[Day 20] 机器学习金手指 - Auto-sklearn
Auto-sklearn
今日学习目标
- 了解 Auto-sklearn 运作原理
- Meta Learning
- Bayesian Optimization
- Build Ensemble
- 实作 Auto-sklearn
- 采用鸢尾花朵资料集训练,并比较两种不同版本的 Auto-sklearn。
- 使用 pipelineprofiler 视觉化 AutoML 模型。
前言
Auto-sklearn 采用元学习 (Meta Learning) 选择模型和超参数优化的方法作为搜寻最佳模型的重点。此 AutoML 套件主要是搜寻所有 Sklearn 机器学习演算法以模型的超参数,并使用贝叶斯优化 (Bayesian Optimization) 与自动整合 (Ensemble Selection) 的架构在有限时间内搜寻最佳的模型。第一版的 Auto-sklearn 於 2015 年发表在 NIPS(Neural Information Processing Systems) 会议上,论文名称为 Efficient and Robust Automated Machine Learning。有别於其他的 AutoML 方法,Auto-sklearn 提出了元学习架构改善了贝叶斯优化在初始冷启动的缺点,并提供一个好的采样方向更快速寻找最佳的模型[1]。第二个版本於 2020 年发布,论文名称为 Auto-Sklearn 2.0: Hands-free AutoML via Meta-Learning。在新的版本中修改了元学习架构,并不依赖元特徵来选择模型选择与调参策略。而是引入了一个元学习策略选择器,根据资料集中的样本数量和特徵,订定了一个模型选择的策略[3]。
AutoML 视为 CASH 问题
在论文中作者将 AutoML 视为演算法选择和超参数优化 (Combined Algorithm Selection and Hyperparameter, CASH) 的组合最佳化问题。因为在 AutoML 领域当中将会面临两个问题。第一个是没有任何的演算法模型是可以保证在所有的资料集中表现最好,因此挑选一个好的演算法是自动化机器学习的首要任务。第二许多的机器学习模型往往依赖於超参数,透过不同的超参数设定可以取得更好的学习结果。例如在 SVM 方法中我们可以设定不同的核技巧让模型具有非线性的能力,或是透过超参数 C 限制模型的复杂度防止过度拟合。然而贝叶斯优化如今成为 AutoML 超参数搜寻的重要核心方法。

Auto-sklearn 架构
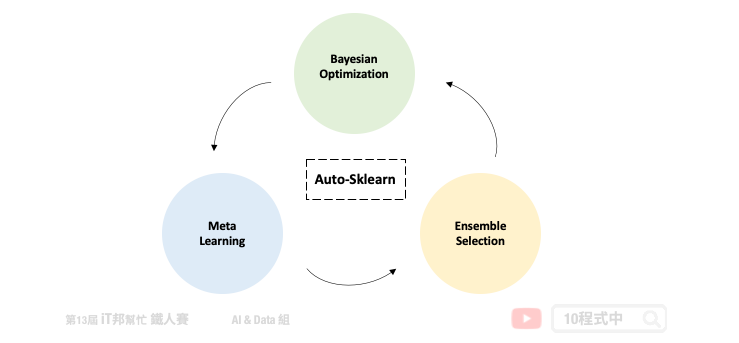
Auto-sklearn 可以被拿来处理回归和分类的问题。下图为第一版论文中所绘制的架构图。我们可以将 Auto-sklearn 切成三个部分,其中第一个是引入元学习机制来模仿专家在处理机器学习的先验知识。并采用元特徵让我们更有效率的去决定在新的资料集中该挑选哪一种机器学习模型。接着挑好模型後并透过贝叶斯优化来挑选合适的模型超参数,以及尝试一些资料前处理与特徵工程。最後挑选几个不错的模型并透过整体学习的技巧进行模型堆叠,将表现不错的模型输出结果做一个加权和或是投票。
- Meta Learning
- Bayesian Optimization
- Build Ensemble

Meta Learning
