Python 演算法 Day 8 - 理论基础 统计 & 机率
Chap.I 理论基础
Part 4:统计 & 机率
Analyze the data through data visualization using Seaborn
5. Sampling Distributions 抽样分配
5-1. The Central Limit Theorem 中央极限定理
不论任何分配的母体,若样本够大,则每批样本的平均值 (X_bar) 的机率分配都会趋近常态分配(normal distribution)。
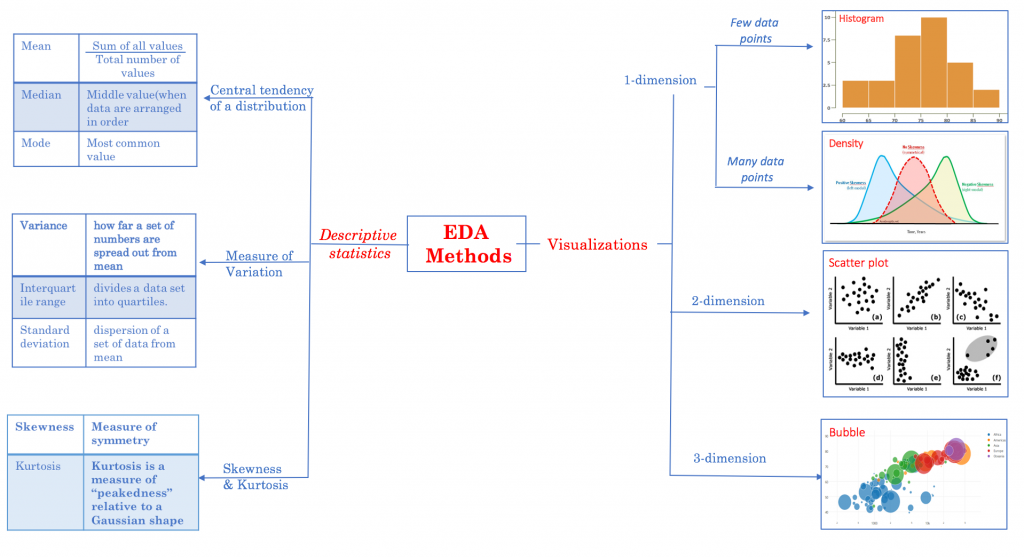
EX1. 抽取 10,000 批,每批 100 个样本,成功机率 0.25。
# 二项分配随机抽样 np.random.binomial(n, p, s)
# n: 每次抽样样本数
# p: 样本分配(母体机率)
# s: 抽样次数
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
n, p, s = 100, 0.25, 100000
X = np.random.binomial(n, p, s) # return 每次抽样成功次数 X
X_mean = X/n # 样本平均值
df = pd.DataFrame(X_mean, columns=['p-hat'])
print(df)
means = df['p-hat']
means.plot(kind='hist', title='Simulated Sampling Distribution', bins=50)
plt.savefig('pic 4-5 1')
plt.show()
print (f'Mean: {means.mean():.3f}')
>> Mean: 0.250
print (f'Std: {means.std():.3f}')
>> Std: 0.043
5-2. Confidence Intervals 信赖区间
基於某一信心水准(confidence level),例如95%,我们确信真实的参数值会落在特定区间内,称之。
信赖区间 = standard error x Z score
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
mu, sigma, n = 3.2, 1.2, 500
samples = list(range(0, 10000)) # 抽几次
X = np.array([])
X_bar = np.array([])
# np.random.normal(mean, std, n),return n-d array
for s in samples:
sample = np.random.normal(mu, sigma, n)
X = np.append(X, sample)
X_bar = np.append(X_bar, sample.mean())
df = pd.DataFrame(X_bar, columns=['X_bar'])
# 取得 X_mean 的 mean, std, 95% 信赖区间
m = df['X_bar'].mean() # X_bar 的平均
