实战练习 - 使用 RxJS 实作「自动完成 / 搜寻 / 排序 / 分页」功能
今天我们用实际的例子来练习各种 RxJS operators 的组合运用!在一般的应用程序里面,资料查询应该算是非常常见的情境了,我们就实际使用资料查询的功能做范例,加上各种变化,来练习一些 operators 的实际使用吧!
起始专案
由於我们主要的练习目标是 RxJS,因此许多关於画面操作的部分,都已经先设计好了,可以到以下网址以起始专案开始练习:
https://stackblitz.com/edit/mastering-rxjs-practice-search-starter
如果想要跟着练习,建议可以 fork 一份到自己的帐号下,以後可以随时回来看成果。
练习过程中,也可以参考完整版程序码:
https://stackblitz.com/edit/mastering-rxjs-practice-search-finished
预期功能及画面
在这个专案中,我们要练习使用 GitHub Search API 来依照指定的名称搜寻 repositories,预期完成画面如下:
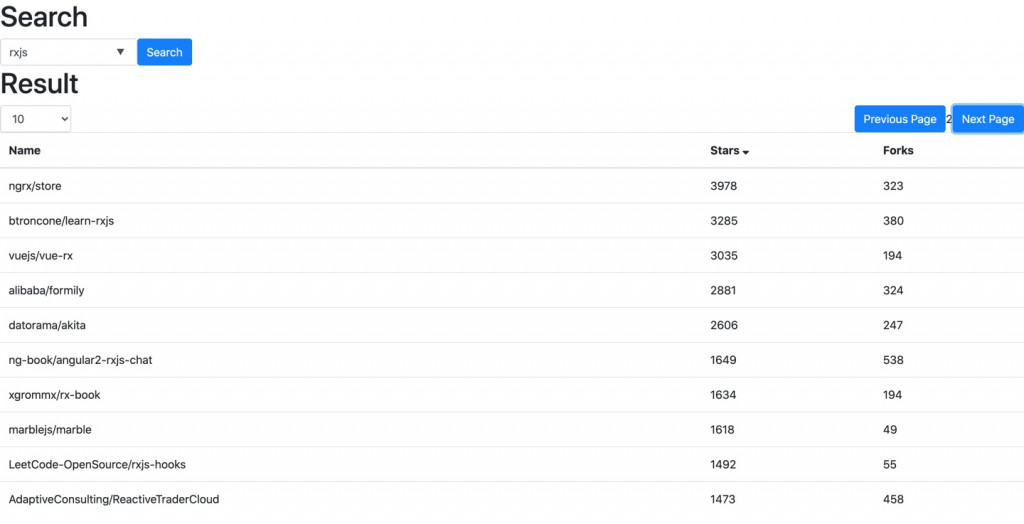
包含一些基本功能:
- 依照关键字搜寻 GitHub repositories
- 分页功能,包含每页几笔及显示第几页
- 排序功能,可依照 stars 或 forks 进行排序
另外还包含了搜寻时的「自动完成」功能:
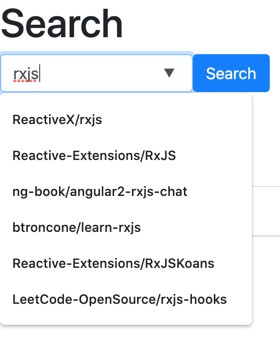
当输入文字时,可以提供符合文字的 repositories 建议。
相关档案
在起始专案的 index.html 内已经把基本的 HTML 都写好了,另外在 index.ts 内也预先 import 已经写好的操作逻辑
// 画面上的 DOM 物件操作程序
import * as domUtils from './dom-utils';
// 存取 API 资料的程序码
import * as dataUtils from './data-utils';
dom-utils.ts 内都是操作画面的逻辑,但这不是主要练习的部分,现在前端 SPA 框架的盛行,不同框架会有不同的画面操作方式,单纯操作 DOM 物件其实是脏活,所以大概知道有些什麽功能就好罗:
-
fillAutoSuggestions:显示自动完成的建议内容 -
fillSearchResult:显示搜寻结果 -
loading:当开始搜寻资料时,呼叫此方法将画面遮罩,避免多余的操作 -
loaded:当完成搜寻後,呼叫次方法隐藏画面遮罩,以便进行其他操作 -
updatePageNumber:更新页码的画面资讯 -
updateStarsSort:更新依照 stars 排序的画面资讯 -
updateForksSort:更新依照 forks 排序的画面资讯
而在 data-utils.ts 内,则是 GitHub API 的呼叫,这里使用 RxJS 内提供的 ajax 来抓取呼叫 API 的内容,并使用 map operator 来将需要的内容抓出来,例如「取得建议清单」的程序码如下:
const baseUrl = `https://api.github.com/search/repositories`
export const getSuggestions = (keyword: string) => {
const searchUrl = `${baseUrl}?q=${keyword}&per_page=10&page=1`;
return ajax(searchUrl).pipe(
map(response => response.response.items),
map(repositories =>
repositories.map(repository => repository.full_name))
);
};
上述程序码的第 7 行使用的是 RxJS 内的 map operator,而第 8 行使用的是 JavaScript 内建阵列的 map,有些时候在阅读上会不小心造成误解,这时候可以把里面的实作逻辑也抽出来,会变得更好阅读:
// 将阵列的处理抽成 function
const toSuggestionList = (repositories) => {
return repositories.map(repository => repository.full_name)
};
export const getSuggestions = (keyword: string) => {
const searchUrl = `${baseUrl}?q=${keyword}&per_page=10&page=1`;
