【Day 3】BERT的输出与它们的意义
BERT输出了什麽?
回应上一篇关於词嵌入Token Embedding的讨论,BERT的输出就是文本序列中每个词单位的高维向量表示,你也可以把它当成一连串抽取的特徵。所以BERT类型的模型本质上做的是抽取特徵的工作,也有人把负责这个过程的模型称为Encoder,将原始资料变成计算机方便运算、可以理解的格式。在进入後续的Decoder,也就是为不同类型的具体任务设计模型输出之前,让我们先厘清BERT的输出是什麽、格式如何、有什麽意义。
如果你还不太了解BERT的机制,对於深度学习也缺乏实作经验,而只是先使用了一些范本Script跑BERT模型,你可能会困惑於BERT的输出。因为在Python中列印这些输出,你只会看到一连串数字的排列。如果用shape或size之类的功能查看维度,你通常会获得类似下方的输出:
torch.Size([12,160,768])
看上去是一个三维的矩阵,但不同的数字各自代表什麽意义,每一个维度又是什麽。这好像与我们之前所说的每一个词都被编码为高维度向量不一致。别着急,让我们先来了解一下在实作中BERT模型的运算过程。
Batch、序列长度与Hidden State Size
- Batch是机器学习中常使用的概念,它指的是我们每次训练或推论时送固定数量的样本给模型,Batch Size就是这个每次送入的样本数量。在训练BERT模型时,我们一般取12、16、32、64等数值(取决於GPU显存)。
- 序列长度顾名思义就是你送入的每一个样本的文本序列长度,值得注意的是,因为BERT模型通常会将一些字词进行拆解,分为wordpiece後再进行运算,而且会额外插入模型专用的特殊token(
<CLS>,<SEP>等),所以送给模型的序列长度通常比原始资料的文本长度更长一些。 - Hidden State Size就是我们所说的词嵌入的维度,它是由模型在预训练阶段即规定好的。Hidden State Size越大代表抽取的特徵越多,运算耗费时间更久,但也更有可能获得更好的效果。BERT的Base版模型的Hidden State Size为768,Large版本则为1024。
以上三个概念正是对应於BERT Encoding後的模型输出的三个维度的数值。在上面的例子中,12代表Batch Size为12,160指的是该批次中最长的样本的序列长度(其他短於160的样本则被<PAD>补齐到160),768则代表Hidden State Size,说明这是一个Base版本BERT模型的输出,每一个词都被转化为768维的向量了。它们共同构成了一个三维的大型矩阵。
以视觉化的方式来理解则是这样:
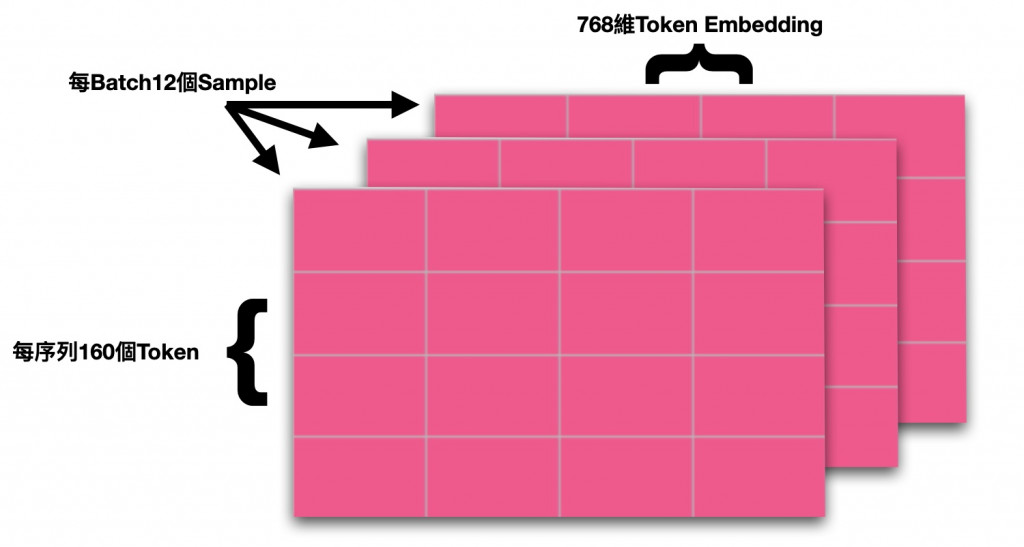
理解清楚输出的格式对於後续的实作会有极大帮助,许多时候模型的资料处理的问题都出在矩阵维度上。
脉络化词嵌入(Contextualized Word Embedding)的意义
Word2Vec生成的词嵌入大概已经成为NLP的常识了,国王-王后或是各国名称与首都在空间上的相似距离这类说明已经有不少人进行过讲解。现在的问题是BERT所输出的Contextualized Word Embedding与一般的Word Embedding有什麽差别?