se = df['X_bar'].std() # 标准误
ci = stats.norm.interval(0.95, m, se) # return [m - 1.96 std, m + 1.96 std]
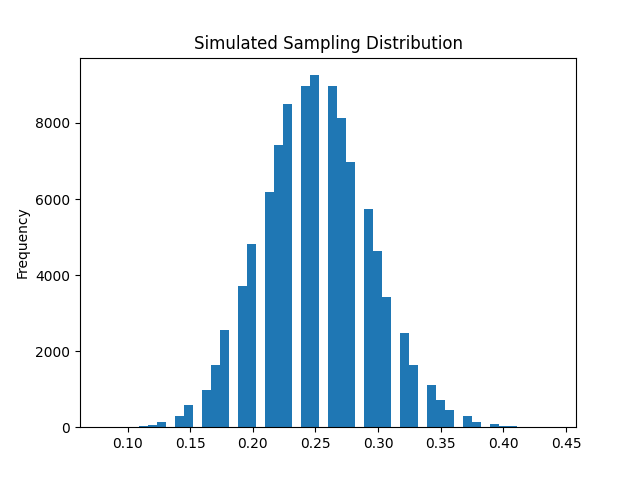
print (f'Sampling Mean: {m:.3f}')
>> Sampling Mean: 3.201
print (f'Sampling StdErr: {se:.3f}')
>> Sampling StdErr: 0.054
print (f'95% Confidence Interval: {ci}')
>> 95% Confidence Interval: (3.095256779885818, 3.3061798693546534)
# 作图
df['X_bar'].plot.hist(title='Simulated Sampling Distribution', bins=100)
plt.axvline(m, color='red', linestyle='dashed', linewidth=2)
plt.axvline(ci[0], color='magenta', linestyle='dashed', linewidth=2)
plt.axvline(ci[1], color='magenta', linestyle='dashed', linewidth=2)
plt.show()
6. Hypothesis Testing 假设检定
首先有几个名词需要了解:
-
确认偏误(Confirmation Bias):人根据主观感受,而非客观资讯建立起主观以为的社会现实。
-
逻辑公理:
矛盾率:命题不可又真又假
排中率:命题只可以真或假
根据矛盾率,可以由假命题反证明真命题。 -
Null Hypothesis 虚无假设(H0):主张「母群参数与某数字之间无差别」
-
Alternative Hypothesis 对立假设(H1):主张「母群参数与某数字之间有差别」
-
虚无假设与对立假设两者必须互斥(有 A 没 B)且穷尽(包含所有)
6-1. Hypothesis Testing 假设检定
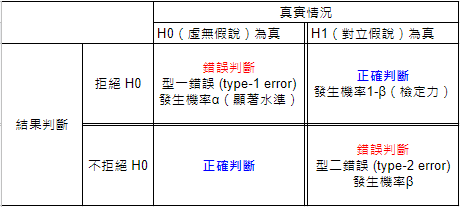
有了以上,接着我们进入假设检定
- 假设 H0 为真
- 以此为前提下,抽出这样的样本机率为?
- 若机率很小(10%? 5%? 1%? 0.1%?),则拒绝 H0(必须承受type I error)
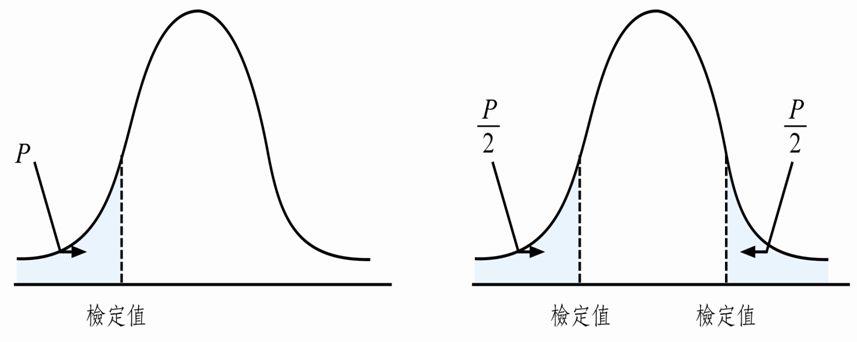
6-2. One-tailed test & Two-tailed test 单、双尾检定
顾名思义,单尾检定即假设拒绝区(critical value)仅有一边,其拒绝机率为 P。
反之,双尾检定即拒绝区包含两边,拒绝机率为 P/2。
EX1. 一般人平均智商为100,标准差为15,呈常态分配。三峡典狱长挑选30位受刑人的随机样本,发现智商平均为95.1,请检测:

EX2. 学生为此课程打分,评分-5~5。请检测学生是否喜欢这门课程?
