使用 TorchServe 部署 Model
TorchServe
TorchServe 是 PyTorch 提供给开发者部署 models 的工具(实验阶段)。也就是说开发者不用再写 HTTP 服务去部署,直接使用TorchServe 工具就可以了!
系统架构
TorchServe 主要提供两个 API:Management API 是用来设定 TorchServe 服务,如注册新的 Model 服务、卸载 Model 服务,监看 TorchServe 的状态;Inference API 用来取得辨识结果。
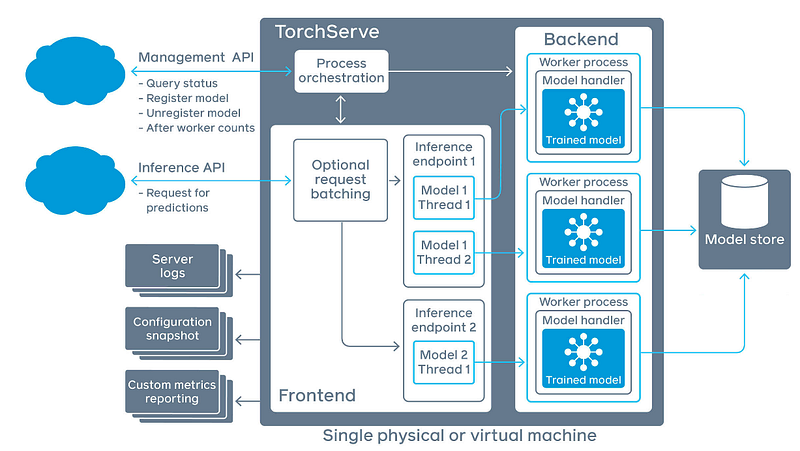
- Frontend:指的是 request batching + Inference API Handler。request batching是由 Management API 设定;Inference API Handler 则是由开发者自行撰写
- Worker Process:指的是一组辨识程序的运行(trained model + model handler),概念像是 Thread,可由 Management API 进行设定运行的数量。
- Model Store:透过 TorchServe 工具压缩後的 model package。
- Backend:指的是管理 Worker Process 的程序,由 Management API 让使用者管理。
使用指南
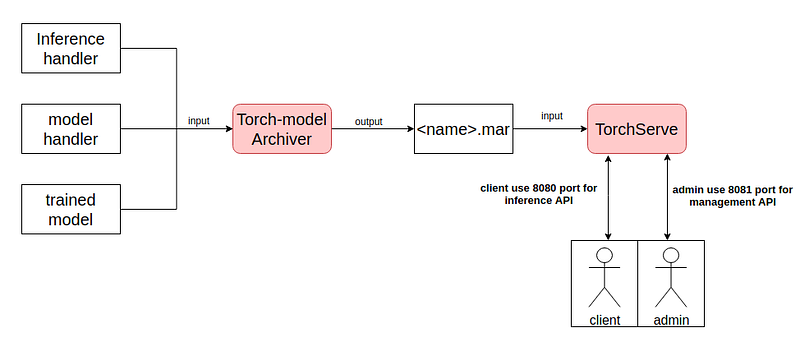
使用 TorchServe 需要准备三个档案:Trained Model、Inference handler 、model Handler,将这三个东西使用 TorchServe Archiver 将其压缩成 .mar 档案。最後将 .mar 档放入 TorchServe 里,注册後就布署!
TorchServe 预设 8080 port 用於 inference ; 8081 port 用於管理 TorchServe 如下图:
- 开始之前必须先安装 TorchServe、torch-model-archiver,一个是用来跑TorchServe服务的,另一个是用来压缩 Trained Model、Inference handler 、model Handler 的套件。
- 使用 torch-model-archiver 进行压缩,会得到densenet161.mar档案,
- 最後将该档案注册进去 TorchServe 就可以使用了。
指令如下:
pip install torchserve torch-model-archiver # 安装必要套件
git clone https://github.com/pytorch/serve.git # clone example
cd serve/examples/image_classifier/ # 进入image_classifier example
cp index_to_name.json densenet_161/ #
cd densenet_161/
# 若无预设输出资料夹,则创建一个
if [ ! -d "model-store" ]; then
echo "creates new folder: " $export_path
mkdir $export_path
fi
#下载trained model
wget https://download.pytorch.org/models/densenet161-8d451a50.pth
#压缩densenet161范例 -> densenet161.mar
torch-model-archiver --model-name densenet161 --version 1.0 --model-file model.py \
--serialized-file densenet161-8d451a50.pth --handler image_classifier \
--extra-files index_to_name.json --export-path="model-store"
torchserve --start --model-store model-store/ --models densenet161.mar # 注册densenet1611并启动torchserve
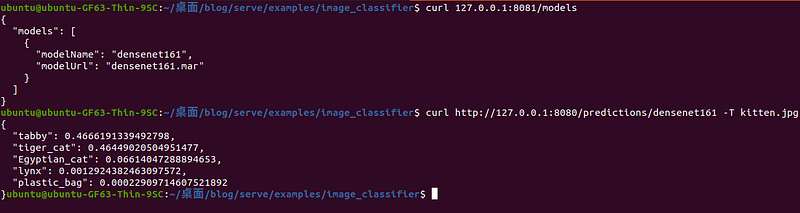
可以使用 curl 进行验证是否抓到 densenet161 model,并试着传一张图看看是否有成功运行。
example:查看TorchServe 的状态、并传送一张图片取得结果。 如下程序码:
curl 127.0.0.1:8081/models
curl http://127.0.0.1:8080/predictions/densenet161 -T kitten.jpg
执行结果:
Debug 经验谈
TorchServe 是一个非常新的部署工具,debug 不知道如何 debug,用起来真的很崩溃。其实一开始压缩的 .mar 档,TorchServe 抓到之後会将其解压缩至 /tmp 中。如下图:

densenet161资料夹下,具有TorchServe中需要的档案:

因此当想要进行 debug 的时候,要切到 /tmp 资料夹中使用 python3 指令执行,如果没问题,理论上 TorchServe 就能够成功运作。
常用Management API 介绍
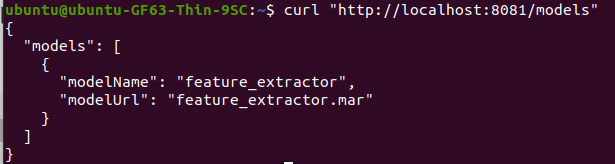
