Day 28 - 建立自己的K线资料库 (下)
本篇重点
- 建立Index,加快SQLite存取速率
- 产生日K线资料
- 产生周K线资料
- 产生月K线资料
建立Index,加快SQLite存取速率
在产生日K、周K和月K资料之前,我们先将原本的SQLite资料库,加上Index索引,以加快SQLite的存取速度。虽然建立Index会让DB档案大小变大,但却可以让资料库的存取效率大大提升。
若要在SQLite中,建立Index可以透过两种方式,第一个方式是用之前介绍的DB Browser for SQLite来建立Index
首先,执行DB Browser for SQLite并打开资料库後,按「Create Index」
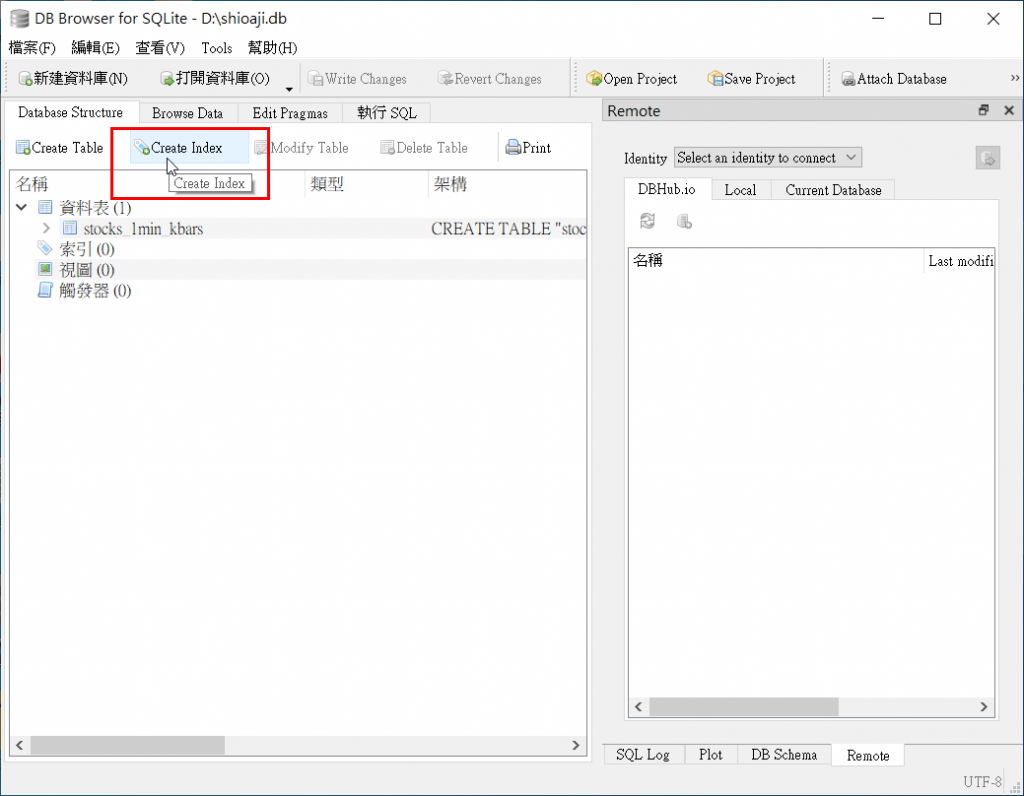
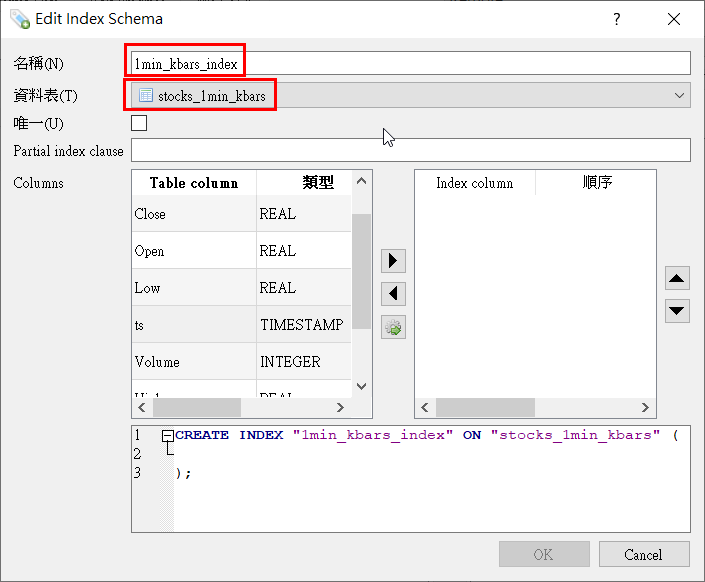
名称请自行定义,而资料表则选择你是要替哪个资料表建立索引,这里我们选择之前建立的1分K「stocks_1min_kbars」
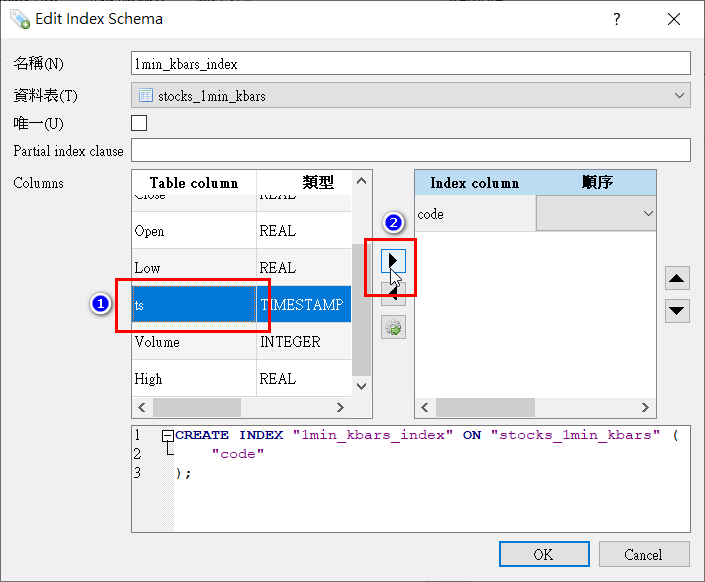
接着,选择所要建立索引的栏位,选择後请点「▶」按钮将该栏位新增至右侧的Index Column
这里我是选择建立code及ts这两个栏位的索引,确认後按下「OK」後,DB Browser for SQLite就会开始建立索引内容,此过程可能会因为资料量大而花上一点时间,请耐心等侯
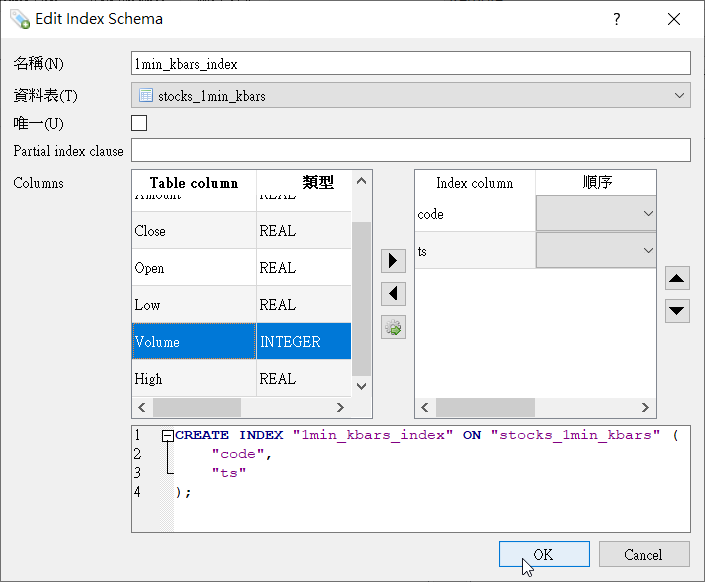
Index建立完成後,请按「Write Changes」,将刚才做的修改写入资料库中。
建立Index後shioaji.db档案大小由7.35GB变为10.8GB,我跑了下列三档股票的1分K转5分K,并比较建立Index前後,执行pd.read_sql所需的时间(单位:秒)。可以看到读取时间有大幅的减少。
| 股票 | 未建立Index,read_sql执行时间 | 建立Index後,read_sql执行时间 |
|---|---|---|
| 2330 | 94.51796960830688 | 0.5804615020751953 |
| 2890 | 15.362500667572021 | 0.5675475597381592 |
| 2890 | 15.250365018844604 | 0.5844612121582031 |
产生日K线资料
上面有提到,在SQLite可以手动建立Index来增加存取效率,除了上述的手动建立外,也可以透过pandas写入资料时一并建立。我们以产生日K线资料为例,程序内容如下