A. H0: u <= 0(学生不喜欢)
B. H1: u > 0 (学生喜欢)
C. alpha = 1.645 (90%)
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(123)
low = np.random.randint(-5, -1, 6)
mid = np.random.randint(0, 3, 38)
high = np.random.randint(4, 6, 6)
sample = np.append(low, np.append(mid, high))
print("Min:" + str(sample.min()))
print("Max:" + str(sample.max()))
print("Mean:" + str(sample.mean()))
plt.hist(sample)
plt.show()
6-3. Z-test/t-test t/z 检定
- z-test:资料必须是随机样本,且母体来自常态分配,母体标准差已知。
- t-test:资料必须是随机样本,且母体来自常态分配,母体标准差未知,以样本标准差取代。
- 单样本(single sample):检定一组样本平均与母体平均是否有差异
- 双样本(two sample):检定两组样本平均之间是否有差异
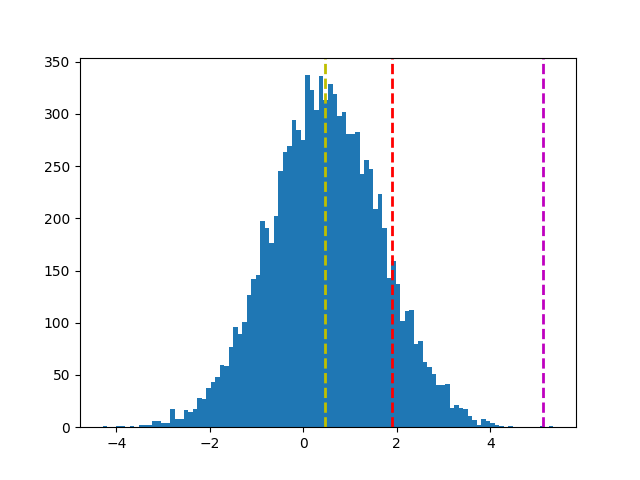
A. 单样本单尾检定:sample 有无显着大於 0?
from scipy import stats
import numpy as np
import matplotlib.pyplot as plt
# 样本(平均 0、标准差 1.15、抽取 10000 次)
sample = np.random.normal(0.5, 1.15, 100)
# scipy.stats.ttest_1samp(a, mother, alternative='two-sided') # 单样本检定
# a: 样本
# mother: 母体
# alternative: 'two-sided'(双尾), 'less', 'greater'(左/右尾)
z, p = stats.ttest_1samp(sample, 0, alternative='greater')
print(f'z-statistic:{z}')
>> z-statistic:3.9074479639245183
print(f'p-value:{p}')
>> p-value:8.53595856851376e-05
x_bar = np.random.normal(sample.mean(), sample.std(), 10000)
plt.hist(x_bar, bins=100)
plt.axvline(x_bar.mean(), c='y', linestyle='--', linewidth=2)
# 计算信心水准 95%,右尾检定结果(右边 5%)的 x_bar 值
ci = stats.norm.interval(0.90, 0, 1.15) # 此函数仅能计算双尾
plt.axvline(ci[1], c='r', linestyle='--', linewidth=2)
# 根据 mean + t*s 划出对立假设 x_bar 落点
plt.axvline(x_bar.mean() + z*x_bar.std(), c='m', linestyle='--', linewidth=2)
plt.show()
