Day29 - 集成学习 (ensemble learning) part2
今天要继续介绍另外两个集成学习的方法 max-out unit 结合与内插(interpolation)。
max-out unit 的结合方式如图 1。为了使三种模型最後输出的向量维度一致,做了些以下的修改:
- RNN: 移除输出层(5个神经元的全连接层)
- CNN: 将输出层修改为60个神经元 activation function 为 tanh 的全连接层
- MLP: 移除输出层(5个神经元的全连接层)并将隐藏层修改为60个神经元 activation function 为 tanh 的全连接层
经过上述的修改後,三种模型具有相同维度的输出向量(60维)。接着我们使用 max-out unit 从三个60维的向量中选出最大值并将此经过挑选後的60维向量传递至输出层中(dim=5, softmax)。
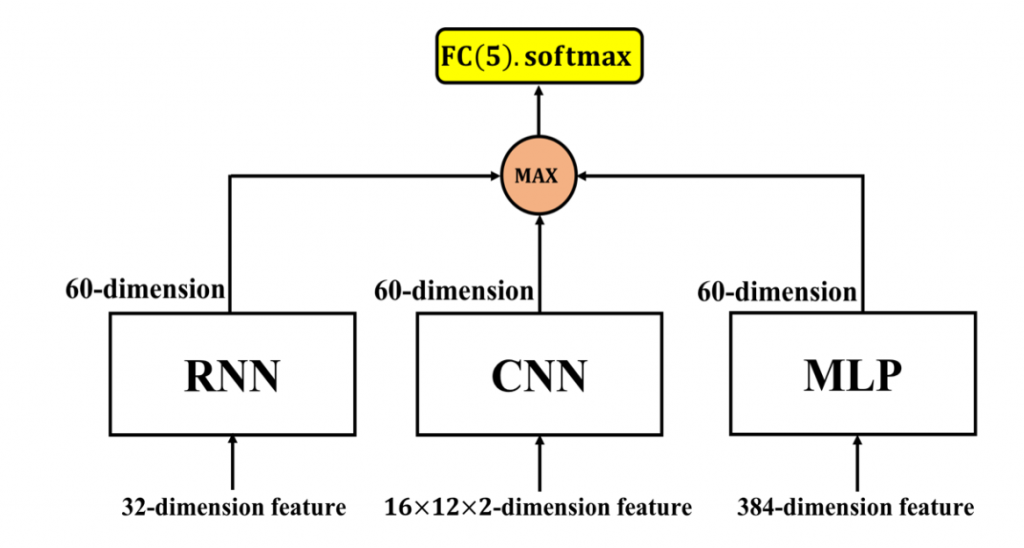
图 1: 透过 max-out unit 结合静态(MLP、CNN)、动态模型(RNN)
分类结果如表 1:
| / | A | E | N | P | R | UA recall |
|---|---|---|---|---|---|---|
| A | 387 | 111 | 63 | 29 | 21 | 63.3% |
| E | 285 | 831 | 308 | 42 | 42 | 55.1% |
| N | 736 | 966 | 2,639 | 719 | 317 | 49.1% |
| P | 8 | 9 | 41 | 144 | 13 | 67.0% |
| R | 108 | 83 | 161 | 120 | 74 | 13.6% |
| Avg.recall | - | - | - | - | - | 49.6% |
表 1: Maxout-unit 结合分类结果混淆矩阵
集成学习的最後一部份我们采用内插的方式做结合
其中,、
与
分别为三种模型(LSTM-RNN with attention mechanism、multi-
scale CNN with attention mechanism 及 MLP)对於测试集所输出的事後机率, 即为内插後的事後机率 (
)。
结果如下表2:
| / | A | E | N | P | R | UA recall |
|---|---|---|---|---|---|---|
| A | 382 | 102 | 64 | 29 | 30 | 63.2% |
| E | 281 | 811 | 301 | 40 | 75 | 53.8% |
| N | 713 | 853 | 2,599 | 737 | 475 | 48.3% |
| P | 8 | 6 | 39 | 148 | 14 | 68.8% |
| R | 107 | 75 | 140 | 123 | 101 | 18.5% |
| Avg.recall | - | - | - | - | - | 50.5% |
表 2: 内插结合分类结果混淆矩阵
从所有模型的结果来说,rest 类别的分类是最困难的部份。与其它四类(angry、emphatic、neutral、positive)不同的是,rest 类是由所有不属於其它四类的类别所组成的。因此,rest 类别资料的特徵具有高度的差异性,使得神经网路的学习变得更加困难。
<<: 【Day 26】SwiftUI - Drawing and Animation
Day18: 【TypeScript 学起来】Narrowing Part 2
好 继续来笔记 Narrowing, 还有哪些方法能进行 narrow 型别呢。 若有错误,欢迎留...
IT铁人第28天 Elasticsearch 使用python查询资料 Aggregations:Sum/Value Count
今天文章的内容是Sum(总和)跟Value Count(数量计算) 今天的示范资料 Sum Sum大...
Day08 - [丰收款] 十六进位格式的後续探讨,字串传输容量倍增了!
延续昨天的十六进位转换,还有件重要的事。 隐藏的问题,容量变大了 若是某个需求,资料传送过程中不允许...
Day05-Kubernetes 那些事 -基本观念与操作
前言 接下来就正式进入本系列文的重头戏:Kubernetes,Kubernetes 可以说是近期快速...
[Tableau Public] day 6:尝试制作不同种类的报表-3
第六天,星期一,打起精神fighting~ 参考的资料来源一样是 day 4 的「Our World...