DAY29: 最後倒数
已经迈向第29天了,但我还在熟悉Nodejs的表面的感觉,
想在这倒数第二天做出有点技术的东西,
可是依我现在对Nodejs还没有这麽熟悉上手,
所以今天这篇我参考了一个网站作者写的程序来修改使用,
在此真的很感谢这位作者,在结尾也会放上网页连结。
今天要实作的就是爬虫,其实自己尝试了几天,但是依然做不出我想要的结果,
或许是我技术不成熟又选了网页结构复杂的网站想抓取我想要的资讯。
先跟各位介绍原本我想要爬取台风资讯的。

尝试多次後,只显示了一部分结果出来而已(哭…),
所以就换了一个网页结构相对简单的网站来抓取。选择的是三立新闻网,
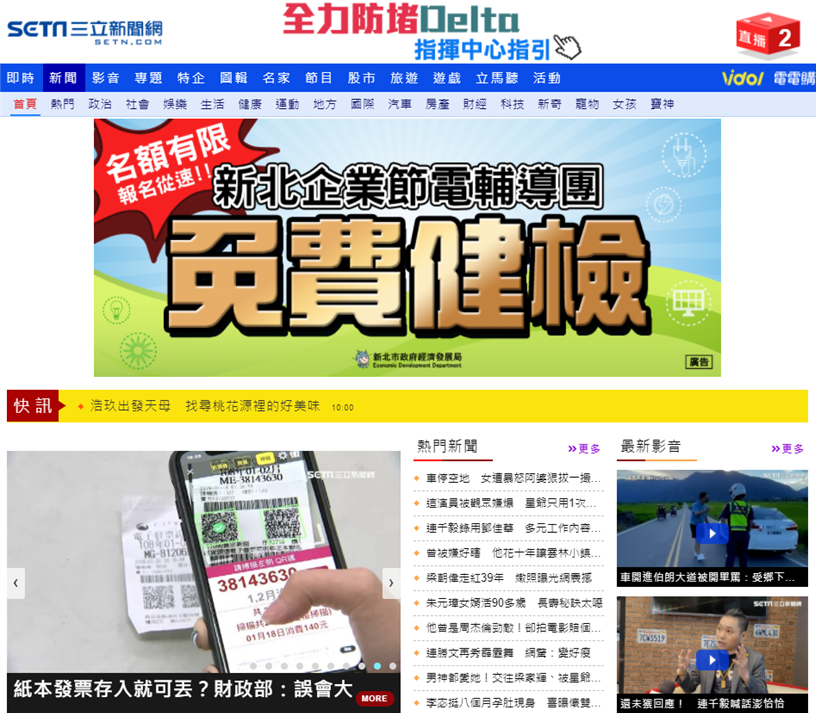
而我要抓取的部分就是热门新闻这个部分,内容包括新闻标题与其连结。
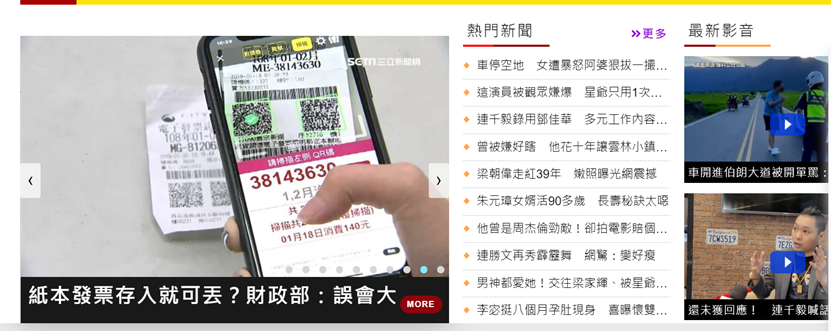
首先,先分析页面,[右键]->[检查],找到热点新闻的区块。
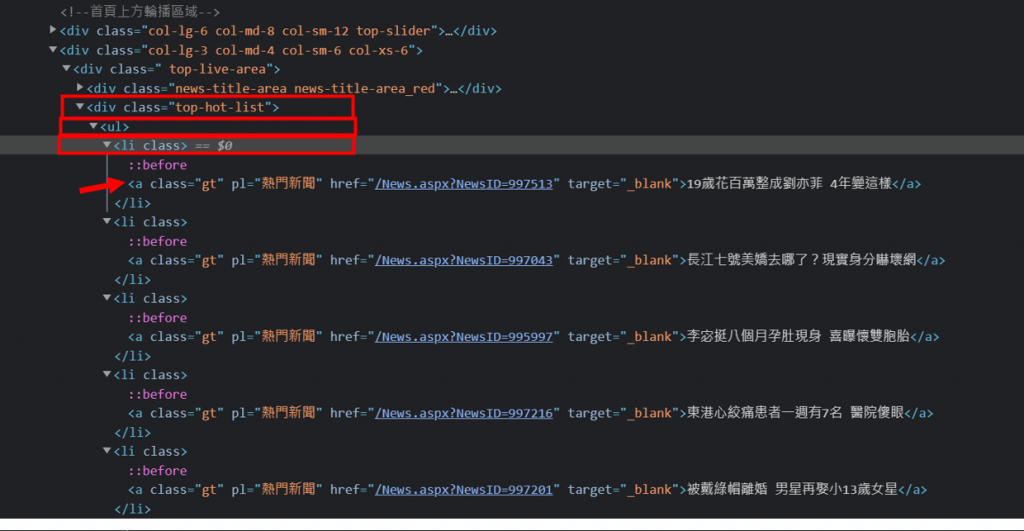

而我要抓取的就在div.top-hot-list 中<ul>里面所有的<li>标签的<a>内容。
今天要用到的第三方模组有三个,
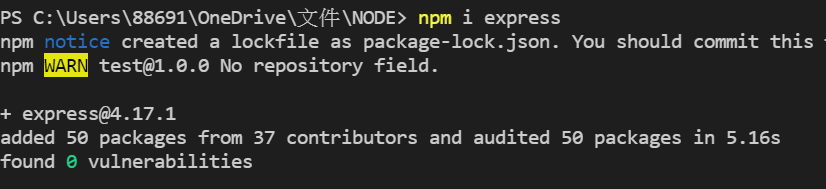
第一个先安装express模组,在终端机输入 npm i express
第二个安装 superagent 模组,在终端机输入 npm i superagent
第三个安装cheerio模组,在终端机输入 npm i cheerio。
安装成功後,分别导入express、superagent、cheerio模组。
//导入模组
const express=require("express");
const app=express();
const superagent=require("superagent");
const cheerio=require("cheerio");
首先使用express模组来建立服务器,
//建立服务器
app.get("/",async(req,res,next)=>{
res.send(Keynews);
});
app.listen(3000);
再使用supperagent模组的get(),
放入指定的网址(三立新闻网),当成功实资料会指定给res。
//三立新闻网网址
superagent.get("https://www.setn.com/").end((err,res)=>
{
Keynews=getKeynews(res);
});
再来使用cheerio模组取得要抓取的资料,这个在爬虫系统中,