return ajax(searchUrl).pipe(
map(response => response.response.items),
map(toSuggestionList)
);
};
此时原来程序就可以阅读成「将回传结果转换成建议清单 (map to suggestion list)」,在实作程序码比较复杂,或是阅读上比较不好理解时,适当的将程序码抽成好读好理解的 function 对於未来开发和维护都会有加分效果喔!
data-utils.ts 内还有一个 getSearchResult 方法,是用来取得搜寻结果的,实作基本上大同小异,只是带入更多的参数而已,就不浪费篇幅在这说明了,有兴趣的话可以看一下罗。
实作自动完成功能
接着我们来实际做出自动完成的功能,自动完成要做的事情非常简单,就是在打字时,呼叫 dataUtils.getSuggestions() 方法来取得要显示的清单,并且呼叫 domUtils.fillAutoSuggestions() 即可。
取得事件资讯
我们可以使用 fromEvent 来监听输入框的 input 事件:
const keyword$ = fromEvent(document.querySelector('#keyword'), 'input');
此时订阅的话回得到 input 相关的事件,然而我们实际上需要关注的是输入的内容,因此可以使用 map 来进行转换:
const keyword$ = fromEvent(document.querySelector('#keyword'), 'input').pipe(
map(event => (event.target as HTMLInputElement).value)
);
这边使用了 event.target 来取得事件来源的 DOM 物件,由於是一个 input 输入框,因此可以使用 .value 来取得相关的值,as HTMLInputElement 是 TypeScript 的型别转换,让我们可以明确的知道 input 输入框有哪些属性可用。
此时 keyword$ 就是一个「关键字内容的资料流」,我们可以再将此资料流搭配各种其他的 operators 来产生出不同的变化。
将事件转换成查询 Observable
现在已经可以拿到输入的关键字了,接下来要把关键字带入 domUtils.getSuggestions() 方法来查询,最简单的方法如下:
keyword$.subscribe(keyword => {
domUtils.getSuggestions(keyword).subscribe(suggestions => {
domUtils.fillAutoSuggestions(suggestions);
});
});
不用多说,这种巢状的 subscribe 是应该尽力避免的,因此我们改用 switchMap operator 来协助我们「将某个事件值换成另一个 Observable」:
keyword$
.pipe(
switchMap(keyword => dataUtils.getSuggestions(keyword))
)
.subscribe(suggestions => {
domUtils.fillAutoSuggestions(suggestions);
});
使用 switchMap 可以在来源资料变更时,退订上一次的 Observable 订阅,因此永远会以最新的来源资料及转换後的 Observable 为主,如此可以确保我们拿到的资料一定是使用最新的 keyword 关键字查询的结果。
这边说明一下为何不使用其他 xxxMap 系列的 operators:
-
concatMap:虽然会拿到最後的资料,但因为不会退订上一次 Observable 订阅的关系,需要等之前 keyword 变更的查询都结束,会花费比较多时间。 -
mergeMap:每次 keyword 变更都会立刻查询,不退订之前的 Observable,加上 API 呼叫是非同步的关系,我们没办法确保最後一次会来的结果一定就是最新的查询结果,因此查询结果会不稳定。 -
exhaustMap:在之前 Observable 查询完成之前,有任何新的事件都会被忽略掉,因此只要事件更新前转换的 Observable 没结束,就不会拿到新事件的查询结果。
如果不明白这几个 operators 的差别,请先看过之前写的文章:
[RxJS] 转换类型 Operators (2) - switchMap / concatMap / mergeMap / exhaustMap
此时已经可以在每次输入关键字就进行查询罗,但还有很多需要加强的地方!
