[Day 5] 资料产品第二层 - 资料加工术 - 资料聚合
即便是相同原料经过不同师傅的手艺也会呈现不同的味道

(昨天吃的游寿司)
当资料经过基本筛检後,也会根据後续使用的需求将资料聚合(资料聚合就是将资料从细的颗粒度聚合成比较粗的颗粒)来减小资料的计算量以及储存空间。以 App 收集的使用者行为来说,只要使用者触发事件,就会即时地将资料传回并储存下来,等於说每秒、甚至每几百毫秒就有资料产生,资料量累积下来也非常的庞大。如果一天能产生 100 GB 的资料,那个一个月下来就是 3TB,一年就将近 40 TB 的资料,这样的资料量对於後续的资料分析或使用都会造成相当的麻烦。当後续使用不需要颗粒度那麽细的资料时,就能透过资料聚合能够将资料整理成可以接受的大小。
我们就有以下这个范例资料来讨论资料聚合的两方面:聚合单位以及聚合方式。
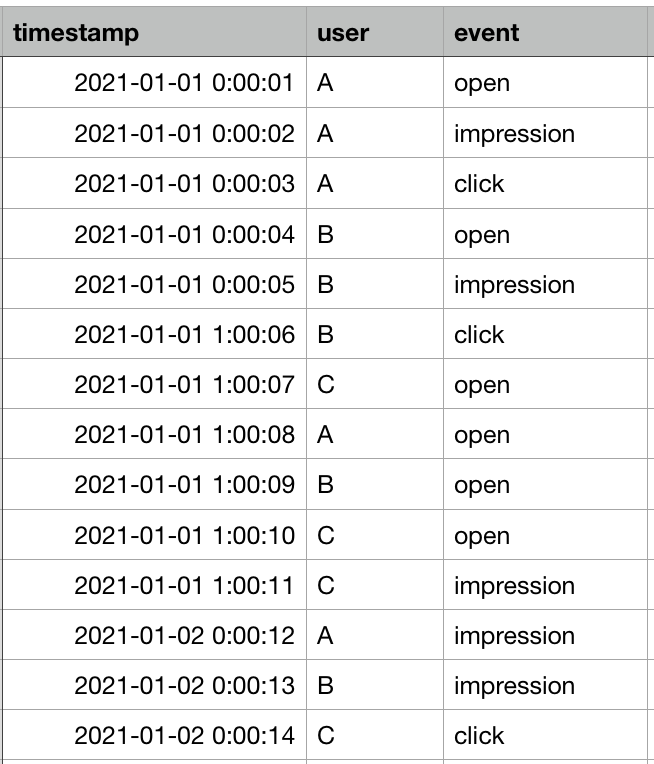
(图1: 原始资料)
常用聚合单位
时间
时间是最常被用来聚合的的单位,根据使用方式,通常可以将时间颗粒度分为几个层面:
- 毫秒 - 最原始的资料产生时间
- 分钟 - 有些不用太即时的监控可以每分钟或每十五分钟搜集一次
- 小时 - 大部分的资料我会小时为单位聚合,如此可以让资料不要太细、又不到太粗,保留後续使用的弹性。
- 天 - 天是最常被使用到时间单位,特别是关於使用者行为的活动,像是每日活跃使用者、每日点击等等。
- 月 - 这大部分就是拿来做月报使用的,千万别只把资料存成那麽粗的时间单位,不然就没办法做更细致的观察了。
地点
搜集使用者资料时常常会包含使用者发出讯号时的位置资讯:
- GPS - GPS 可以很准确的描述使用者的所在位置,当然根据搜集装置的不同也会有些许误差。
- 基地台 - 如果是电信业可以准确知道使用者连到的基地台位置,在都会区甚至可以透过多个基地台精准定位使用者位置。
- Guadkey - 又称为 Bing Map Tile System,透过将地图接成小方块来标示位置,最小的单位可以到达 23 位数,随着使用的位数减少,精度也会下降。
- 乡镇市区/县市/国家 - 最生活化的地点标示方式。
其他常用的聚合单位
只要是觉得细节可以省略的东西,都可以作为聚合单位,这边就列出一些常用的给读者参考。
- 使用者/装置 ID - 同一个使用者在单位时间内做的事情往往也可以聚合在一起。
- 事件类别 - 同上,同个事件在单位时间内做的时间往往也可以聚合。
聚合方式
由於我们是将细的颗粒度整成粗的颗粒度,只能保留部分资讯,因此聚合方式决定了可以保留哪些资讯下来。使用聚合公式的时候需要注意公式是否真的能呈现想表达的意思。
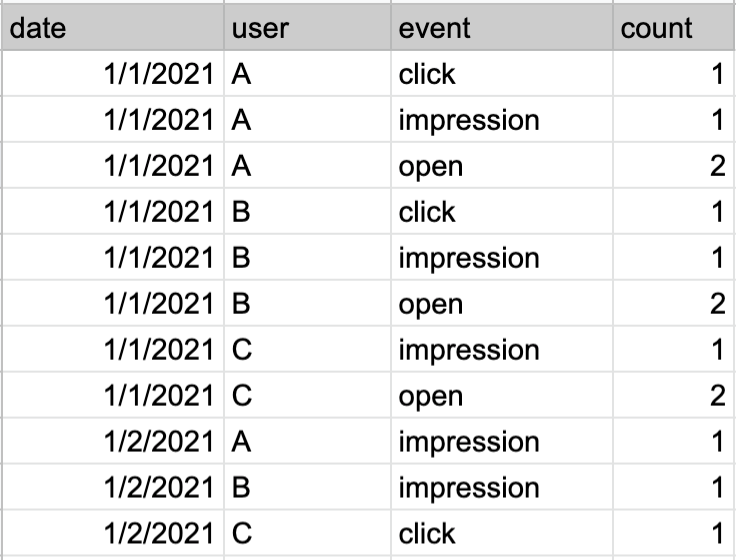
(图2: 聚合後的资料)
count/ distinct count
算个数是最单纯也不太有风险的聚合方式,例如像图 2 的范例资料,就会使用 count 来计算像是 "Open"、"Impression" 等事件数。但是一但被 Count 後的聚合资料如果再次 Count 意义就会变得不同。使用上需要注意。
