【零基础成为 AI 解梦大师秘笈】Day30 - Django 整合部署 AI model
AI 解梦最终秘笈
前言
系列文章简介
大家好,我们是 AI . FREE Team - 人工智慧自由团队,这一次的铁人赛,自由团队将从0到1 手把手教各位读者学会 (1)Python基础语法 (2)Python Web 网页开发框架 – Django (3)Python网页爬虫 – 周易解梦网 (4)Tensorflow AI语言模型基础与训练 – LSTM (5)实际部属AI解梦模型到Web框架上。
为什麽技术要从零开始写起
自由团队的成立宗旨为开发AI/新科技的学习资源,提供各领域的学习者能够跨域学习资料科学,并透过自主学习发展协杠职涯,结合智能应用到各式领域,无论是文、法、商、管、医领域的朋友,都可以自由的学习AI技术。
资源
AI . FREE Team 读者专属福利 → Python Basics 免费学习资源
教学开始
终於到了成为解梦大师的最後一天,相信读者们都已经站稳脚步、蹲好马步,准备开始在江湖上替人解梦改运了吧!本日的教学文章将引导读者们将开发完成的解梦模型,实际架设到Django上,提供使用者能够透过网页介面,进行解梦。
基础必备知识
- Python基础程序开发
- Django网页开发框架
- Python网路爬虫
- Tensorflow - AI语言模型开发(LSTM)
(若尚未熟悉其中任一技术的读者,欢迎查看自由团队的对应教学文章!)
为了提升读者们的开发速度,自由团队将提供「colab实作程序码教学」及「Django网页聊天机器人模板」,透过colab修改聊天机器人的Django模板,部属LSTM模型。
基础前置设定
Step 1.
使用 google drive,以利读取已储存的模型、tokenizer…等部署资讯。(若在本地端进行部署,此步骤可略。)
# 连结至个人 Google Drive
from google.colab import drive
drive.mount('/content/drive')
Step 2.
下载并解压缩自由团队开发的开源Django聊天机器人模板。(若使用自己开发的Django APP,此步骤可略。)
# Git 下载自由团队-开源 Django 聊天机器人模板
!git clone https://github.com/chenkenanalytic/pro_file.git
# 解压缩自由团队-开源 Django 聊天机器人模板 压缩档
!7z x /content/pro_file/aifreeteam_c.7z
※ 解压密码,请洽 AI . FREE Team 粉丝页,按赞、私讯:「我想要聊天机器人模板」,就直接免费提供解压密码喔!
Step 3.
下载并安装聊天机器人套件,测试模板是否能正常运作,若想直接开发AI模型部署,此步骤可略。
# 安装聊天机器人相关套件
!pip install chatterbot==0.8.7
!pip install chatterbot-corpus==1.1.2
# Make migration - 确保开源 Django 专案顺利运作
!python /content/aifreeteam_chatbot/manage.py migrate
!python /content/aifreeteam_chatbot/manage.py makemigrations
※ 注意若有出现红色 Warnings 提醒字眼,记得点击"RESTART RUNTIME",确保环境套件正常运行。
Step 4.
下载Ngrok并解压缩 (便於後续我们能跨网域Access colab 的 server)
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip ngrok-stable-linux-amd64.zip
Step 5.
