[Day 5] lock-free stack
前言
今天将会实作资料结构 stack , 之所以选择 stack 是因为其制作简单, 可以让读者轻松的理解 CAS 在其中扮演的脚色。
node: ( 协助理解下方程序码 )
class node {
public:
node* next;
int value;
node(int value) {
this->value = value;
next = nullptr;
}
};
一般 stack
core code : (push node and pop node from stack)
void pushNode(int value) {
// 创建节点
node* n = new node(value);
// 把节点的下一个, 设为目前的第一个节点
n->next = head;
// 把新节点设定为第一个节点
head = n;
}
void popNode() {
start:
if (head == nullptr)
goto start; //一定要删到, 不放弃
// 把第一个节点设定成第一个节点的下一个节点。
head = head->next;
// 注: 此处仅逻辑上删除, 并没有删除其所占用记忆体。
}
利用以上的资料结构可以发现, 在仅有一条 thread 时会顺利运作, 但当有多条 thread 同时操作时会因为 race condition 出现问题。 常见问题如下 :
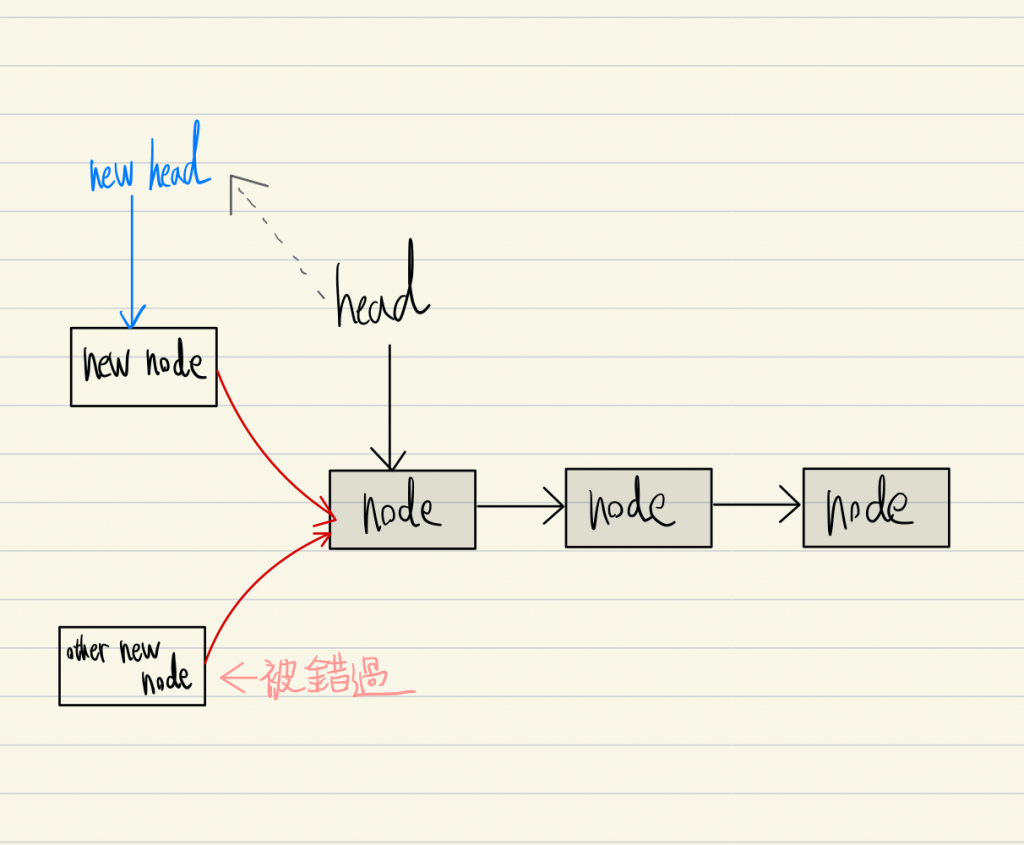
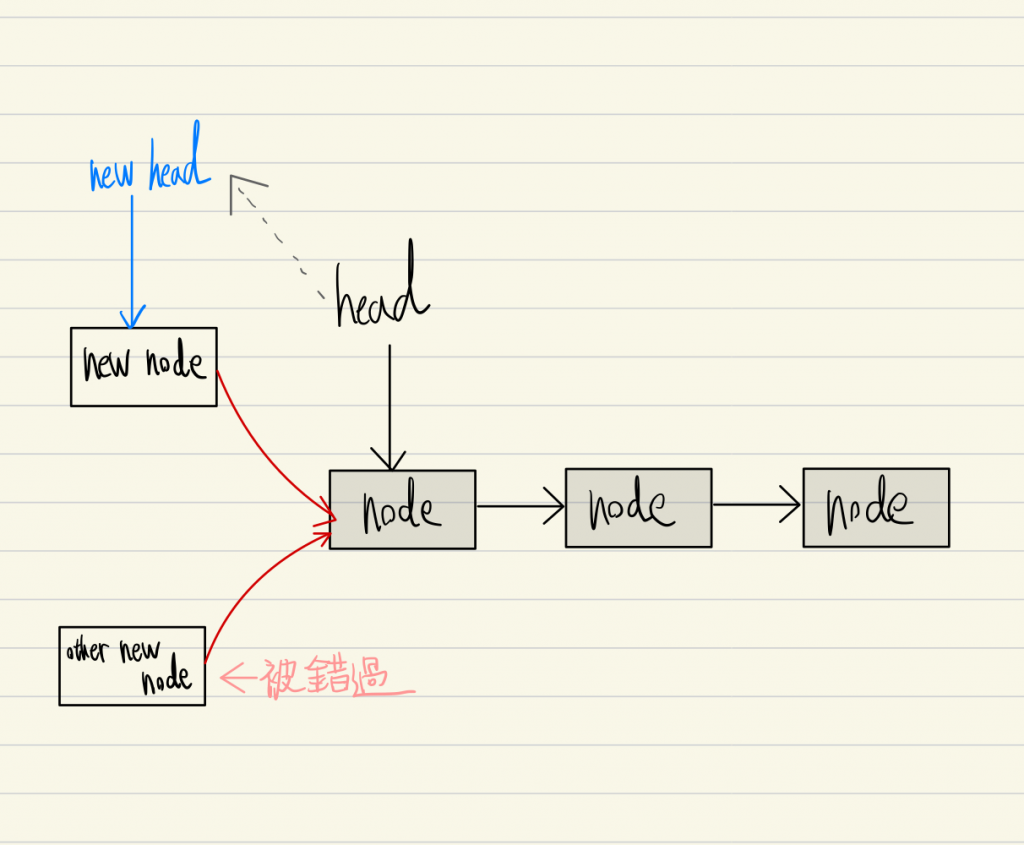
- 创建时, "把新节点设定为第一个节点"时, 却有另一条 thread 也创建了新节点, 并且接在了原来第一个节点的前面, 导致操作"把新节点设定为第一个节点"直接跨过了那颗节点。
- 删除时, 确定有节点才删除, 但当一条 thread 确定有节点, 正要删除节点时, 另一条 thread 把节点删光光, 就会导致 thread 删除以被删除的节点, 抱错。
因此我们必须使用阻塞机制来确保, 在 multi-thread 操作时的正确顺序。
lock 版 stack
