Day-29 了解 Kubernetes AutoScaler
前言
到了这个章节大家可能会开始回想,刚开始听到K8S时很多人都说Kubernetes的AutoScaling很厉害,亦或者是Kubernetes能够帮使用者在Cloud上省下不少钱,但Kubernetes到底是如何这到这些事情的呢?这章节我们就是来探讨此事。
AutoScaling in Kubernetes
在Kubernetes cluster当中,当丛集内部触发了某些条件时,丛集会开始所谓的AutoScaling,但是这些AutoScaling又是有分层级的,分别为:
- HorizontalPodAutoscaler
- VerticalPodAutoscaler
- ClusterAutoscaler
这本篇章会透过这三种层级的Scaling来探讨Kubernetes是如何办到这件事的,以及如何触发这件事。
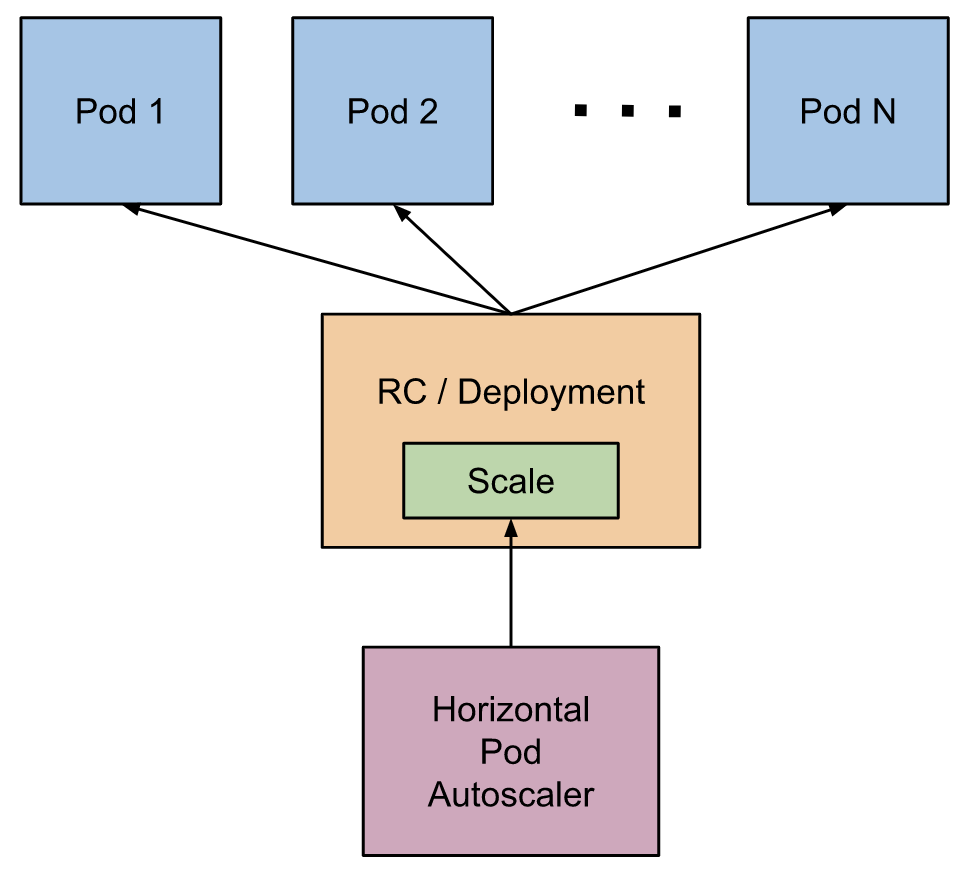
What is HorizontalPodAutoScaler ?
基於CPU使用率或特定资源条件自动增减ReplicationController、ReplicaSet与Deployment中Pod的数量。特定资源条件可以为CPU、Memory、Storage或其他自订条件。另外原本就无法自动增减的Pod是不能透过HPA进行autoScaling的,像是DaemonSet中的Pod。
HorizontalPodAutoScaler也是透过Kubernetes APi资源和控制器实现,由监控中的资源来决定控制器的行为。控制器会周期性的调整replicaSet/Deployment中Pod的数量,以使得Pod的条件资源能够低於临界值而不在继续的产生新的replica。
How does HorizontalPodAutoScaler work ?