当我们想对新资料集做分类或回归时,Auto-sklearn 会先提取元特徵,具有相似元特徵的资料集在同一组超参数应该会有相似的表现。因此透过元特徵可以有效地评估在新资料集上应该使用哪种算法。元学习在这里的目的是为了要找一个不错的超参数做初始化,使其在一开始的表现优於随机的方法。并提供贝叶斯优化有个明确定方向。Auto-sklearn 参考了 OpenML 140 个资料集,并汇整了 38 个元特徵,例如:偏度、峰度、特徵数量、类别数量......等。首先为这 140 个资料集使用贝叶斯优化进行模型训练,并将这些资料集对应的模型与最佳的超参数储存起来。当有新的资料集进来时会先透过元特徵进行相似度匹配,并将匹配程度最高的前 k 个资料集 (预设k=25) 所对应的模型和超参数作为贝叶斯优化的初始设定。
Bayesian Optimization
在贝叶斯优化当中主要会寻找该资料集中最合适的资料前处理 (data pre-processors)、特徵前处理 (feature pre-processors) 与分类/回归模型。以上三大类合计共有 110 个超参数必须透过贝叶斯优化来寻找最适合的参数组合。其贝叶斯优化主要方法是透过建立目标函数的机率模型,并用它来选择最有希望的超参数来评估真实的目标函数。
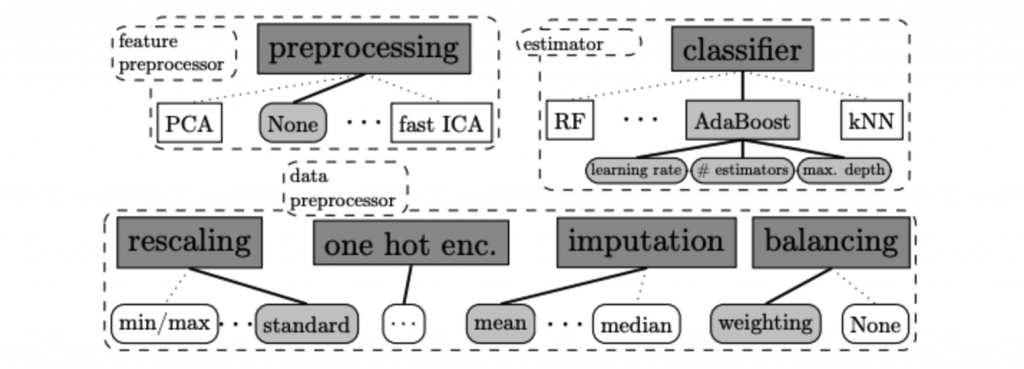
以下内容摘录自 Auto-sklearn v1.0 论文提供的内容 [1][2]
Data Pre-processors
在资料前处理部分 Auto-sklearn 提供了四种方法。包含特徵缩放、填补缺失值、类别特徵进行 one-hot encoding 与处理目标输出类别数量不平衡问题。
- Data Pre-processors
- 特徵缩放
- 填补缺失值
- one-hot encoding
- 类别资料不平衡
在新的版本中多了一些资料前处理方法,详细可以参考 Auto-sklearn data_preprocessing 的原始程序。
Feature Pre-processors
在特徵前处理部分 Auto-sklearn 提供了 12 种特徵处理的技巧,然而在众多方法中仅会挑选其中一种。
详细可以参考 Auto-sklearn feature_preprocessing 的原始程序。
Build Ensemble
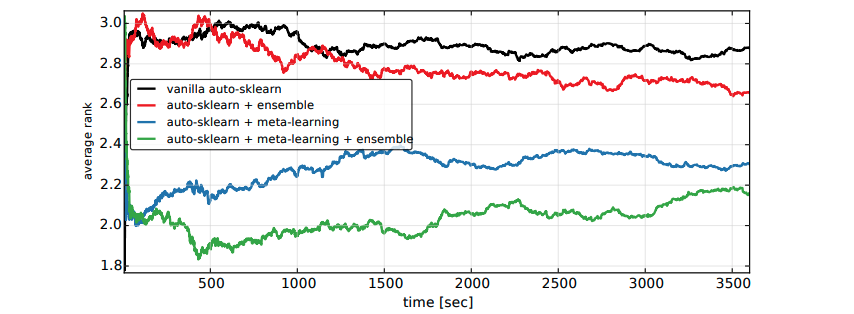
在 Auto-sklearn 训练阶段会产生许多表现优良的模型,最终透过贪婪法的 Bagging Ensemble Selection 方法来合并多个模型组合成一个更强更大的模型,并提高预测的准确性。下图为第一版论文中进行的实验,其中横轴为程序执行时间,纵轴为在时间内搜寻到的最佳模型的排名。我们可以发现绿色线条再加入了整体学习机制表现效果比尚未加入的蓝色线条实验来得好。并且在短时间内就可以得到不错的结果。
安装 Auto-sklearn
目前 Auto-sklearn 仅支援 Lunux 系统。若没有此系统的读者可以透过 Colab 体验。另外若安装过程中出现错误,必须先确认 swig 是否已完成安装。
pip install auto-sklearn
若使用 Colab 执行,安装完成後点选上方工具列 Runtime -> Restart runtime 重启才能正常执行此套件。
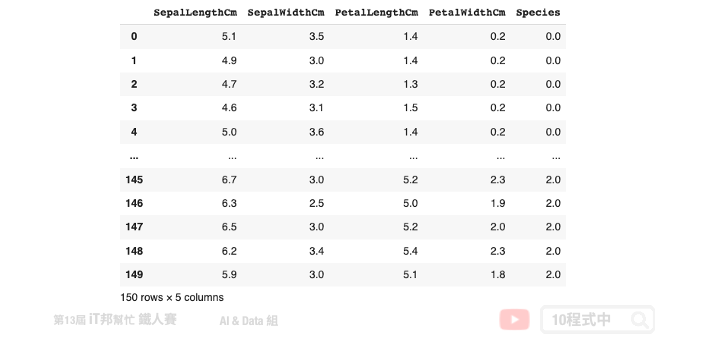
1) 载入资料集
本次范例沿用鸢尾花朵资料集,并使用 Auto-sklearn 来搜寻最佳的分类器模型。此外大家可以试着观察 Auto-sklearn 找到的最佳模型在训练集与测试集上的表现,并与前几天所介绍的那些机器学习演算法来做比较。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