结论:紫色落於红色外,拒绝虚无假设。sample 有显着大於 0。
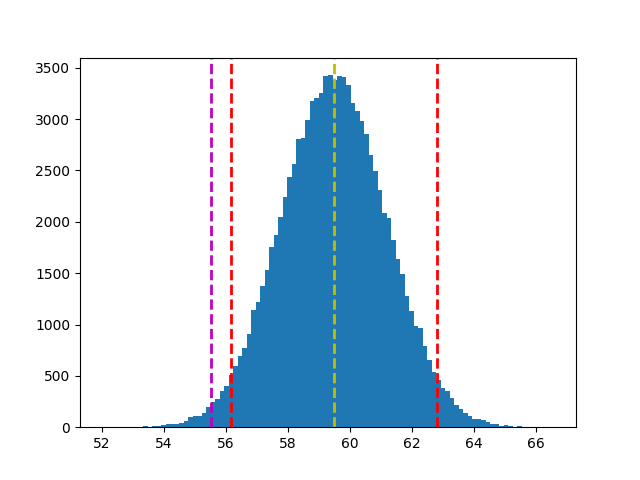
B. 双样本单尾检定:sample1 有无显着异於 sample2?
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
np.random.seed(123)
sample1 = np.random.normal(59.45, 1.5, 100)
sample2 = np.random.normal(60.05, 1.5, 100)
# scipy.stats.ttest_rel(a, b, alternative='two-sided') # 双样本检定
# a & b: 样本
# alternative: 'two-sided'(双尾), 'less', 'greater'(左/右尾)
t, p = stats.ttest_rel(sample1, sample2) # , alternative='greater'
print(f't-statistic:{t}')
>> t-statistic:-2.3406857739212583
print(f'p-value:{p}')
>> p-value:0.021254108930688475
# 根据 sample1 平均值 & 样本标准差,划出抽取 100000 次(每次100批)分配
s1_bar = np.random.normal(sample1.mean(), sample1.std(), 100000)
plt.hist(s1_bar, bins=100)
plt.axvline(s1_bar.mean(), c='y', linestyle='--', linewidth=2)
# 计算信心水准 95%,右尾检定结果(一边 5%)的 x_bar 值
ci = stats.norm.interval(0.95, s1_bar.mean(), s1_bar.std())
plt.axvline(ci[0], c='r', linestyle='--', linewidth=2)
plt.axvline(ci[1], c='r', linestyle='--', linewidth=2)
# 根据 mean + t*s 划出对立假设 x_bar 落点
plt.axvline(s1_bar.mean() + t*s1_bar.std(), c='m', linestyle='--', linewidth=2)
plt.show()
结论:sample1 显着不同於 sample2
.
.
.
.
.
Homework Ans:
#1. 今彩 539 (https://www.taiwanlottery.com.tw/dailycash/index.asp)
- 请问各个奖项中奖机率为?
- 请问每张彩券平均报酬率?
各奖项的中奖方式如下表:

奖金如下:

解答如下:
import scipy.special as sps
import numpy as np
name = ['头奖', '二奖', '三奖', '四奖']
bonus = [8000000, 20000, 300, 50]
total = []
for i in range(4):
prob = sps.comb(5, 5-i) * sps.comb(34, i) / sps.comb(39, 5)
money = sps.comb(5, 5-i) * sps.comb(34, i) * bonus[i]
total.append(money)
print(f'{name[i]} 中奖机率为: {prob*100 :.4f} %')
gain = np.array(total).sum()/sps.comb(39, 5)
cost = 50
print()
print(f'平均每注中奖金额: {gain :.2f}')
print(f'平均每注投报率为: {(gain-cost)*100/cost :.2f} %')
>> 头奖 中奖机率为: 0.0002 %
二奖 中奖机率为: 0.0295 %
三奖 中奖机率为: 0.9744 %
四奖 中奖机率为: 10.3933 %
平均每注中奖金额: 27.92
平均每注投报率为: -44.16 %
#2. 使用 sklearn 内建资料集 "load_boston" 来预测波士顿房价
A. 一次回归求解:
# A-1. Data prepare 准备资料
from sklearn import datasets
ds = datasets.load_boston()
import pandas as pd
X = pd.DataFrame(ds.data, columns=ds.feature_names)
y = ds.target # 房价
# A-2. Data clean 资料清理
print(X.isnull().sum().sum())
>> 0
# A-4. Split 拆分资料
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
# A-3. Feature Engineering 特徵工程
# 标准化、归一化,严谨的作法是放在 4. Split 後,以此避免训练资料与测试资料互相干扰。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train) # 训练资料要特徵缩放
X_test = scaler.transform(X_test) # 测试资料则仅做特徵转换
# A-5. Train Model 机器训练
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
clf.fit(X_train, y_train)
print(clf.coef_) # 回归线系数
>> [-0.73333119 1.29309093 0.15261025 0.61015457 -2.18126673 2.48140152
0.18613576 -3.10258233 2.78838943 -2.32101423 -1.97367244 0.76910136
-4.00329437]
print(clf.intercept_) # 回归线偏差值(截距)
>> 22.450247524752527
# 最大影响因子
import numpy as np
print(ds.feature_names[np.argmax(clf.coef_)]) # 系数最大项
>> RAD
print(np.max(clf.coef_)[::-1]) # 值
>> 2.78838943
# A-6. Score Model
score = clf.score(X_test, y_test)
print('Model Score:', score)
>> Model Score: 0.7445778921293265
# 计算 MSE (mean square error)
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error(y_test, clf.predict(X_test))