避免资料一变更就查询
GitHub API 在未验证时有限制每分钟只能进行 10 次查询(有验证时限制每分钟 30 次查询),这是为了保护服务器被大量搜寻的机制(称为 Rate Limits),在实际应用上,我们也应该要尽可能避免使用者产生大量的查询,以免前端的疏失操成後端的效能低落,因此在这里我们可以再加上一个 debounceTime operator,来避免一有新事件就查询的问题:
keyword$
.pipe(
// 避免一有新事件就查询
debounceTime(700),
switchMap(keyword => dataUtils.getSuggestions(keyword)),
)
.subscribe(suggestions => {
domUtils.fillAutoSuggestions(suggestions);
});
debounceTime 可以在指定的时间内都没有新事件发生後,才以最後一次的事件值进入下一个步骤,透过这种方式,就可以避免一直打字一直查询的问题罗。
避免重复文字查询
想像一下,假设目前输入的内容是「rxjs」,并且已经完成一次建议清单的查询,接着我们继续输入变成「rxjsdemo」,但想了一下又删掉变回「rxjs」,然後 debounceTime 的控制时间才过去,新的事件资料跟上一次的事件资料一样都是「rxjs」,如果资料其实并没有改变,还需要再进行一次查询吗?这时候当然就可以省略不查询了,因此可以使用 distinctUntilChanged operator,只有当新的事件值与上一次的事件值不同时,才会继续让事件发生:
keyword$
.pipe(
debounceTime(700),
// 避免重复的查询
disintctUntilChanged(),
switchMap(keyword => dataUtils.getSuggestions(keyword)),
)
.subscribe(suggestions => {
domUtils.fillAutoSuggestions(suggestions);
});
如果要避免资料重复,为何不使用 distinct 呢?以这边的例子来说,当我把资料变更成「rxjsdemo」时,如果有产生新的查询,下一次变更回「rxjs」时,由於 distinct 的设计是「整个资料流的事件值不会重复」,因此「rxjs」事件值在整个资料流过程已经发生过了会被忽略掉,导致没有正确查询,画面显示错误的资料。
而使用 distinctUntilChanged,则只有跟「上一次」事件值相同才会忽略,因此可以避免掉 distinct 的问题。
distinct 和 distinctUntilChanged 的差别,可以参考之前写的文章:
[RxJS] 过滤类型 Operators (4) - distinct / distinctUntilChanged / distinctUntilKeyChanged
避免查出不精准的内容
最後来微调一下,如果不管资料长度都会进行搜寻,就会导致一开始只输入一个「r」这样的资料时就会开始进行搜寻,而得到比较不精准的内容,因此可以再做个调整,让查询内容大於某个长度时才进行搜寻,例如至少要 3 个字,此时使用最基本的 filter operator 就可以了:
keyword$
.pipe(
debounceTime(700),
disintctUntilChanged(),
// 避免内容太少查出不精准的结果
filter(keyword => keyword.length >= 3),
switchMap(keyword => dataUtils.getSuggestions(keyword)),
)
.subscribe(suggestions => {
domUtils.fillAutoSuggestions(suggestions);
});
透过这些 operators 的控制,就能设计出兼顾效能及准度的自动建议功能啦。
像这样的程序码,可以想想看没有各种 operators 加持的情况下,要判断多少状态、条件,而有了 RxJS 及各种 operators,真的可以帮助我们大幅减少许多程序码的撰写!