除了一些Node核心模组外,cheerio也是重要的辅助模组之一。
先给予一个空的阵列名为Keynews,以便储存数据。
并使用cheerio模组$的load()寻找在我指定的项目中要抓取的资料,
而我正是需要在div的top-live-area框架下面的<ul>之中的<li>标签下的<a>的标题与连结。
取得资料後都存到Keynews阵列中,并回传。
//开始取的资料
let getKeynews=(res)=>
{
let Keynews=[]; //设定一个空阵列
let $=cheerio.load(res.text); //$为cheerio.load()
// $("url#list-unstyled li span").each((idx,ele)=>
$("div.top-live-area ul li a").each((idx,elem)=>
{ //指定项目
let allnews={
title:$(elem).text(), //抓取新闻标题
href:$(elem).attr("href")//抓取新闻连结
};
Keynews.push(allnews);
});
return Keynews;
}
输入 http://127.0.0.1:3000/, 查看结果
执行结果:
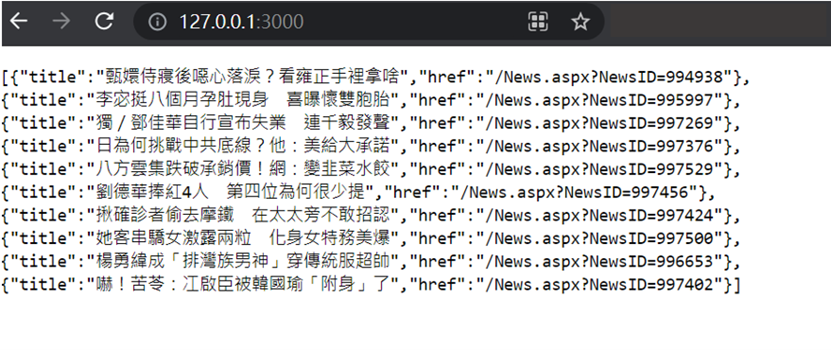
登愣!!!这样一个简易爬虫系统就完成了!
虽然没有很专业的爬虫,但是能抓到资料,我也觉得很满足了,
未来在继续学习的话,相信我会再做出更专业的爬虫系统的。
参考资料:
https://codertw.com/ios/20272/
<<: Day 26: 策略和层级、业务规则 (待改进中... )
DAY 18- 杂凑函数 SHA-256
「SHA SHA, SHA SHA SHA SHA」 SHA-256是SHA-2家族里输出位元为25...
(笔记D1) Spring MVC 框架
1-1 Spring MVC 特质 功能建构在 Servlet、JSP 规格基础上面发展,必须透过 ...
【PHP Telegram Bot】Day27 - 防雷机器人(1):让发出去的讯息隐藏吧
有时候看动画或小说看到很劲爆的地方,很想讲但又不能明讲,有防雷机器人的话就会很方便 来做一个可以用...
[Day12] 让 Linux 的 systemd 帮我们管理 API 程序
昨天我们成功的把 API 程序布署到 GCP 的 VM 上了。不过,我们有一个问题:只要跑了 .NE...
【Day 21】Hook 04:useContext
useContext useContext 本质上是 Context 的语法糖, 精简了 Conte...