AI ninja project [day 3] AI RPA系统--名片前处理篇
当开始与许多厂商联系,
认识了越来越多人,
自然而然会累积许多名片。
要是未来希望能搜寻特定厂商的特定联络人呢?
我们可以在一开始拿到名片的时候,
就将名片上的资讯进行萃取,
并且依照辨识到的字串,依据字串内容预测其可能的栏位,
写入excel表格或是资料库。
这里采用监督式学习演算法,
我们大约需要自己标注20张名片的资料集。
我们使用上一篇文章所使用的google client vision程序来进行处理,
# !/usr/bin/python
# coding:utf-8
from google.cloud import vision
import io
import os
import glob
credential_path = "cred.json"
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path
client = vision.ImageAnnotatorClient()
def extract_txt(file_path):
with io.open(file_path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
return texts[0].description
for filepath in glob.iglob('*.png'):
print(filepath)
extract_str = extract_txt(filepath)
new_txt_file_name =filepath[0:-4] + '.txt'
new_txt_file_path = os.path.join('./txt_file',new_txt_file_name)
with open(new_txt_file_path, 'w', encoding='UTF-8') as f:
f.write(extract_str)
为了节省成本,图片转成文字的过程只进行一次,
我们将文字资讯存成txt档案,以利於往後处理。
接着对文字档案进行操作:
import glob
import csv
replace_string_list = [':',',','"',"'",' ','地址','email','电话','手机','tel','传真','职称','姓名','统一编号','LINE','line']
for filepath in glob.iglob('*.txt'):
# print(filepath)
with open(filepath, 'r' , encoding='UTF-8') as f:
content = f.read()
print(content)
for replace_string in replace_string_list:
content=content.replace(replace_string,'')
with open('train.csv', 'a+' , encoding='UTF-8') as csvfile:
fieldnames = ['content','label']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
content_list = content.split('\n')
for content_ele in content_list:
writer.writerow({'content': content_ele, 'label': ''})
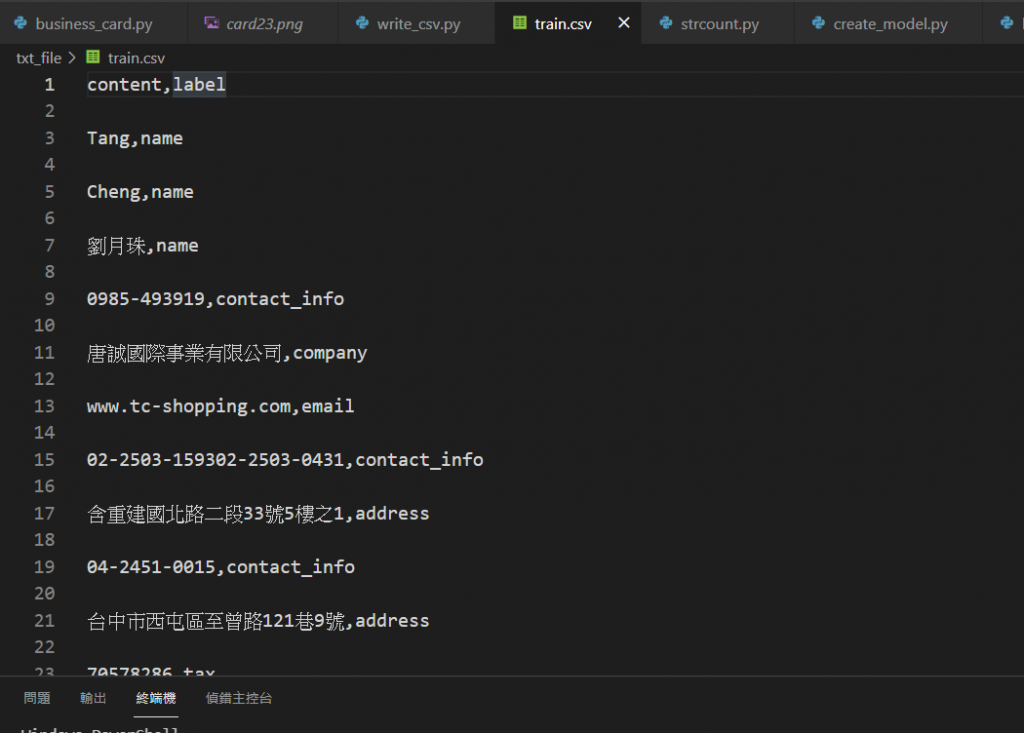
剔除一些未来会影响字串预测的文字(可依据模型表现新增或修改),
我们将资料写於csv,
自行进行标注以及加上Index。
明天再进行文字特徵提取,建模以及预测。
[Day30] Room的坑只好自己补
Caused by: java.lang.IllegalStateException: Canno...
新新新手阅读 Angular 文件 - ngStyle - Day16
本文内容 本篇内容为阅读官方文件 ngStyle 的笔记内容。 ngStyle 使用时机 昨天 Da...
蓝牙小知识
名称的由来 Bluetooth是斯堪地那维亚语言的Blåtand/Blåtann 借10世纪丹麦和...
day30 : 写不完所有东西的最後一天
30天的最後一天,写到最後几天才发现有一些想分享的没有篇幅能写入了,所以今天我认为分享的内容偏实用的...
30天学会Python: Day 23-交换数值
要交换两个变数的值,在 Python 有几种写法 可以先另外建立一个变数,再互相指派,假设输入的数值...