实作关键字搜寻功能
关键字的建议及自动完成功能搞定了,接着先来单纯的针对关键字进行搜寻,这里我们希望按下「search」按钮时,才针对我们要的关键字进行查询:
取得事件资讯
一样的,我们可以使用 fromEvent 来将按钮事件包装成 Observable
const search$ = fromEvent(document.querySelector('#search'), 'click');
接着我们就需要在事件发生时,依照输入的关键字进行搜寻。
将事件转换成查询 Observable
我们一样可以透过 switchMap operators 来将按钮事件转换成查询资料的 Observable:
search$.pipe(
switchMap(() => dataUtils.getSearchResult(
(document.querySelector('#keyword') as HTMLInputElement).value)
)
).subscribe(result => {
domUtils.fillSearchResult(result);
});
第 2 行程序使用 switchMap 将事件转换成查询的 Observable,里面的参数在第 3 行直接取得输入框 DOM 物件资料。
在关键字内容部分,我们已经有一个 keyword$ 的资料流了,不多加运用实在很可惜:
const searchByKeyword$ = search$.pipe(
switchMap(() => keyword$),
switchMap(keyword => dataUtils.getSearchResult(keyword))
);
searchByKeyword$.pipe(
switchMap(keyword => dataUtils.getSearchResult(keyword))
).subscribe(result => {
domUtils.fillSearchResult(result);
});
我们建立了一个 searchByKeyword$ 的 Observable,它会:
- 当搜寻按钮按下时,转换成
keyword$Observable - 当
keyword$Observable 有新事件时,转换查询用的 Observable
但这样会有两个问题:
- 转换为
keyword$後,还没有新的事件发生,因此不会进行查询,需要等keyword$有新事件才会查询 - 因为
keyword$资料流不会结束(因为随时可能输入新的文字),因此搜寻按钮事件後,每次keyword$有新事件都会变成查询,这不是我们要的,我们希望拿到最新的关键字後直接进行查询,然後结束。
接着我们来解决这两个问题
共享关键字资料流
由於转换成 keyword$ 後,需要等待新事件才会查询,我们希望能立刻得到最後一次事件资料,因此我们可以使用 shareReplay() 将 keyword$ 转换成 Hot Observable 并将最後 N 次事件资料共享出来:
const keyword$ = fromEvent(document.querySelector('#keyword'), 'input').pipe(
map(event => (event.target as HTMLInputElement).value),
// 共享最後一次事件资料
shareReplay(1)
);
在这里我们建立了 keywordForSearch$ 的 Observable,专门给 search$ 转换使用,keywordForSearch$ 内使用 shareReplay(1) 确保每次订阅时会先拿到事件的最後一笔资料。
为何不使用 share() 呢?由於 share() 实际上是建立一个 Subject,而 Subject 的特性是订阅後需要等 Subject 有新事件才会得到资料,因此使用 shareReplay() 来建立 ReplaySubject ,ReplaySubject 会依照设定纪录最近 N 次事件资料。
关於 share() 和 shareReplay() 背後默默做的事情及差异,可以参考之前的文章:
[RxJS] Multicast 类 Operator (1) - multicast / publish / refCount / share / shareReplay
确保 switchMap 内资料流会结束
确定可以拿到 keyword$ 最後一次事件资料後,接着来处理事件不会结束的问题,这个问题很好解决,使用 take 就好,take operator 可以在订阅後取得前 N 次事件资料,然後结束资料流,因此只需要设定成 1,就可以在拿到第一次资料後结束。
const keywordForSearch$ = keyword$.pipe(
// 取得一次资料流事件後结束
take(1)
);
const searchByKeyword$ = search$.pipe(switchMap(() => keywordForSearch$));
整体流程就会变成:
-
search$发生新事件,转换成keywordForSearch$Observable -
keywordForSearch$Observable 使用keyword$作为来源,并且有shareReplay(1)的关系,会立刻得到最近一次keyword$的事件资料 - 再加上
take(1),因此在取得最近一次事件资料的同时,结束 Observable
排除按钮事件比关键字事件早发生的问题
最後,还有一个问题:当搜寻按钮按下时,如果 keyword$ 还没有事件资料,那麽转换後的 keywordForSearch$ 就不会立刻结束,此时会变成按下按钮後,再变更搜寻文字才会进行查询,这是不合理的,因此我们要给 keyword$ 资料流一个初始资料:
const keyword$ = fromEvent(document.querySelector('#keyword'), 'input').pipe(
map(event => (event.target as HTMLInputElement).value),
// 让资料流有初始值
startWith(''),
// 共享最後一次事件资料
shareReplay(1)
);
接着我们必须避免空字串的查询,因此加上 filter 不让空字串的事件发生:
const searchByKeyword$ = search$.pipe(
switchMap(() => keywordForSearch$),
// 排除空字串查询
filter(keyword => !!keyword)
);
searchByKeyword$.pipe(
switchMap(keyword => dataUtils.getSearchResult(keyword))
).subscribe(...);
如此一来,就将「关键字变更的资料流 (keyword$) 」和「按钮事件的资料流 (search$)」整合成「依照关键字进行搜寻(searchByKeyword$)」的资料流罗。
实作排序与分页功能
最後我们将分页与排序都整合进搜寻功能,整个画面就会很完整啦!