在这边分享一些过去部署TorchServe常用用的一些API,首先在注册的时候会不知道目前到底有没有抓到Trained model?这时候可以使用List models API
example: 列出所有运行中的models,如下程序码
curl "http://localhost:8081/models"
执行结果:
此外就是考虑到效能面的话,或许有需要修改某一个model的Worker Process数量这种需求,也可利用PUT对某一个model修改Worker Process的数量。example: 将worker 数量设定为3个,如下程序码:
curl -v -X PUT "http://localhost:8081/models/<modelname>?min_worker=3"
就已feature_extractor这个model为例:
- 首先先看一下model的资讯:
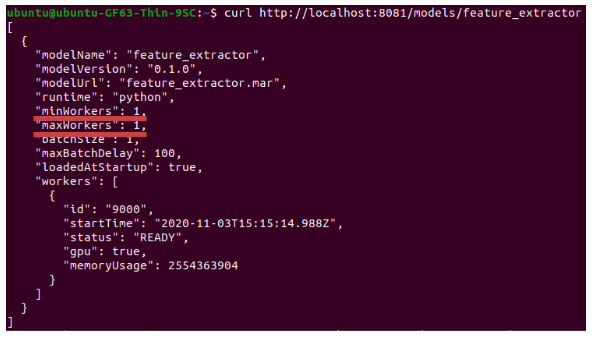
- 修改worker 数量:
# 进行修改之後
curl -v -X PUT “http://localhost:8081/models/feature_extractor?min_worker=3"
- 执行结果,查看model资讯:
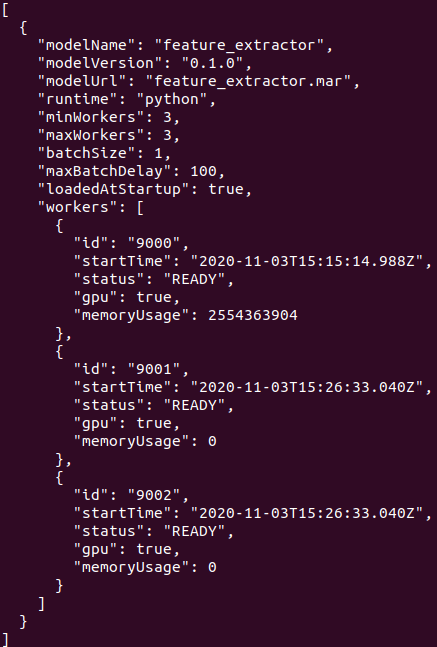
Inference handler撰写经验谈
inference handler文件相当的简洁,在撰写handler的时候可参考下面程序码,大致上每个区块的function要杜撰什麽都记载注解上。此外撰写完,注册进去TorchServe後要能够在/tmp中找到,同时是可直接执行的状态,若不是则需要继续debug。
Debug有雷请小心:
- 输出只吃JSON格式
- batch size 大小(如果batch size 为1,JSON List数量只能是1)
class ModelHandler(BaseHandler):
def __init__(self):
self._context = None
self.initialized = False
# 用於load trained model 的地方,以及其他设定档
def initialize(self, context):
self._context = context
self.initialized = True
# load the model, refer 'custom handler class' above for details
# 用於predictions的时候,接收http post request的function: 预设接收key为data的资料
def preprocess(self, data):
# Take the input data and make it inference ready
preprocessed_data = data[0].get("data")
if preprocessed_data is None:
preprocessed_data = data[0].get("body")
return preprocessed_data
# 用来进行运算的function,最後的结果会交由postprocess()後处理
def inference(self, model_input):
# Do some inference call to engine here and return output
model_output = self.model.forward(model_input)
return model_output
# 指的是发送post:inference()之後的结果
def postprocess(self, inference_output):
postprocess_output = inference_output
return postprocess_output
def handle(self, data, context):
model_input = self.preprocess(data)
model_output = self.inference(model_input)
return self.postprocess(model_output)
虽然预设输出是JSON,打request进去的资料格式没有规定喔,可利用像是protocol buffers这种技术进行传递是没有问题的!
batchsize 修改方法:
curl -v -X PUT "http://localhost:8081/models/?batch_size="
<<: 【JavaScript】在JavaScript中使用switch(true)
>>: 伸缩自如的Flask [day2] blue_print
Day 21 - SwiftUI开发学习5(文字填入)
今天我们来学习如何使用填入文字的物件 正文 文字填入 TextField 可以将文字填入进去。 如果...
[Day22] Follow Along Links
[Day22] Follow Along Links 需要用到的技巧与练习目标 1.getBound...
Encapsulation
本篇同步发文於个人网站: Encapsulation This article references...
[Tableau Public] day 30:数据领域工作所需要的技能
我们前面所练习的资料视觉化在数据领域中比较偏向後段的工作。 一个完整的数据分析专案(数据团队)包括了...
《Day28》Oracle Database的基础架构
Oracle Database主要由实体档案与记忆体结构配置组合而成的。 可以参考下图: 介绍Ora...