透过Ngrok先启动对外跨网域连线的port网址,并开启Django网页。
# 使用 Django 套件语法,开启并运行 colab Localhost
# 最後透过 Ngrok 套件对公开网域开启 Access 的权限
get_ipython().system_raw('./ngrok http 8050 &')
import time
time.sleep(1)
!curl -s http://localhost:4040/api/tunnels | python3 -c \
"import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
print("=======================================")
!python /content/aifreeteam_chatbot/manage.py runserver 0:8050
透过点击 Ngrok 所产生的网址,我们便能顺利连上在colab本地端运行的Django 网站,也能透过模板介面与chatterbot聊天机器人互动。(如下范例所示)
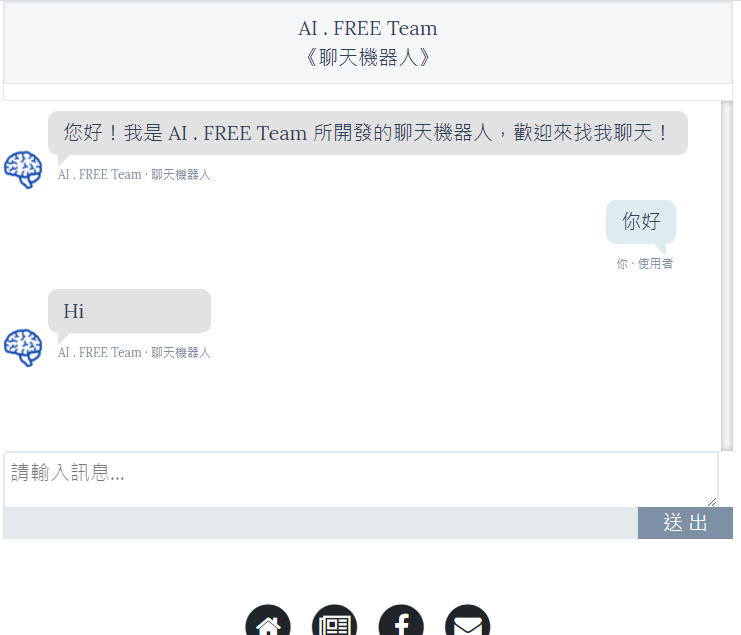
进阶开发 Django 专案 – AI 模型部署
Step 6. 将 setting.py 的聊天机器人模组进行注解 or 删除
目的是将聊天机器人的功能关闭,若不关闭,後续操作须注意不要呼叫到 chatterbot 相关套件功能,以避免开发过程额外的错误。
path /content/aifreeteam_chatbot/example_app/settings.py
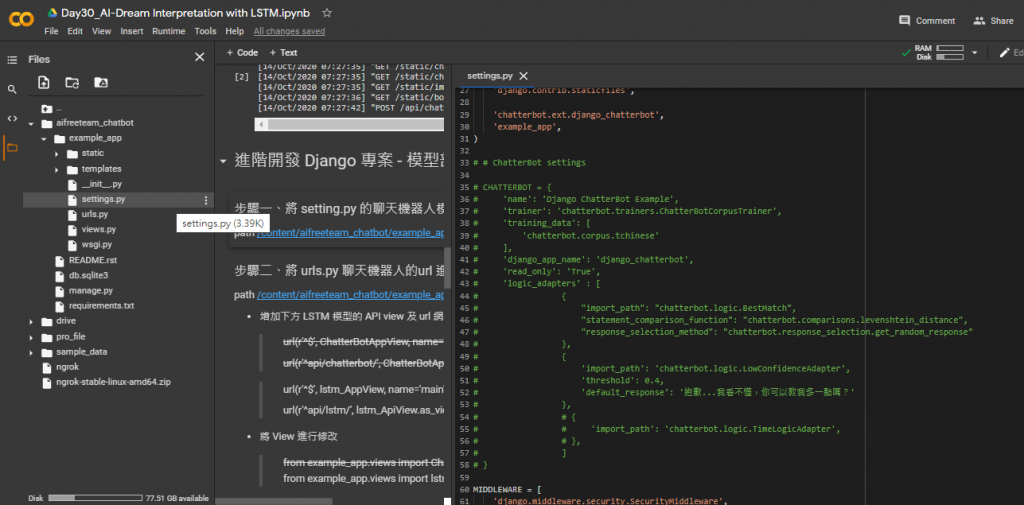
▲ 注解 chatterbot app 如上图 (快捷键:选取程序码 + ctrl + / )
Step 7. 将 urls.py 聊天机器人的url 进行注解并修改
- 增加LSTM 模型的 API view 及 url 网址
# url(r'^$', ChatterBotAppView, name='main'),
# url(r'^api/chatterbot/', ChatterBotApiView.as_view(), name='chatterbot'),
url(r'^$', lstm_AppView, name='main'),
url(r'^api/lstm/', lstm_ApiView.as_view(), name='lstm')