Sum
如图 2 资料,已经使用 Count 计算每天的事件数了,如果想要计算每月的事件数,就没办法再次直接 Count,需要透过 Sum 的方式将每天已经 Count 後的数字加总。被加总後的数字如果要再做聚合(例如小时 -> 天,天 -> 月)通常可以直接透过加总得到结果。
各种除法(例如平均数、点击率)
不管是哪个颗粒度的资料需要计算这种 XX 率或是平均数,都需要在该颗粒的层次将除法公式还原成分子与分母,然後再进行除法。如果以点击率(Click 数/ Impression 数)为例:
日点击率的公式为:
每日 Click 加总 / 每日 Impression 加总
月点击率的公式为:
每月 Click 数加总 / 每月 Impression 加总
其他常用聚合公式
- 最大值/ 最小值:很常用来作为检查资料有没有异常的聚合公式,建议只要有搜集数值型的资料就要计算最大最小值。
- 中位数:第 50% 位数,可以知道资料分布的中点。
- 第 n 分位数:可以知道资料的分布状况。
- 标准差:也是用来检查资料分布的状况,由於标准差的公式更复杂,使用上需要多加留意
References
https://www.ibm.com/docs/en/tnpm/1.4.2?topic=data-aggregation
https://www.import.io/post/what-is-data-aggregation-industry-examples/
https://improvado.io/blog/what-is-data-aggregation
https://www.jigsawacademy.com/blogs/data-science/data-aggregation/
<<: MLOps 带给商业与技术流程的5个好处与13个指标 | MLOps落地指南 - 流程篇
Station list screen (2)
上一篇我们完成了 StationListAdapter,我们现在会继续车站列表的 UI 部分。 St...
Golang快速入门-2(Day5)
那就接续着昨天的内容,今天提到的也是大家常用的function及slice function go在...
Day 14 - 函数与物件互动 - 制作蜜蜂靠近花朵
function 函数 为什麽要用函数:函数可以把需要重复执行的行为打包,在需要使用的时候直接使用函...
Day 10 运算宝石:EC2 储存资源 Instance Store vs Elastic Block Storage (EBS)
现在我们来介绍 EC2 里面的 Instance Storage 与 EBS 的差别,那我们开始吧...
Powershell 入门之函数
前面,我们已经知道了,如何去编写 powershell 脚本,今天我们就一起来看看,其他的功能。通过...