建立搜寻条件的 Observables
之前已经有 searchByKeyword$ 依照关键字查询的 Observable 了,接着我们要处理排序、分页等条件的 Observables。
取得排序相关事件
在排序部分,我们希望预设能以 stars 数量降幂排序,也就是预设 stars 越多的越前面,同时能针对 stars 和 forks 进行升幂/降幂排序,stars 和 forks 是两个不同的栏位,但排序是「一个资讯」,因此我们可以使用 Subject 类别,并分别订阅两个栏位的事件,来改变 Subject 资讯。
我们需要有一个预设的排序条件,同时在改变排序时也会需要这个排序资讯来决定下一次的排序方式,因此可以使用 BehaviorSubject。
// 建立 BehaviorSubject,预设使用 stars 进行降幂排序
const sortBy$ = new BehaviorSubject({ sort: 'stars', order: 'desc' });
接着订阅画面上 stars 和 forks 的点击事件,来改变这个 sortBy$ 的事件值:
const sortBy$ = new BehaviorSubject({ sort: 'stars', order: 'desc' });
const changeSort = (sortField: string) => {
if (sortField === sortBy$.value.sort) {
sortBy$.next({
sort: sortField,
order: sortBy$.value.order === 'asc' ? 'desc' : 'asc'
});
} else {
sortBy$.next({
sort: sortField,
order: 'desc'
});
}
};
fromEvent(document.querySelector('#sort-stars'), 'click').subscribe(() => {
changeSort('stars');
});
fromEvent(document.querySelector('#sort-forks'), 'click').subscribe(() => {
changeSort('forks');
});
在 changeSort 方法里面,我们可以使用 sortBy$.value 得到 BehaviorSubject 最近的事件值,并依此判断接下来排序的规则。
取得每页几笔的事件
接着我们先来处理「每页显示几笔」的下拉选单,我们可以很容易的使用 fromEvent 来将 select 的事件资料进行转换,这部分跟 keyword$ 非常类似,差别只在处理的来源和事件不同而已:
const perPage$ = fromEvent(document.querySelector('#per-page'), 'change').pipe(
map(event => +(event.target as HTMLSelectElement).value)
);
取得切换页码事件
最後是切换页码,实际上是两个按钮分别代表「上一页」和「下一页」,页数分别会「减 1」和「加 1」,因此我们可以分别把按钮事件变成 1 和 -1,以便用来计算下一页的页码:
const previousPage$ = fromEvent(
document.querySelector('#previous-page'),
'click'
).pipe(
mapTo(-1)
);
const nextPage$ = fromEvent(
document.querySelector('#next-page'),
'click'
).pipe(
mapTo(1)
);
因为转换的是一个固定不动的常数,因此可以直接使用 mapTo operator 进行转换。
接着我们可以把这两个 Observables 使用 merge 组合成一个 Observable,并使用 scan 来变更页码资讯:
const page$ = merge(previousPage$, nextPage$).pipe(
scan((currentPageIndex, value) => {
const nextPage = currentPageIndex + value;
return nextPage < 1 ? 1 : nextPage;
}, 1)
);
透过这种方式,也可以轻松完成「下 5 页」、「下 10 页」的功能罗。
将搜寻条件的 Observable 组合
所有查询相关的资料来源都准备完毕後,最後我们只需要把这些条件组合在一起就可以了,我们需要每个事件最後一次的资讯,因此可以使用 combinteLatest 来组合每个资料流最後的事件值,再将这些资料丢给 dataUtils.getSearchResult() 查询:
// 组合搜寻条件
const startSearch$ = combineLatest([
searchByKeyword$,
sortBy$,
page$,
perPage$
]);
// 将搜寻条件转换成查询 Observable
const searchResult$ = startSearch$.pipe(
switchMap(([keyword, sort, page, perPage]) =>
dataUtils.getSearchResult(keyword, sort.sort, sort.order, page, perPage)
)
);
searchResult$.subscribe(result => {
domUtils.fillSearchResult(result);
});
由於 combineLatest 是将里面 Observables 的「最後一次事件」组合起来,因此若某个 Observable 还没发生过事件,整个 combineLatest 组合的 Observable 都还不会有事件值,此时 page$ 和 perPage$ 都没有启始资料,因此就算按下搜寻,还不会有任何反应,所以最後针对 page$ 和 perPage$ 再使用 startWith 给予初始资料:
const startSearch$ = combineLatest([
searchByKeyword$,
sortBy$,
// 给予 page$ 初始资料
page$.pipe(startWith(1)),
// 给予 perPage$ 初始资料
perPage$.pipe(startWith(10))
]);
基本的查询、分页和排序功能就完成啦!!