void pushNode(int value) {
node* n = new node(value);
glock.lock(); // 加 mutex lock
n->next = head;
head = n;
glock.unlock(); // 解 mutex lock
}
void popNode() {
start:
if (head == nullptr)
goto start; //一定要删到, 不放弃
glock.lock();
head = head->next;
glock.unlock();
}
没什麽好说的, 直接强迫同时只会有一条 thread run 在 critical section
但会导致我昨天提到的, 阻塞式同步机制的问题 ( 响应时间也会被阻塞, 可能在例外情况 deadlock )。
lock-free stack
利用非阻塞式同步机制实作的stack, 且具有 lock-free 的特色。
api 参考
void pushNode(int value) {
node* n = new node(value);
do {
// 设定新节点的下一个节点是目前的第一个节点
n->next = head.load();
} while (!head.compare_exchange_weak(n->next, n));
/*
* 若 head == n -> next 就令 head = n
* 若 head != n , 改令 n -> next = head 然後做下一轮, 做到一样为止
*/
}
void popNode() {
start:
node* curHead = head.load();
do {
if (curHead == nullptr)
goto start; //一定要删到, 不放弃
} while (!head.compare_exchange_weak(curHead, curHead->next));
// 如果我们要移除的节点, 现在还是首节点, 那就执行移除。否则重作。
}
回到这张图的情况, 当一条 thread 在添加节点的过程中, 另一条 thread 就添加了别的节点, 要怎麽不错过节点呢 ?