import pandas as pd
import sqlite3
import time
conn = sqlite3.connect('D:/shioaji.db') #建立资料库连线
# 传入股票代码,产生日K资料并存至资料库
def generate_1day_kbar(stock_code):
print(f'generate 1dayK for stock:{stock_code}')
# index_col,产生DataFrame後将index设定为ts栏位
df = pd.read_sql(f'SELECT code, Open, High, Low, Close, Volume, ts FROM stocks_1min_kbars WHERE code = {stock_code}', conn, parse_dates=['ts'], index_col=['ts'])
# rule设为1D,表示resample为一天的资料
df_1day_kbar = df.resample(rule='1D').agg({
'code': 'first',
'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
df_1day_kbar.dropna(axis=0, inplace=True)
df_1day_kbar.reset_index(inplace=True) #重设index
df_1day_kbar.set_index(['code', 'ts'], inplace=True) #重新将Index指定为code、ts
df_1day_kbar.to_sql('stocks_1day_kbars', conn, if_exists='append')
print(f'stock:{stock_code}, 1dayK is added to DB...')
cursor = conn.cursor()
for code in cursor.execute('SELECT DISTINCT code FROM stocks_1min_kbars'):
generate_1day_kbar(code[0])
conn.close() #关闭资料库连线
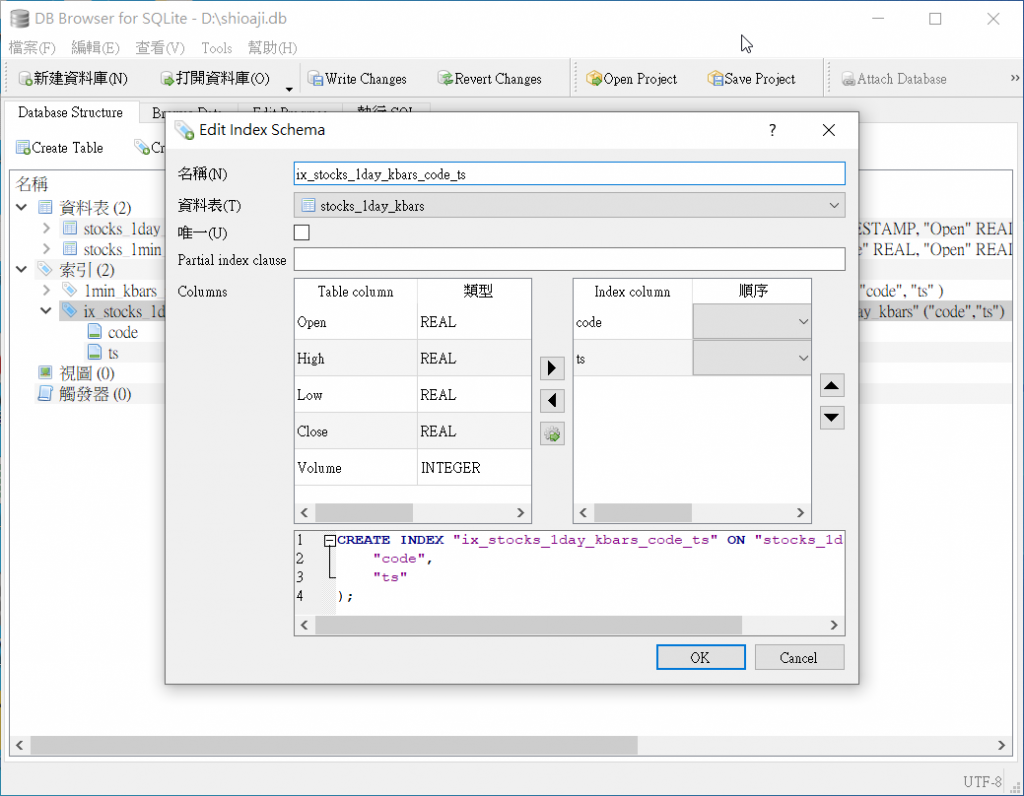
上面的程序中,我们在resample後先执行reset_index(),然後再次执行set_index,并将code及ts栏位传入,这样在执行to_sql时,pandas在建立资料库table时,就会一并建立索引Index,执行DB Browser for SQLite并打开资料库,就可以看到SQLite中已建立对应的Index。