- 将 View 进行修改
# 注解 chatterbot 套件(#from example_app.views import ChatterBotAppView...)
# 新增 LSTM 模型 APP view 套件
from example_app.views import lstm_AppView, lstm_ApiView
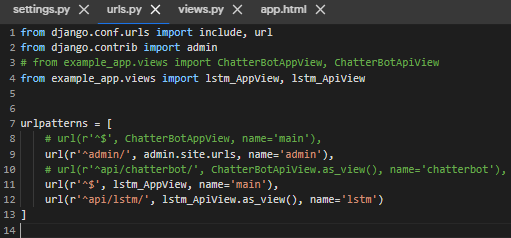
▲ 范例如上所示
Step 8. 在 Views 中,增加 LSTM 模型运行的 API view
可先在 colab 执行程序码看看是否有 Error,
若没有错误讯息,可直接於 views.py 档案新增下述程序码
- (1) Keras 模型前置设定、文字生成函式
依据训练 AI 模型的资讯设定参数及超参数
import tensorflow as tf
import pickle
# 【重要】请设定周易解梦模型资讯======================================
Tokenizer_path = '/content/drive/My Drive/LAB/IT_post/tokenizer.pickle'
model_path = '/content/drive/My Drive/LAB/IT_post/model_01.h5'
w = 5445
EMBEDDING_DIM = 512
RNN_UNITS = 1024
# 【重要】请设定周易解梦模型资讯======================================
读取开发文字集的 tokenizer
# 读取先前储存的 Tokenizer (文字对应数字的索引)
with open(Tokenizer_path, 'rb') as handle:
tokenizer = pickle.load(handle)
设定模型
# 跟训练时不同,生成过程的 BATCH_SIZE 改设为 1
BATCH_SIZE = 1
# 定义生成的模型
infer_model = tf.keras.Sequential()
infer_model.add(tf.keras.layers.Embedding(input_dim=w, output_dim=EMBEDDING_DIM, batch_input_shape=[BATCH_SIZE, None]))
infer_model.add(tf.keras.layers.LSTM(units=RNN_UNITS, return_sequences=True, stateful=True))
infer_model.add(tf.keras.layers.Dense(w))
# 载入已储存模型之权重
infer_model.load_weights(model_path)
infer_model.build(tf.TensorShape([1, None]))
撰写解梦的函式 (输入梦境内容 – dream_text、输出 AI 解梦结果 - text_generated)
def interpret_dream(dream_text):
text_generated = dream_text
for i in range(100):
dream = tokenizer.texts_to_sequences([text_generated])[0]
# 增加 batch 维度丢入模型取得预测结果後
# 再度降维,拿掉 batch 维度
input = tf.expand_dims(dream, axis=0)
predictions = infer_model(input)
predictions = tf.squeeze(predictions, 0)
temperature = 1.0
# 利用生成温度影响抽样结果
predictions /= temperature
# 从 4330 个分类值中做抽样
# 取得这个时间点模型生成的中文字
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
input_eval = tf.expand_dims([predicted_id], 0)
partial_texts = [ tokenizer.index_word[predicted_id] ]
text_generated += partial_texts[0]
# 成功生成 解梦文字档 → text_generated
# 透过撷取重点解梦文字作呈现
return text_generated.split('\n')[0].split('。')[0]
- (2) API View 对接程序码
参考 chatterbot API view 的程序码,修改为 lstm 模型专属的 API view。
from django.views.generic import View
def lstm_AppView(request):
template_name = 'app.html'
csrf_token = get_token(request)
return render(request, 'app.html',locals())
class lstm_ApiView(View):
def get_conversation(self, request):
class Obj(object):
def __init__(self):
self.id = None
self.statements = []
conversation = Obj()
conversation.id = request.session.get('conversation_id', 0)
existing_conversation = False
def post(self, request, *args, **kwargs):
input_data = json.loads(request.read().decode('utf-8'))
if 'text' not in input_data:
return JsonResponse({
'text': [
'The attribute "text" is required.'
]
}, status=400)
response = input_data
raw_text = input_data['text']
text = interpret_dream(raw_text)
text = ''.join(text).replace('##', '').strip()
response['text'] = text
response_data = response
return JsonResponse(response_data, status=200)
确认以上(1) Keras 模型前置设定、文字生成函式及 (2) API View 对接程序码,若没有 error 产生,我们可以直接将程序码贴到 views.py档案中罗!
