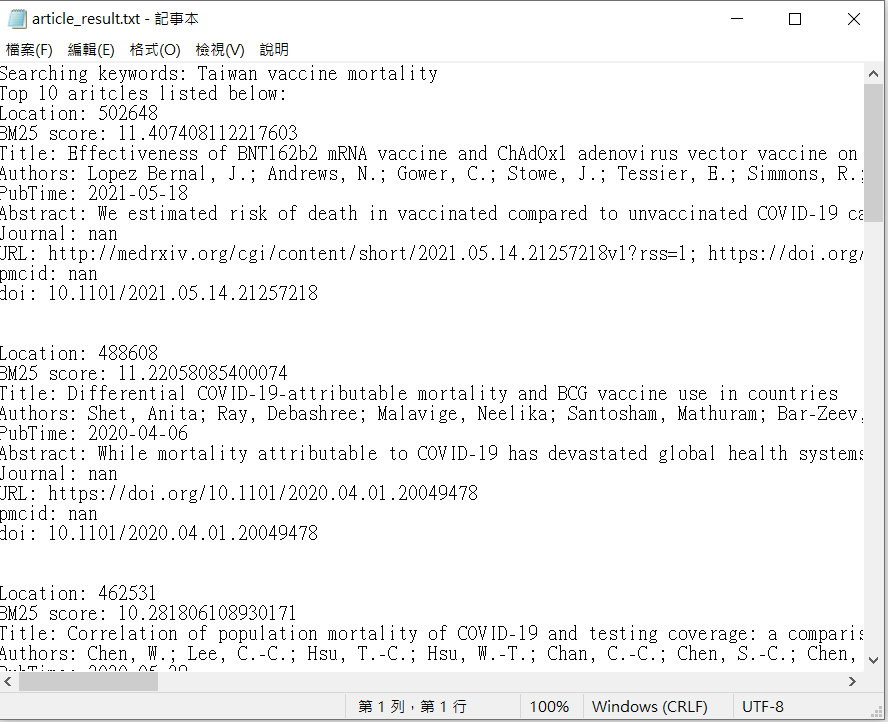
print(f'Searching keywords: {query}')
print('Top 10 aritcles listed below:')
print(f'Searching keywords: {query}',file=fw)
print('Top 10 aritcles listed below:',file=fw)
for i in range(10):
no = sidx[i]
tmp = f'Location: {no}\n'
tmp = tmp + f'BM25 score: {scores[no]}\n'
tmp = tmp + f'Title: {mtitle.iloc[no]}\n'
tmp = tmp + f'Authors: {mauthor.iloc[no]}\n'
tmp = tmp + f'PubTime: {mpubtime.iloc[no]}\n'
tmp = tmp + f'Abstract: {mabs.iloc[no][:500]}\n'
tmp = tmp + f'Journal: {mjournal.iloc[no]}\n'
tmp = tmp + f'URL: {murl.iloc[no]}\n'
tmp = tmp + f'pmcid: {mpmcid.iloc[no]}\n'
tmp = tmp + f'doi: {mdoi.iloc[no]}\n\n'
print(tmp)
print(tmp,file=fw)
fw.close()
print('搜寻结果,已存档完成: article_result.txt')
课堂小考 - 深度学习 Deep Learning Q&A(1)
Introduction to Machine Learning Ture and False D...
【Day 22】 Swift 5.5 Async/await 新特性
由於今天比较晚才到家,所以可能内容会比较少一点。 另外今天在火车上看到github上面有几个开源的 ...
Day15-D3 的 Zoom 缩放
本篇大纲:d3.zoom( )、zoom 旗下的API、范例 上一篇看完让人烧脑的Force之後,...
Day 28:面试
前言 这个环节的准备很特别,大部分时间都想着与考官的应答,这也是问题最开放、最及时所以也最难准备的环...
30天零负担轻松学会制作APP介面及设计【DAY 23】
大家好,我是YIYI,今天要来分享我设计的APP的PHOTOTYPE制做过程。 今日进度 今天的进度...