故事二十八:人口密度高的地区,每一户的所得总额是不是也比较高呢?
最近,有事没事就会逛逛open data的网站,我今天很幸运的看到了两个资料集:分别是
综合所得税所得总额全国各县市乡镇村里统计分析表 和 各乡镇市区人口密度 。
为了要实作inner join again,所以,我把两个资料先整理了一下。
接下来,就是实作联接(inner join)了。
1. 先汇入「纳税」的excel档。
2. 透过「新增」,汇入「人口」的excel档。
3. 开启「纳税」的功能选单,并将「人口」拉到编辑区。
4. 选择「纳税」的「县市乡镇合并」 = 「人口」的「区域别」,完成。
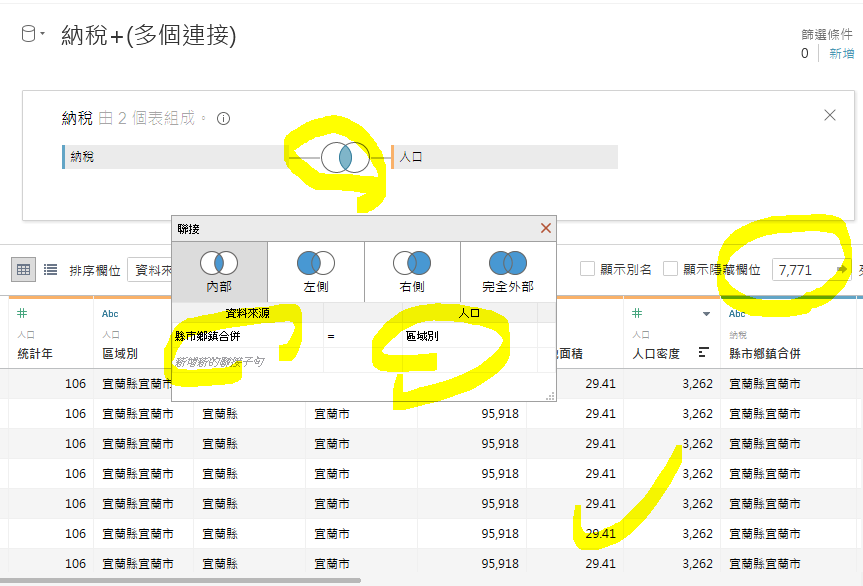
今天的主题是:「人口密度高的地区,每一户缴的所得总额是不是也比较高呢?」话不多说,先拉一个table出来比较。结果都是错的。哈哈!因为这两笔资料是透过inner join产生的,所以在栏位的应用上,还需要再调整一下。
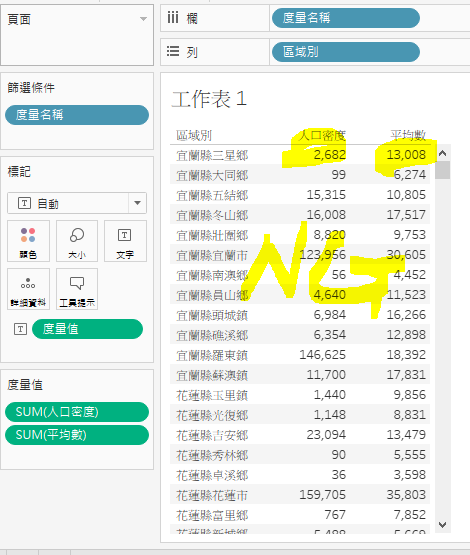
