[Day4] 语言模型(一)-N-gram
一. 何谓语言模型
断完词後,我们希望可以用这些词做什麽呢?用途很多,但大部分的情况基本上是希望训练一个模型,这个模型可以了解文章、句子等语意的关系,这也就是语言模型,可以推论出文义通顺、有意义的句子或文章,例如:
今天天气_,人类知道这个空格应该有可能是’晴’这个字或是形容天气状况的词。
语言模型就是希望可以推理出上面的空格的词,所以假如目前有'晴'、'帅'、'我' 这三个词的话,照理来说'今天天气_'与这三个词的机率相乘,'晴'这个词的机率应该要最大。目前的语言模型就是根据其他字词来判断当前自出现的机率,因此便可以藉由机率大小的方式来判断句子出现可能性。
二. N-gram
这边主要是讲N-gram的model,计算方式如下,假设今天语料库有5个句子(已断过词):
这是 一只 猫
这是 一只 猫
今天 天气 不错
这是 一只 狗
晚餐 吃 咖哩 饭
计算P(猫|‘这是’, ‘一只’) = count(‘这是’ + ‘一只’ + ‘猫’)/count(‘这是’ + ‘一只’) = 2/3
像上面这个例子是看前面2个字来预测接下来的字,称为 tri-gram,因为一次看3个词,以此类推,若只看前面一个词来预测下个词这样称为bi-gram,单纯看词在语料库出现的机率,称为uni-gram。
没错,N-gram就是基於统计的语言模型算法,就是将文本/句子中的内容取最靠近的 N 个字当作条件机率计算,形成长度是 N 的字词,如上述的tri-gram,用前两个词预测下一个词,所以他一次看了3(N)个词,而这边的每个字词称为 gram。
三. N-gram的由来
其实最一开始的时候,语言模型是利用贝氏机率来计算一个句字生成的机率大不大,如下,若要表示一个句字的S的机率大小会表示如下:
P(S) = p(w1)p(w2|w1)p(w3|w1w2)...*p(wn|w1w2w3…)
第一个词是w1乘上(在w1出现的前提下w2出现的机率),这样依此类推相乘,但这样做太费时,耗费计算的空间,因此才导入了马可夫模型的概念,来简化计算过程,马可夫的概念就是下一个状态的机率由当前状态决定,所以才产生了N-gram的模型。
列一下uni-gram、bi-gram与tri-gram的计算方法,以上述计算句字的S的机率为例,会表示如下:
- uni-gram:
P(S) = p(w1)p(w2)p(w3)...*p(wn) - bi-gram:
P(S) = p(w1)p(w2|w1)p(w3|w2)...*p(wn|w[n-1]) - tri-gram:
P(S) = p(w1)p(w2|w1)p(w3|w2, w1)...*p(wn|w[n-1], w[n-2])
透过马可夫的假设,就不需要考虑到句子中所有字词的时间序列,大幅减低运算成本。
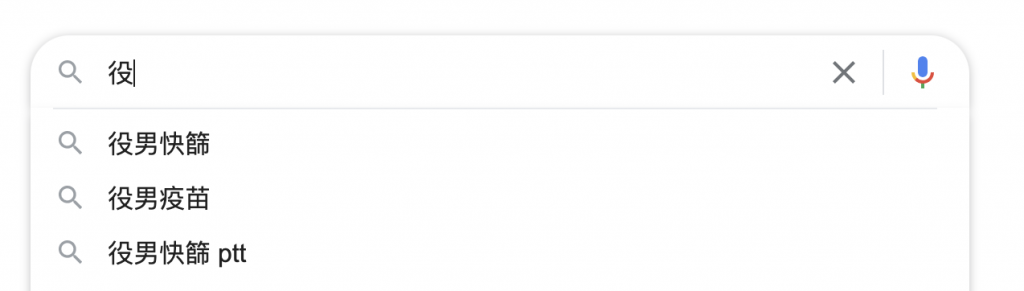
N-gram在错别词、预测词上都有不错的应用喔~~像下图就是google的预测词,这是可以利用简单的N-gram模型可以做到的,但google是不是用这个演算法不清楚XD
今天大致说明了一下N-gram的原理~明天要开始用python来实战N-gram模型了,会试着实作'预测词'的模型~
参考资讯
[1] 基于jieba中文分词进行N-Gram
[2] NLP 中文拼写检测纠正算法整理
<<: 从 JavaScript 角度学 Python(3) - 安装
Day 30: 遗漏的章节
「目前为止,所有建议无疑将帮助你设计出更好的软件,这些软件是由具有明确边界、职责、依赖关系受控的元...
AE骇客萤幕打字效果3-Day12
接续昨天的练习 1.新增一个Adjustment Layer 2.套上Optics Compensa...
30天程序语言研究
今天是30天程序语言研究的第四天,研究的语言是python,今天主要学习的部分是tuple和func...
Day 13:因应在地口味调整,根据各平台实作功能!
Keyword: expect/actual 有的时候,在不同平台上,功能的实作有平台上的限制,而这...
[Python 爬虫这样学,一定是大拇指拉!] DAY13 - HTTP / HTTPS (4)
本篇主要讲解 HTTP 状态码代表的意思。 主要是针对状态码的类别做讲解,所以不用担心会太多。且并不...