HorizontalPodAutoScaler每个周期时间会定期去查询所监视的目标以及指定的目标资源查询率,
来判断目标是否需要Scaling。
Example
hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: ironman-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ironman
minReplicas: 2
maxReplicas: 5
targetCPUUtilizationPercentage: 50
- kind: HorizontalPodAutoscaler
- spec.scaleTargetRef: 指定目标资讯
- spec.minReplicas: 指定目标最小数目的Replicas
- spec.MaxReplicas: 指定目标能scaling的最大replica数
- targetCPUUtilizationPercentage: 指定目标的Scaling条件,这边为CPU的平均百分比。
Algorithm details
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
- 假设当前metric value为200m,但target metric value为100m,这时比较值为200 / 100 == 2.0 ,需要两倍的replicas
- 假设当前metric value为50m,但target metric value为100m,这时比较值为50 / 100 == 0.5,只需要一半replicas
- 假设当前metric value为92m,但target metric value为100m,这时比较值为92 / 100 == 0.92,因为1.00 - 0.92 = 0.08 小於预设容忍值0.1,因此放弃此次的scaling。
What is VerticalPodAutoscaler ?
VerticalPodAutoscaler有两个目标:
- 通过自动配置资源请求来减少运维成本。
- 在提高集群资源利用率的同时最小化容器出现内存溢出或CPU 饥饿的风险。
也因此VerticalPodAutoscaler透过几个方法达成该目标:
- VPA 能够在Pod 提交时设置容器的资源(CPU和内存的请求和限制)。
- VPA 能够配置在资源上的固定限制,特别是最小和最大资源请求。
- VPA能够调整已存在的Pod 的容器资源,特别是能够对CPU 饥饿和内存溢出等事件作出响应。
- VPA能与Pod控制器兼容(deployment)。
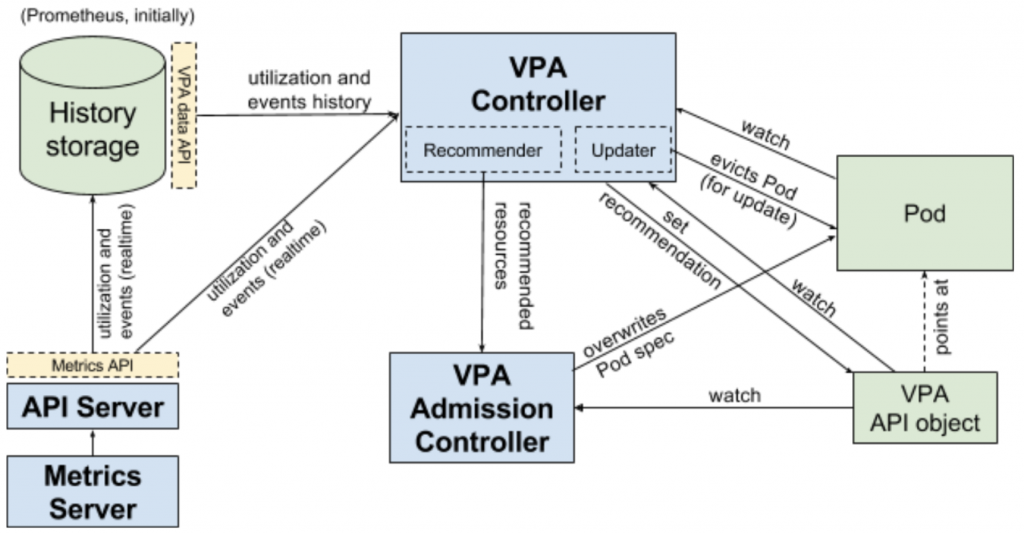
How does VerticalPodAutoscaler work ?