iris = load_iris()
df_data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= ['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species'])
df_data
2) 切割训练集与测试集
我们按照花朵种类的数量对资料集以 7:3 的比例切割出训练集与测试集。其中参数 stratify=y 设定是确保训练集与测试集对於三种花朵类别的比例在这两个切出来的资料集中比例要一样,以免训练出来的模型有很大的偏差。
from sklearn.model_selection import train_test_split
X = df_data.drop(labels=['Species'],axis=1).values # 移除Species并取得剩下栏位资料
y = df_data['Species'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
print('train shape:', X_train.shape)
print('test shape:', X_test.shape)
输出结果:
train shape: (105, 4)
test shape: (45, 4)
Auto-sklearn
以下是模型常用的超参数以及方法,详细内容可以参考官方 API 文件。
Parameters:
- time_left_for_this_task: 搜寻时间(秒),预设3600秒(6分钟)。
- per_run_time_limit: 每个模型训练的上限时间,预设为time_left_for_this_task的1/10。
- ensemble_size: 模型输出数量,预设50。
- resampling_strategy: 资料采样方式。为了避免过拟合,可以采用交叉验证机制。预设方法为最基本的 holdout。
Attributes:
- cv_results_: 查询模型搜寻结果以及每个最佳模型的超参数。
Methods:
- fit: 放入X、y进行模型拟合。
- refit: 使用 fit 寻找好的参数後,再使用所有的资料进行最後微调。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- predict_proba: 预测每个类别的机率值。
- leaderboard: 显示 k 个 ensemble 模型并排名。
首先我们来测试第一版的 Auto-sklearn,建立一个分类器类型的自动化机器学习模型并设定相关的执行参数。在本次实验中我们设定模型搜寻总时间为 180 秒,每个模型训练时间限制 40 秒内。此外设定 resampling_strategy='cv' 即 K-Fold 交叉验证。此外必须另外设定 resampling_strategy_arguments 并给予 k=5,训练集切割为五等份。这意味着相同的模型要训练五次,每一次的训练都会从这五等份挑选其中四等份作为训练资料,剩下一等份未参与训练并作为验证集。
import autosklearn.classification
automlclassifierV1 = autosklearn.classification.AutoSklearnClassifier(