Step 9. 修改前端对应的後端函式 id
var chatterbotUrl = '{% url "lstm" %}';
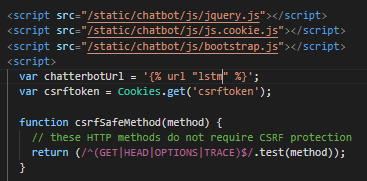
▲范例如上
Step 10. 执行 django ,开始解梦罗!
# 透过 Ngrok 套件对公开网域开启 Access 的权限,检视结果
get_ipython().system_raw('./ngrok http 8050 &')
import time
time.sleep(1)
!curl -s http://localhost:4040/api/tunnels | python3 -c \
"import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
print("=======================================")
!python /content/aifreeteam_chatbot/manage.py runserver 0:8050
虽然我们的网页介面仍是聊天机器人的使用介面,但是透过对话视窗,我们便可以开始透过打字输入进行解梦喔!
以下为几个解梦的范例,虽然有些看起来内容感觉蛮奇异的,但是大致上 AI LSTM 模型,是有抓到解释梦境的基础能力。
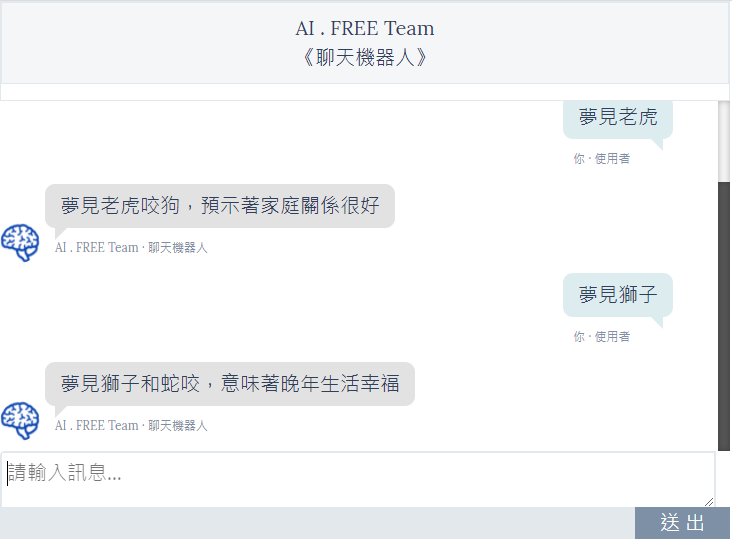

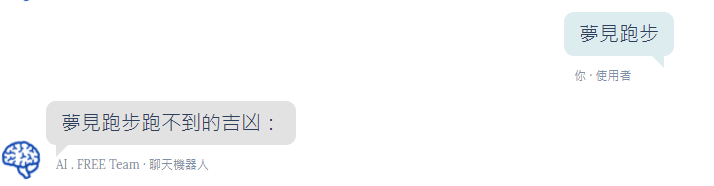
而毕竟是一个简单的、没有太多复杂处理、尚未优化的 AI 模型,偶尔也会出现一些比较无厘头的解梦回覆。(如下范例)

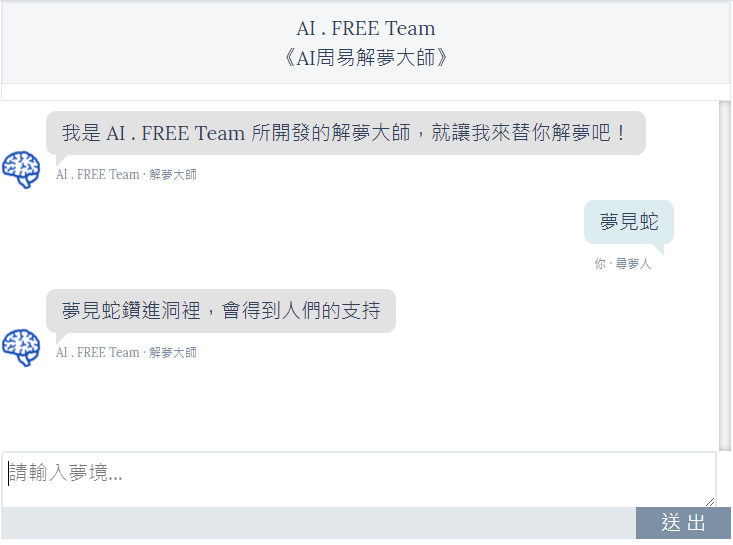
当然我们也能够透过修改前端网页(html),让介面更完整,使用起来更有感觉!