产生周K线资料
若产生日K线资料,接着产生周K时,就可以直接抓stocks_1day_kbars中的资料去做处理。程序范例如下:
import pandas as pd
import sqlite3
conn = sqlite3.connect('D:/shioaji.db') #建立资料库连线
# 传入股票代码,产生周K资料并存至资料库
def generate_week_kbar(stock_code):
print(f'generate 1dayK for stock:{stock_code}')
df = pd.read_sql(f'SELECT code, Open, High, Low, Close, Volume, ts FROM stocks_1day_kbars WHERE code = {stock_code}', conn, parse_dates=['ts'], index_col='ts')
# resample并指定每周的最後一天为周五Friday
df_week_kbar = df.resample(rule='W-FRI').agg({
'code': 'first',
'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
df_week_kbar.dropna(axis=0, inplace=True)
df_week_kbar.reset_index(inplace=True)
df_week_kbar.set_index(['code', 'ts'], inplace=True)
df_week_kbar.to_sql('stocks_week_kbars', conn, if_exists='append')
print(f'stock:{stock_code}, weeK is added to DB...')
cursor = conn.cursor()
for code in cursor.execute('SELECT DISTINCT code FROM stocks_1min_kbars'):
generate_week_kbar(code[0])
conn.close() #关闭资料库连线
产生月K线资料
产生月K线的资料,程序范例如下:
import pandas as pd
import sqlite3
conn = sqlite3.connect('D:/shioaji.db') #建立资料库连线
# 传入股票代码,产生5分K资料并存至资料库
def generate_month_kbar(stock_code):