time_left_for_this_task=180,
per_run_time_limit=40,
resampling_strategy='cv',
resampling_strategy_arguments={'folds': 5}
)
automlclassifierV1.fit(X_train, y_train)
训练结束後我们可以来查看模型在训练集与测试集表现。大家可以试着调整模型训练时间以及一些控制参数,查看是否有没有帮助模型准确度提升。
# 预测成功的比例
print('automlclassifierV1 训练集: ',automlclassifierV1.score(X_train,y_train))
print('automlclassifierV1 测试集: ',automlclassifierV1.score(X_test,y_test))
输出结果:
automlclassifierV1 训练集: 0.9904761904761905
automlclassifierV1 测试集: 0.9111111111111111
使用 Auto-sklearn 2.0
在第二版的 Auto-sklearn 对模型搜寻进行了一些优化,并且可以自动搜寻好的资料采样方式。因此我们不特地去指定 resampling_strategy,查看表现是否能够提升。
from autosklearn.experimental.askl2 import AutoSklearn2Classifier
automlclassifierV2 = AutoSklearn2Classifier(time_left_for_this_task=180, per_run_time_limit=40)
automlclassifierV2.fit(X_train, y_train)
# 预测成功的比例
print('automlclassifierV2 训练集: ',automlclassifierV2.score(X_train,y_train))
print('automlclassifierV2 测试集: ',automlclassifierV2.score(X_test,y_test))
执行结果:
automlclassifierV2 训练集: 0.9904761904761905
automlclassifierV2 测试集: 0.9333333333333333
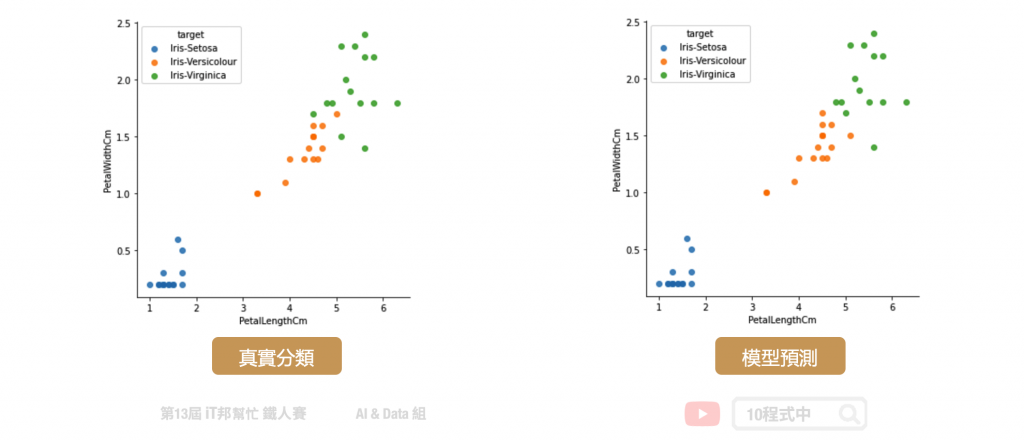
使用一样的搜寻时间与训练限制,最终训练出来的模型在训练集与测试集都表现不错。两者的准确率更接近了。这样的结果的确比系列教学所介绍的任一个单一模型还来得好。
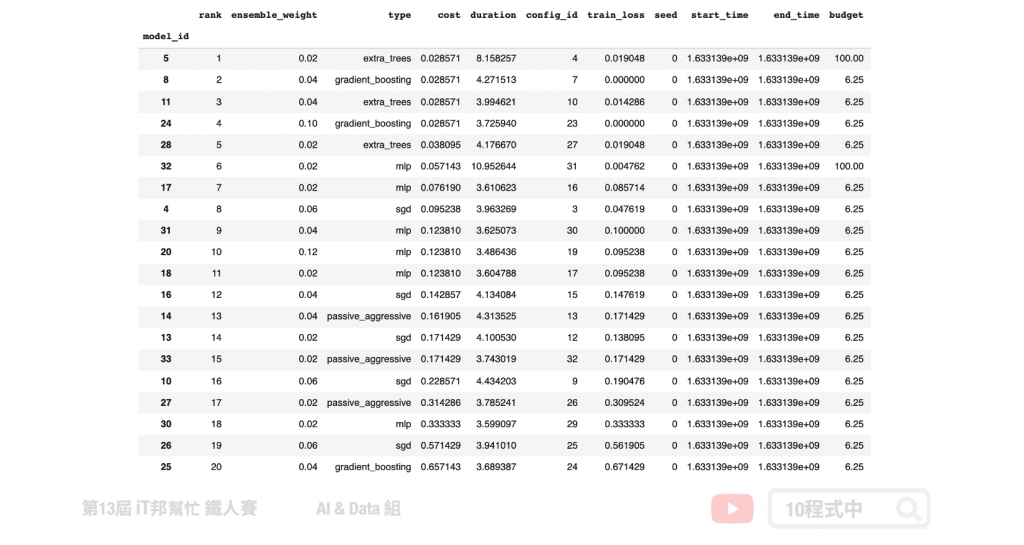
查看每个模型的权重
我们可以使用模型提供的方法查看最终训练结果,并查看 k 个 Ensemble 模型的训练结果以及每个模型的权重。
automlclassifierV2.leaderboard(detailed = True, ensemble_only=True)
输出模型
如果想将 AutoML 的模型储存起来,可以透过 joblib 将模型打包汇出。
from joblib import dump, load
# 汇出模型
dump(automlclassifierV2, 'model.joblib')
# 汇入模型
clf = load('model.joblib')
# 模型预测测试
clf.predict(X_test)
视觉化 AutoML 模型