使用 colab 跟 Ngrok 工具,也能让使用者透过手机、平板等行动设备,连线进行解梦,可说是阖家适宜的一项工具!
这一系列 AI 解梦大师的教学文章就到这边,当然,此专案仍有许多地方可以优化、改善,例如:爬取更多资料、资料清理的环节更细致、训练模型更大、模型更复杂、超参数的微调… etc.
未来若有机会,我们也会针对更进一步的模型(GPT2)、资料处理的细节,进行对外开课,欢迎有兴趣的读者进一步询问粉丝专页!
最後还请各位读者,敬请关注自由团队粉丝专页及加入自由团队学习社群!
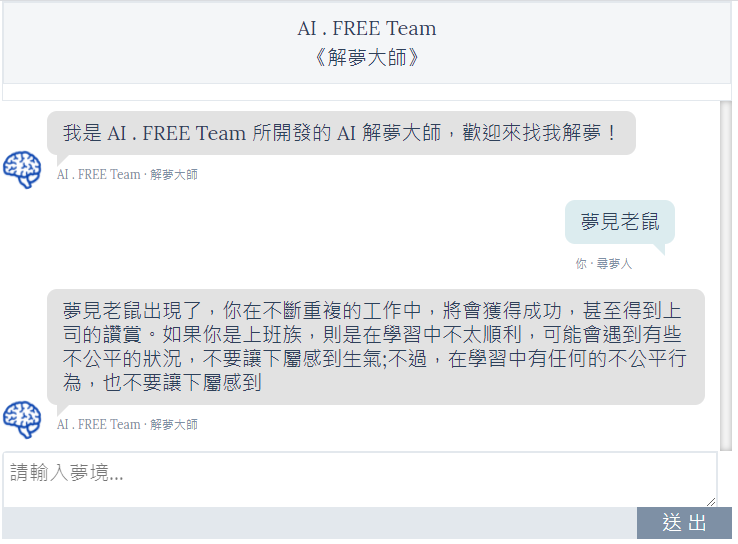
▲ 使用GPT2 训练出来的解梦模型更完整、更全面
想更深入认识 AI . FREE Team ?
自由团队 官方网站:https://aifreeblog.herokuapp.com/
自由团队 Github:https://github.com/AI-FREE-Team/
自由团队 粉丝专页:https://www.facebook.com/AI.Free.Team/
自由团队 IG:https://www.instagram.com/aifreeteam/
自由团队 Youtube:https://www.youtube.com/channel/UCjw6Kuw3kwM_il39NTBJVTg/
文章同步发布於:自由团队部落格
(想看更多文章?学习更多AI知识?敬请锁定自由团队的频道!)
<<: [2020铁人赛] Day30 - .net core第一阶段结束,感谢IT邦!
>>: Day 30 Python3 + selenium 撷取网站状态快照
Day17 AR装置的编年史(下) 各家公司开始研发各种AR装置
前面说了那麽久,但看起来好像这些都不是拿来给一般民众使用的AR装置,之後AR又有什麽变化呢!?让我们...
[day10] Flask Python API Service
安装Flask跟套件 pip install flask pip install flask-res...
[Day30]漏洞挖起来心得结论
耶!庆祝漏洞挖起来系列文终於硬挤资源及项目写了 30 天罗! 感谢大家硬是看我写 30 天废文 其实...
Day2 - Yolo? 那是什麽? 能吃吗?
今天要介绍的是Object detection(物件侦测)以及CNN (Convolutional ...
Day 19 - 建立 canvas QRCode
前述 今天因为时间不足 T_T .... 所以教大家使用 qrcode.react ,可以很快速的产...