VerticalPodAutoscaler,它包括一个标签识别器label selector(匹配Pod)、资源策略resources policy(控制VPA如何计算资源)、更新策略update policy(控制资源变化应用到Pod)和推荐资源信息。
并且VPA能够透过VPA Controller做到以下几件事:
- 监控所有该类型Pod,并持续地为每个Pod计算新的推荐资源,并储存至VPA Object当中。
- 提供一个同步API来获取所有Pod资讯,并返回给Pod推荐讯息。
- 所有的Pod创建请求都会通过VPA Admission Controller。如果Pod与任何一个VPA对象匹配,那麽Admission controller会依据VPARecommender推荐的值重写容器的资源。如果Recommender连接不上,它将会返回VPA Object中缓存的推荐信息。
- 透过History storage纪录Pod历史资源使用相关资讯,Recommender在一开始用这些历史数据来初始化状态。History Storage基础的实现是使用Prometheus。
Example
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ironman
labels:
name: ironman
app: ironman
spec:
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
selector:
matchLabels:
app: ironman
replicas: 1
template:
metadata:
labels:
app: ironman
spec:
containers:
- name: ironman
image: ghjjhg567/ironman:latest
imagePullPolicy: Always
ports:
- containerPort: 8100
resources:
limits:
cpu: "1"
memory: "2Gi"
requests:
cpu: 500m
memory: 256Mi
envFrom:
- secretRef:
name: ironman-config
command: ["./docker-entrypoint.sh"]
- name: redis
image: redis:4.0
imagePullPolicy: Always
ports:
- containerPort: 6379
- name: nginx
image: nginx
imagePullPolicy: Always
ports:
- containerPort: 80
volumeMounts:
- mountPath: /etc/nginx/nginx.conf
name: nginx-conf-volume
subPath: nginx.conf
readOnly: true
- mountPath: /etc/nginx/conf.d/default.conf
subPath: default.conf
name: nginx-route-volume
readOnly: true
- mountPath: "/var/www/html"
name: mypd
readinessProbe:
httpGet:
path: /v1/hc
port: 80
initialDelaySeconds: 5
periodSeconds: 10
volumes:
- name: nginx-conf-volume
configMap:
name: nginx-config
- name: nginx-route-volume
configMap:
name: nginx-route-volume
- name: mypd
persistentVolumeClaim:
claimName: pvc
- spec.spec.containers.resources: VPA相关资讯,Pod提交时,透过VPA去设定该Pod的资源设置。
What is ClusterAutoscaler ?
Cluster层级的Scaler,当物件因资源不足而无法生成启动时,或者是丛集节点使用率过低时,ClusterAutoScaler会自动地去调节节点的数量。
How to use ClusterAutoscaler ?
这边以GCP为例
Creating a cluster with autoscaler
$ gcloud container clusters create cluster-name --num-nodes 30 \
--enable-autoscaling --min-nodes 15 --max-nodes 50 [--zone compute-zone]
- —num-nodes: 结点创建初始值,预设为3。
- --enable-autoscaling: 启动autoscaler与否。
- --min-nodes: node pool中最低的节点数。
- --max-nodes: node pool中最高的节点数。
Adding a node pool with autoscaling
$ gcloud container node-pools create pool-name --cluster cluster-name \
--enable-autoscaling --min-nodes 1 --max-nodes 5 [--zone compute-zone]
- —cluster: 丛集名称
Enabling autoscaling for an existing node pool
$ gcloud container clusters update cluster-name --enable-autoscaling \
--min-nodes 1 --max-nodes 10 --zone compute-zone --node-pool default-pool
Disabling autoscaling for an existing node pool
$ gcloud container clusters update cluster-name --no-enable-autoscaling \
--node-pool pool-name [--zone compute-zone --project project-id]
後记
今天我们了解了Kubernetes cluster在三种不同的层面分别使用的资源缩放策略,这也让我们在往後遇到不同的问题,能透过最为合适的方法去进行资源调配,节省资源的浪费。
Reference
https://www.servicemesher.com/blog/kubernetes-vertical-pod-autoscaler/
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
https://cloud.google.com/kubernetes-engine/docs/concepts/verticalpodautoscaler
https://cloud.google.com/kubernetes-engine/docs/how-to/cluster-autoscaler?hl=zh-tw
DAY11 - 进入後端,进入firebase世界!
在前十天,建立起前端专案的基本架构,接下来进入後端的世界,建立後端的基础,之後与前端专案对接。 什麽...
【D1】前言与规划
上次《Pyhon X 金融分析 X Azure》系列使用Azure去做简单的金融体验,这次就继续拓展...
Day8 GraphQL 介绍、在WordPress 上安装 WPGraphQL plugin
我们的系统架构很单纯,分为托管在 Vercel 上的 Next.js 前端,以及托管在 BlueHo...
[Day11] 函式 function
函式是 JavaScript 非常重要的特性,指的是将一或多段程序包起来,之後可以重覆使用。Java...
第十九天:初探 Gradle Plugins
Plugin 可以做什麽? 将 Plugin 套用於专案後,可以扩增专案的能力,它可以做到如: 扩充...