这方面也有人做过具体的研究了,以Cold这个词为例,通常有以下三种可能的意义:温度上的冷、态度上的冷或症状上的冷(医学中使用)。而Yuqi Si等人的研究就是针对BERT研究Cold的嵌入表达是否能有效区分出它在不同脉络下的意义。以下这张图是我们理想中的结果,中间的X代表Word2Vec这种固定的词向量,而周围三个则是BERT针对不同脉络下的嵌入表达。
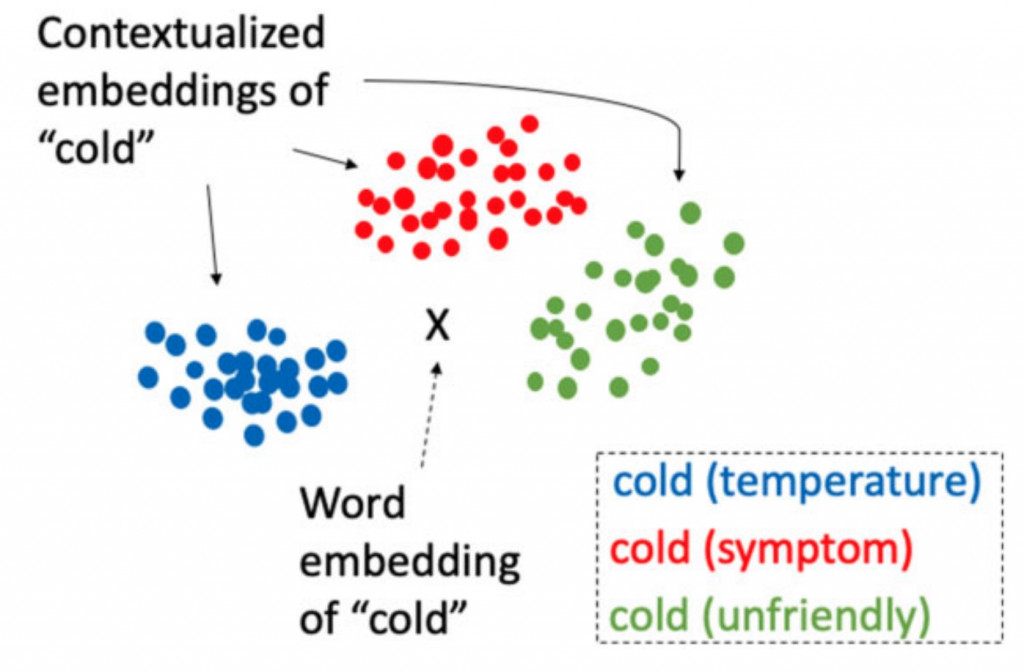
实验证明,BERT确实很好地完成了这项任务,而在MIMIC(一个临床文本资料集)上预训练的BERT则比在维基百科等通用文本上训练的BERT表现得更好:
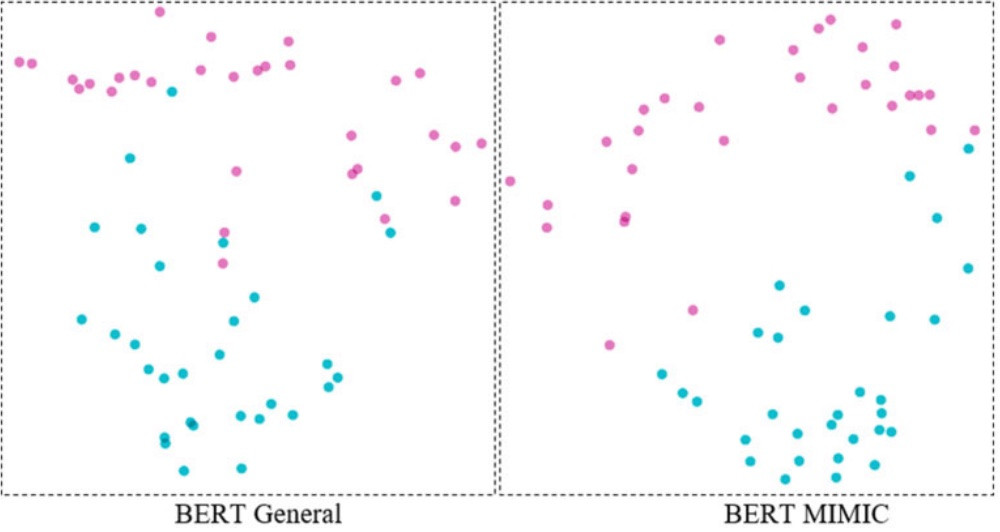
这张图片中的粉色代表温度意义上的Cold,而蓝色则代表症状意义上的Cold。这张图是PCA降维後的结果,将768维向量降到2个维度,方便视觉化展示。所以,尤其在一些用语意义与一般情境不同的专业领域,BERT这类预训练模型因为其区分的精细程度更好、有上下文脉络,而可以比Word2Vec发挥更大的用途。
今天的BERT输出只是简单介绍,後续我们还会有一篇专门文章来讨论BERT模型不同层之间的嵌入差别。但这要在讲解完BERT模型的一些内部结构(Transformer)之後,敬请继续关注。
参考文献
Si, Y., Wang, J., Xu, H., & Roberts, K. (2019). Enhancing clinical concept extraction with contextual embeddings. Journal of the American Medical Informatics Association, 26(11), 1297-1304.
<<: [Day 1] Leetcode 1629. Slowest Key
设计安全考虑最少
-如何将 Cisco IOS 复制到 TFTP 服务器 TFTP 以其不需要身份验证和访问控制的简...
点光源与自发光
大家好,我是西瓜,你现在看到的是 2021 iThome 铁人赛『如何在网页中绘制 3D 场景?从 ...
现况访谈与差异分析
现况访谈 旨在确认资安目标与导入范围 差异分析 在现况谈访中依据 ISMS 内建的 114 个控制项...
C# 入门之函数(补充)
前面我们有讲过 C# 中的函数,今天我们补充一点。 在 C# 中,支持一种函数叫做 “匿名函数”,即...
【C language part 4】阵列与字串&函式
阵列 阵列是一群具有相同名称或资料型态的变数集合。 由於整个阵列中的变数均具有相同的名称,因此若要存...