把那两个栏位的资料,从加总改成平均,人口密度正确了,只不过,每一户的所得平均,应该不是这样算的.....。
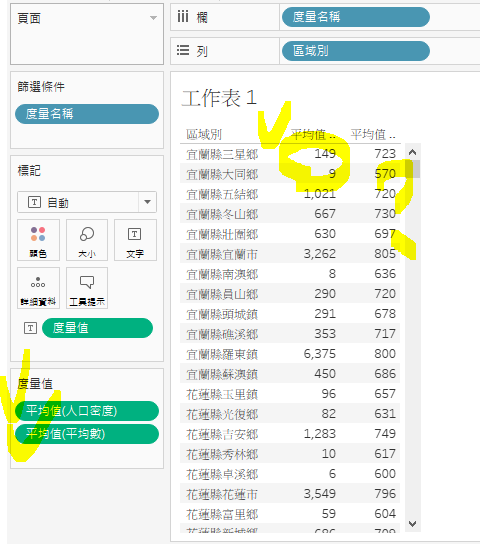
没关系,我们刚好练习一下,Tableau的LOD函式。
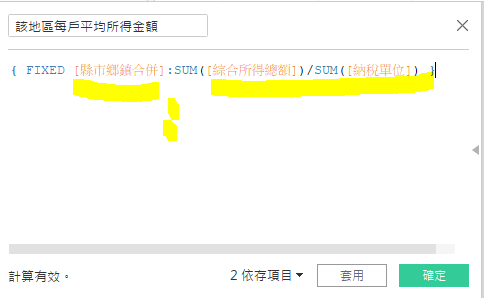
完成後如下图。
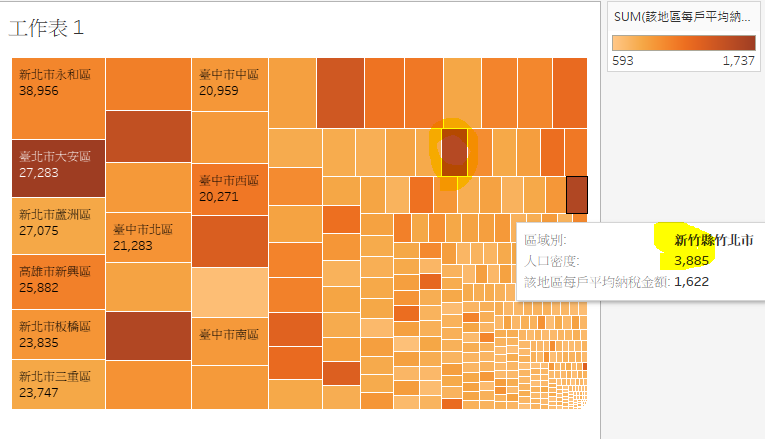
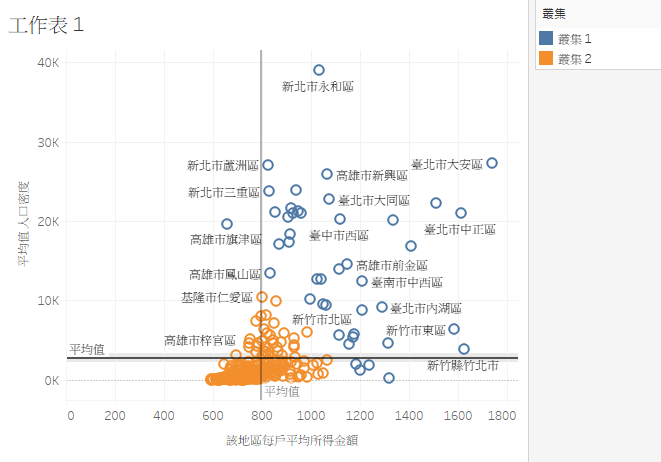
先看看,树状图。「台北市大安区」看来是人口密度高,又会赚钱的一区。不过,新竹县竹北市,感觉上生活品质应该不错,人口密度低,所得很高。
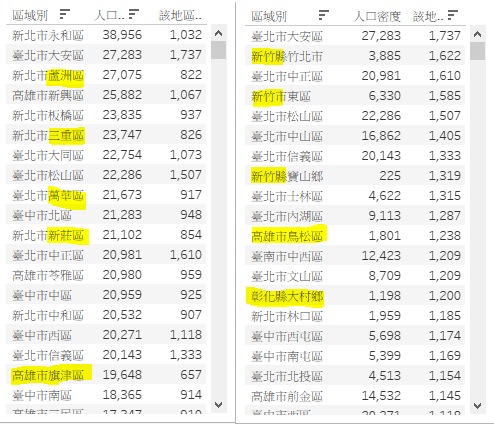
快速排序一下。嘿嘿嘿..... 这个结果,有点惊讶,但是却也不意外。有兴趣的人,自己研究研究。(如下图)
看到这种,有一些相关,可是,又好像不太相关的数据,那就尝试分群吧!