首先安装 pipelineprofiler。
pip install pipelineprofiler
透过 PipelineProfiler 套件可以很快速地检视模型训练结果,以及每一个 Ensemble 模型的超参数以及资料前处理方式和特徵处理方法。
import PipelineProfiler
profiler_data= PipelineProfiler.import_autosklearn(automlclassifierV2)
PipelineProfiler.plot_pipeline_matrix(profiler_data)

Reference
- [1] Feurer, Matthias et al. “Efficient and Robust Automated Machine Learning,” Advances in neural information processing systems 2015.
- [2] Feurer, Matthias et al. “Supplementary Material for Efficient and Robust Automated Machine Learning,” Advances in neural information processing systems 2015.
- [3] Feurer, Matthias et al. “Auto-Sklearn 2.0: Hands-free AutoML via Meta-Learning,” arXiv, 2020.
- [4] Ono, Jorge et al. “PipelineProfiler: A Visual Analytics Tool for the Exploration of AutoML Pipelines,” arXiv, 2020.
- Auto Machine Learning笔记- Bayesian Optimization
- A Quickstart Guide to Auto-Sklearn (AutoML) for Machine Learning Practitioners
- Auto-Sklearn: Scikit-Learn on Steroids
本系列教学内容及范例程序都可以从我的 GitHub 取得!
>>: 当火灾发生时,势必要分流人群,让各个出口可以有效运用,让人群疏散
对象重用(Object reuse)&跨站脚本(Cross-Site Scripting -XSS)&SQL注入(SQL Injection)&会话劫持(Session Hijacking)
-什麽是应用程序安全风险? 对象重用(Object reuse) 根据NIST术语表,对象重用是指...
【第十一天 - Flutter GetX 架构教学】
前言 今日的程序码 => GIHUB GetX 介绍 GetX 官方文件 GetX 是一个很神...
Day 27 上传自己的 Image 到 Dockerhub
藉着 Day 14 建一个 Node.js 容器 所建立的基底,来制作一个 Image 并上传到 D...
Annotation in Kotlin
接下来就可以利用上面的 meta-annotation 去定义我们的属性。 @Target(Anno...
爬虫怎麽爬 从零开始的爬虫自学 DAY27 python网路爬虫开爬8-储存问题解决
前言 各位早安,书接上回我们将程序码的规模扩大成多档案的规模,也发现了三个大问题,今天我们就要来解决...