以上程序码是怎麽做到的~~~
原来当他想要把, head 移动到 new node 时, 会检查 head 是否还在 new node 的下一个, 如果是, 才会移动 head 指标 (而且 CAS 指令确保了检查和移动 head 指标是不可中断的, 所以此情况必然成立)
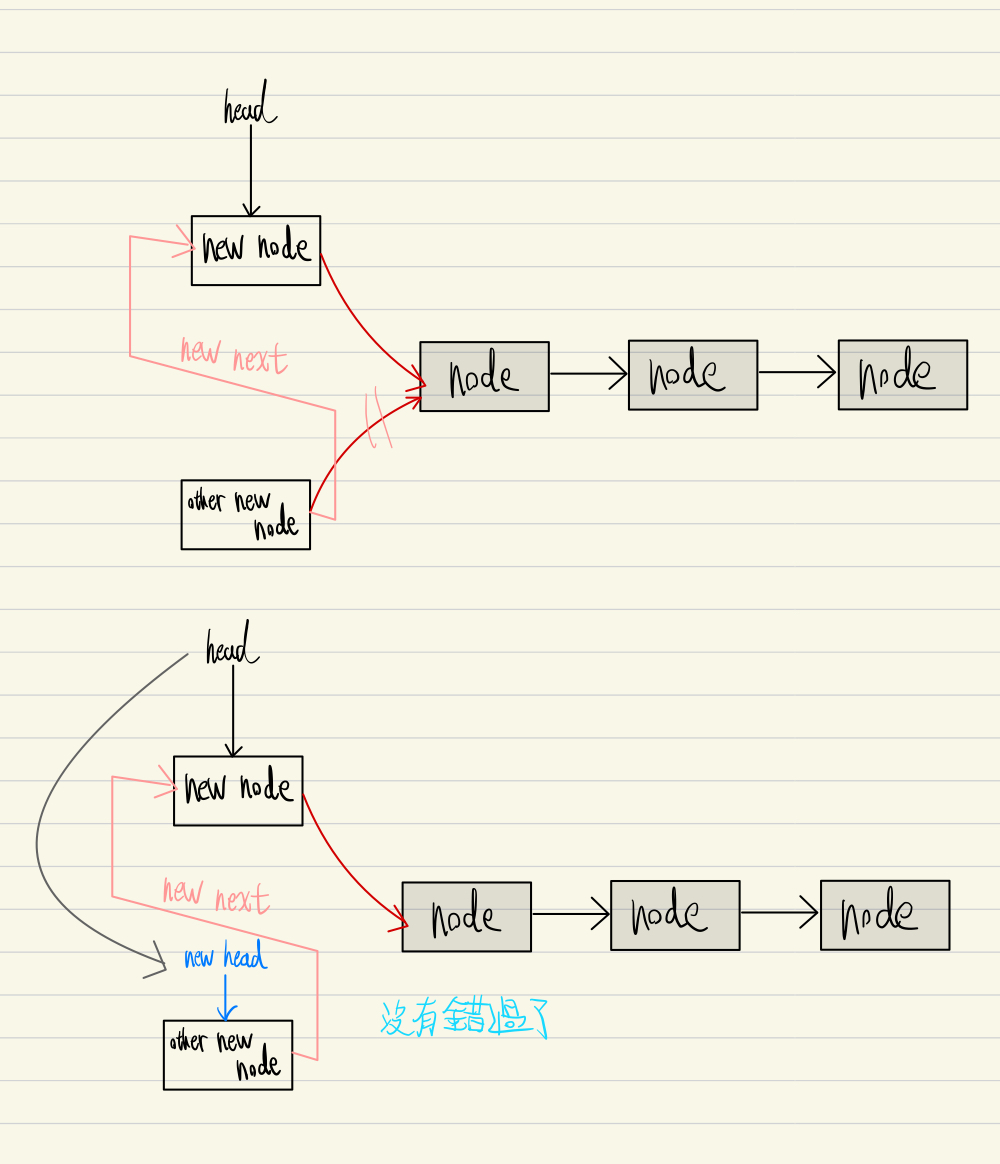
接着我们继续看 other new node 目前已经被错过, 要怎麽被加回 stack 中
第一张图是检查自己 ( other new node ) 的下一个节点是不是第一个节点 (head) , 发现不是, 所以把自己的下一个节点设为 new node (目前的第一个节点) ,这段检查与更改的过程也是 CAS 。 之後因为更改失败进入下一个循环。
第二张图, other new node 检查得知下一个节点确实是 head ( 第一个节点 ) , 所以移动 head 指标完成节点的添加。
至於另一种 race condition 比较好理解, 我就不描述了。
概念统整
可以发现, 在 lock-free stack 我们必须假设到所有可能的 race condition 情况, 之後利用 CAS 设计某种机制来解决这些情况。以我个人的感觉, 在设计演算法时要把可以独立先做的事情先完成, 最後利用 CAS 把不能接受中断的事完成。
但事实上在这篇教学里我并没有列出所有 race condition 情况, 我只说了
- push 的过程发生 push
- pop 的过程发生 pop
其实 还有
- push 的过程 pop
- pop 的过程 push
甚至还有
ABA 问题这种 push 过程产生 pop pop push 等状况。