最後让我们再来针对一些细节来做调整。
显示页码/排序资讯
这部分很简单,订阅原来的事件,然後把事件资讯更新到画面上就好了:
page$.subscribe(page => {
domUtils.updatePageNumber(page);
});
sortBy$.pipe(filter(sort => sort.sort === 'stars')).subscribe(sort => {
domUtils.updateStarsSort(sort);
});
sortBy$.pipe(filter(sort => sort.sort === 'forks')).subscribe(sort => {
domUtils.updateForksSort(sort);
});
以上程序直接订阅 page$,并使用 domUtils.updatePageNumber() 更新页码资讯,而排序资讯则依照排序类型有两个不同的方法呼叫,因此使用 filter 将不同的的排序栏位分成两个 Observable,并各自订阅然後呼叫各自对应的方法来更新排序栏位资讯。
查询中的遮罩画面
接下来我们需要在查询资料时呼叫 domUtils.loading() 遮罩画面,并在查询结束时呼叫 domUtils.loaded() 隐藏遮罩,在查询条件变更时就需要遮罩住画面,因此订阅 startSearch$ Observable 即可:
startSearch$.subscribe(() => {
domUtils.loading();
});
接着在查询完毕後,除了画面更新外,也要将此遮罩隐藏:
searchResult$
.subscribe(result => {
domUtils.fillSearchResult(result);
domUtils.loaded();
});
错误处理
当查询过程发生错误时,整条订阅的 Observable 会完全中断,这也代表如果中途产生无法处理的错误,会造成之後无法继续进行查询作业,为了避免这个问题,我们可以使用 catchError() 来拦截并处理错误:
searchResult$
.pipe(
// 处理搜寻事件的错误,以避免整个资料流从此中断
catchError(() => of([]))
)
.subscribe(result => {
domUtils.fillSearchResult(result);
domUtils.loaded();
});
乍看之下没什麽问题,当 searchResult$ 发生错误时,拦截错误并给予空阵列,这样便可以确保 subscribe 的 next() 可以收到资料,但 catchError() 回传的 Observable 会让目前订阅的 Observable 剩下一个空阵列的资料然後结束,因此依然会让整个订阅结束,而导致无法继续查询。
这时候就要朝错误的源头下手,也就是 startSearch$.pipe(switchMap(...)) 内的 Observable,在这里面进行错误处理,才不会让整个 Observable 订阅被结束,所以我们把查询的程序拉出来,并加上错误处理机制:
const getSearchResult = (
keyword: string,
sort: string,
order: string,
page: number,
perPage: number
) =>
dataUtils
.getSearchResult(keyword, sort, order, page, perPage)
.pipe(
// 从查询开始处理错误
catchError(() => of([]))
);
如此原来的 searchResult$ 就不会有其他需要处理的错误,整个订阅就不会因此而结束。
显示错误讯息
上个阶段我们已经能处理错误了,但目前只是当错误发生时查不到资料而已,使用者感觉不出有错误发生,因此我们需要提示错误讯息,最简单的方式是在 catchError() 内进行提示:
const getSearchResult = (
keyword: string,
sort: string,
order: string,
page: number,
perPage: number
) =>
dataUtils
.getSearchResult(keyword, sort, order, page, perPage)
.pipe(
// 从查询开始处理错误
catchError((error) => {
alert(error.response.message);
return of([]);
})
);
这样依然会有 side effect 的问题,所以可以换个方式,把资料包装起来,当错误发生时,加上一个错误的 flag:
const getSearchResult = (
keyword: string,
sort: string,
order: string,
page: number,
perPage: number
) =>
dataUtils