print('MSE=', MSE)
>> MSE= 21.285739578017278
# 均方根误差
RMSD = mean_squared_error(y_test, clf.predict(X_test)) ** .5
print('RMSD=', RMSD)
>> RMSD= 4.61364710159081
# 判定系数(之後会讲)
from sklearn.metrics import r2_score
judge = r2_score(y_test, clf.predict(X_test))
print('R2 Score=', judge)
>> R2 Score= 0.7445778921293265
B. 二次回归
一次回归结果看来准确率还不够高,
我们可以用 sklearn 中的 PolynomialFeatures 调整自由度为 2:
# B-1. Data prepare 准备资料
from sklearn import datasets
ds = datasets.load_boston()
import pandas as pd
X = pd.DataFrame(ds.data, columns=ds.feature_names)
y = ds.target # 房价
# 使用 sklearn 中的 PolynomialFeatures 转换为二次回归
# 预设 degree=2,即 Y 会由 [1, a, b, a^2, ab, b^2] 组成
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
X2 = poly.fit_transform(X)
# B-2. Data clean 资料清理
# B-4. Split 拆分资料
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X2, y, test_size = 0.2)
# B-3. Feature Engineering 特徵工程
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train) # 训练资料特徵缩放
X_test = scaler.transform(X_test) # 测试资料仅做转换
# B-5. Train Model 机器训练
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
clf.fit(X_train, y_train)
# B-6. Score Model
score = clf.score(X_test, y_test)
print('Model Score:', score)
>> Model Score: 0.8832125484403865
# 计算 MSE (mean square error)
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error(y_test, clf.predict(X_test))
print('MSE=', MSE)
>> MSE= 10.88594930129324
# 均方根误差
RMSD = mean_squared_error(y_test, clf.predict(X_test)) ** .5
print('RMSD=', RMSD)
>> RMSD= 3.299386200688431
C. 矩阵公式
最後,我们用矩阵公式 A = (X'*X)^-1*X'*Y求解:
# C-1. Data prepare 准备资料
from sklearn import datasets
ds= datasets.load_boston()
import pandas as pd
X = pd.DataFrame(ds.data, columns=ds.feature_names)
y = ds.target
# print(X.head())
# C-4. Split 拆分资料
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
# C-5. 矩阵运算
# 最後一行补1
import numpy as np
b_train = np.ones((X_train.shape[0], 1))
# print(b_train.shape) # (404, 1)
# 黏合
X_train=np.hstack((X_train, b_train))
# # 套用公式 A = (X' * X)^-1 * X' * Y
# print(X_train.T.shape) # (14, 404)
# print(X_train.shape) # (404, 14)
# print(y_train.T.shape) # (404,)
A = np.linalg.inv(X_train.T @ X_train) @ X_train.T @ y_train
print(A.shape)
# matrix(X_train, y_train)
# # 计算 MSE (mean square error)
# print(X_test.shape) # (102, 13)
# print(y_test.shape) # (102,)
b_test = np.ones((X_test.shape[0], 1))
# print(b_test.shape) # (102, 1)
# 黏合
X_test=np.hstack((X_test, b_test))
MSE = np.sum((X_test @ A - y_test) ** 2) / y_test.shape[0]
print('MSE=', MSE)
>> MSE= 17.679787655718744
# 均方根误差
RMSD = MSE ** 0.5
print('RMSD=', RMSD)
>> RMSD= 4.204733957781246
.
.
.
.
.
Homework:
使用假设检定,检定近40年(10届)美国总统的身高是否有差异?
(Data: president_height.csv)
<<: Day 7 - Rancher 系统管理指南 - RKE Template
>>: Day 07 Azure cognitive service- 於是,Chatbot 也有了智慧
Android学习笔记30
昨天做完了验证码,那今天就把他加入到帐号密码之中 首先要先建立一个imageview来存放验证码,并...
【DAY 8】SharePoint 的应用五花八门,什麽最适合你?(上)
哈罗 ~ 大家好,希望昨天的文章有让大家更认识 SharePonit 这个工具到底可以用来做什麽。昨...
Android学习笔记24
今天来用checkbox首先先在xml新增 <CheckBox android:id=&quo...
Backtrader - 策略收益
以下内容皆参考 Backtrader 官网 昨天介绍了 backtrader 如何去执行一个策略,今...
day 21 - NSQ Producer
Producer是讯息发送方, 他会对nsqd发送讯息, nsqd支援TCP(port:4150) ...