不过因为这支范例程序的测试没有很极端, 所以我并没有考虑所有的 race condition , 但其确实已经解决大多数的 race condition 了, 大家可以试着画图模拟各种情况, 再试着用这个 CAS 演算法跑跑看能不能解决。
最後说一下, 我个人觉得像 stack 这类简单的资料结构要 lock-free 靠自己的大脑还可以, 但更难的我建议直接去抄 paper 比较实在。
明天进度
基本的 CAS lock-free 说完了, 我明天开始打算带大家一起读 .NET 的非同步方法 Task.WhenAll , 让大家看看框架里面实践非同步方法的作法。
<<: [Day-5] R语言 - 分群前处理 ( Clustering Preprocessing )
通过SafariViewController查询网站 Day22
今天作为使用SFSafariViewController作为载入画面 其实这个使用非常的简单 只有两...
30天学会Python: Day 26-一心多用
同步执行 目前写的程序都是一行接着一行一行执行,这种执行的方式叫做 同步执行 print("...
机器学习:建模方法
机器学习的核心流程包括了业务洞察(Business Insight)、资料处里(Data Curat...
Day11 AR安全帽 边骑车边滑手机(用声音) 给不想要乖乖骑车的你(前提是够有钱)
在前面讲了各种显示技术的爱恨情仇,今天要来介绍投影显示的技术,在AR方面,需要投影的就是抬头显示器(...
第4天~点餐系统
2022/1/19再练习一次: 改最上面标题的地方: 使用按钮ToggleButton和Switch...