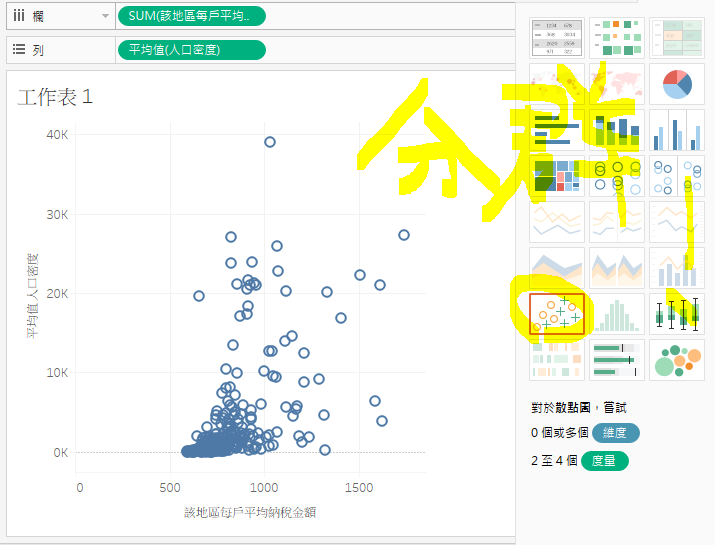
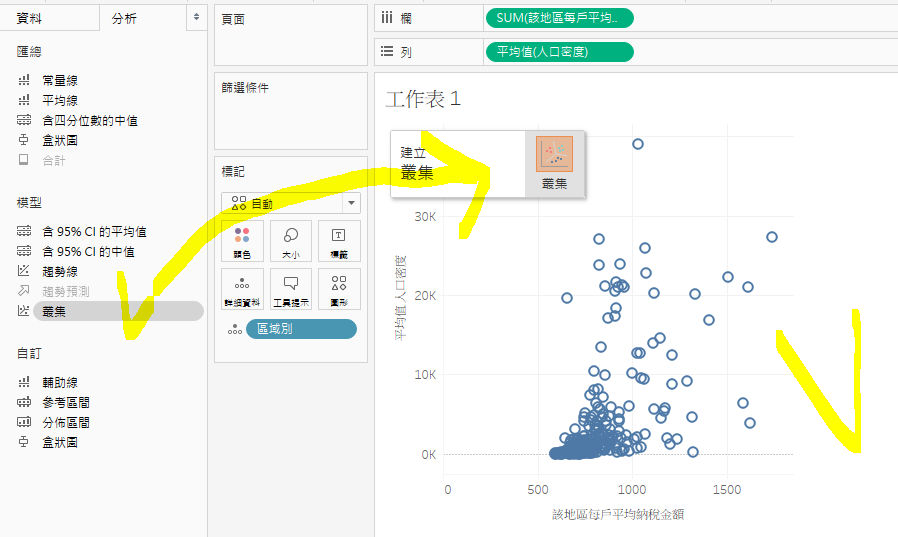
最後,可以透过「丛集」 -> 「描述丛集」以及「格式」 -> 「检视资料」, 细细研究一下那些在丛集1的地区哦!
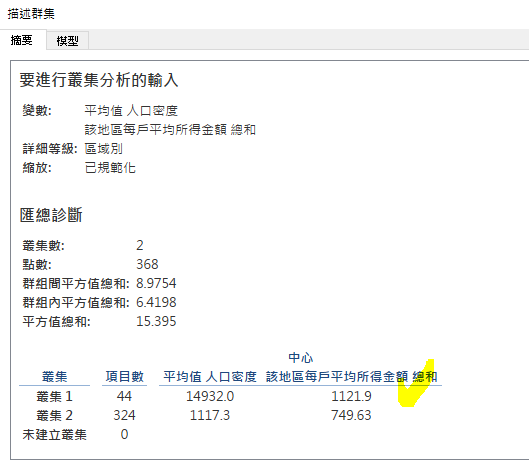
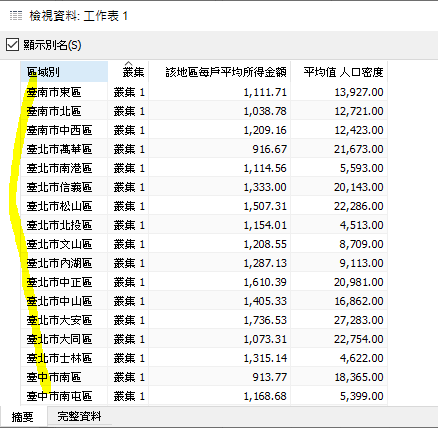
今天实作,成功。完成後如下图。
<<: Processing - Day 28 数学好棒棒 第三篇章
【Day17】期间限定:函式的参数
函式会将参数传入函式里面,让它们成为函式里的变数,让程序码去做运算。参数只能在函式里刷存在感(期间...
DAY25 在React中加入CSS
今天要介绍在React Component中加入CSS的方式。 用字串的方式为className命名...
事件监听的this:「这个」到底是哪一个?
欧阳克是谁杀的? 这个this是谁?要看凶手是谁而定! 前面有提到,这个e是在当事件发生时,事件处...
Day 19-制作购物车系统之将资料汇入脚本
今天要把前面几天的资料(包括MongoDB连线、产品等)汇入到脚本 以下内容有参考教学影片,底下有附...
【从零开始的 C 语言笔记】第十一篇-指标
不怎麽重要的前言 上一篇我们总结了scanf的观念,也出了一个小小的作业希望让大家熟悉一下scanf...