.getSearchResult(keyword, sort, order, page, perPage)
.pipe(
// 正常收到资料时,将资料包装起来且 success 设成 true
map(result => ({ success: true, message: null, data: result })),
catchError((error) => {
// 发生错误时,将资料包装起来且 success 设成 false
// 同时传递错误资讯,让後续订阅可以处理提示
return of({
success: false,
message: error.response.message,
data: []
})
}));
这麽一来就可以保留整个流程,直到 subscribe 时在进行处理,原来订阅是直接拿 result 去更新,现在 result 变成包含是否成功资讯的物件,因此只要取其中的 data 来更新就好:
searchResult$.subscribe(result => {
// 原来的 result 改变了,因此取其中的 data 就好
// domUtils.fillSearchResult(result);
domUtils.fillSearchResult(result.data);
domUtils.loaded();
});
而处理错误的部分,我们可以拉出另外一条 Observable 来处理:
// 处理错误提示
searchResult$
.pipe(
filter(result => !result.success)
).subscribe(result => {
alert(result.message);
});
把「显示资料」和「错误处理」当作两个不同的资料来源处理,可以让我们在阅读程序时更加专注在原本的意图上。
这里最後需要注意的是,searchResult$ 因为针对不同情境处理而被订阅了两次,而原来的 searchResult$ 是 Cold Observable,且其中有 ajax 的呼叫,代表每次订阅都会重跑一次 ajax,这麽一来 API 呼叫就会重复,造成不必要的浪费,所以最後再 searchResult$ 补上 share():
const searchResult$ = startSearch$.pipe(
switchMap(([keyword, sort, page, perPage]) =>
getSearchResult(keyword, sort.sort, sort.order, page, perPage)
),
// searchResult$ 有多次订阅
// 因此使用 share 避免重复请求资料
share()
);
在前面 keyword$ 示范时使用 shareReplay(1) 是因为订阅时机会随着按钮事件的 switchMap() 订阅时间而不同,且需要最後一次事件的资讯。
在这里使用 share() 则是因为订阅会立刻发生,且没有使用最後一次事件资讯需要的关系;当然,要在这里使用 shareReplay(1) 在逻辑上也是完全没问题的。
本日小结
今天我们透过实际在网页程序上常常遇到的查询、分页和排序等功能,来说明实务上 RxJS 的应用,以及各种 operators 的组合技巧。
当所有事件都使用资料流及 Observable 的观点来思考时,整个思路会变得更加单纯,我们只需要习惯应用各种已经学会的 operators 来组合这些资料流即可,而且每个资料流、每个订阅都只处理自己该做的事情,让每段程序码都变得更简短好阅读,且发生问题时,也可以很容易从问题发生点循序找到每个执行过程,更容易找到错误发生的地方!
刚开始在学习 RxJS 时一定会对於何时该使用哪些 operators 的问题觉得不知所措,建议可以多加练习,把上述的程序码反覆写过,了解每个资料的流向,接着更可以尝试组合不同的 operators,用不同的写法达到一样的功能,久而久之习惯後,RxJS 功力就会大增罗!!
<<: JavaScript基本功修练:Day31 - 完赛了,然後呢?
>>: 强型闯入DenoLand[30] - Web API 实作篇
第41天~
这个得上一篇:https://ithelp.ithome.com.tw/articles/10258...
Day09 iPhone捷径-位置Part1
Hello 大家, 上三天就放假了~~ 但还是觉得好累= = 周休二日真的不够, 至少每周可以在家上...
Day20 - 在 XState 与 Side Effect 互动吧~ action API
1. Action 与 Side Effect 昨天,我们确认了状态能被储存起来,然而我们这个开门,...
Day 26 -资料库应用小程序 设计程序介面
上一篇我们完成了资料库的建置,那麽我们现在就可以来处理如何应用啦! 开始实作 首先我们要先开启之前要...
Day-4 Excel消失的0在哪里?
今天我们来更深入的探讨Excel中,首先先来介绍「日期」这个东西,并且我相信你也有遇过再Excel中...