print(f'generate month kbar for stock:{stock_code}')
df = pd.read_sql(f'SELECT code, Open, High, Low, Close, Volume, ts FROM stocks_1day_kbars WHERE code = {stock_code}', conn, parse_dates=['ts'], index_col='ts')
# rule指定为月
df_month_kbar = df.resample(rule='M').agg({
'code': 'first',
'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
df_month_kbar.reset_index(inplace=True)
df_month_kbar.set_index(['code', 'ts'], inplace=True)
df_month_kbar.to_sql('stocks_month_kbars', conn, if_exists='append')
print(f'stock:{stock_code}, month kbar is added to DB...')
cursor = conn.cursor()
for code in cursor.execute('SELECT DISTINCT code FROM stocks_1min_kbars'):
generate_month_kbar(code[0])
conn.close() #关闭资料库连线
[Day28] 沟通之术 - 测试工程师篇
这是铁人赛接近尾声的倒数第 3 篇~今天就来讲讲跟测试工程师的沟通之术吧! 前言 原本是个坐在位置上...
Day13 | Dart 中的 Functional Programming
Functional Programming 如果OOP是以物件为主那FP就是以Function作为...
IT 铁人赛 k8s 入门30天 day26 k8s Task Set up Ingress on Minikube with the NGINX Ingress Controller
前言 参考文件: https://kubernetes.io/docs/tasks/access-a...
QUIC.cloud CDN 与 DNS 新手教学
环境准备 安装 LiteSpeed Cache plugin 取得 Domain Key 开启套件...
[Day30] 完赛结语
第 30 天当然要写个铁人完赛心得啦~ 这是我第一次参加 IT 铁人赛,赶在最後一天报名隔日开赛,刚...