[Day 28] 储存训练好的模型
储存训练好的模型
今日学习目标
- 使用 pickle + gzip 储存模型
- 将训练好的模型打包并储存
- 载入储存的模型
- 读取打包好的模型并预测
前言
今天的教学内容要教各位如何将训练好的模型储存,并提供下一次载入模型和预测。在本系列的教学中介绍了许多 Sklearn 的模型演算法。当模型训练好了,可以将训练结果储存起来,并建立一个 API 接口提供模型预测。
模型储存方法
常见的储存模型的套件有 pickle 与 joblib。其中在 [Day 20] 机器学习金手指 - Auto-sklearn 最後有使用 joblib 来储存模型,操作方法也非常简单。然而在今天的教学中则使用另一种方法 pickle 来储存模型。由於 pickle 储存模型後容量可能会有好几百 MB 因此建议可以透过 gzip 来压缩模型并储存。另外在 Python 官方文件中有警告绝对不要利用 pickle 来 unpickle 来路不明的档案。因为透过 pickle 打包模型会有安全性疑虑,包括 arbitrary code execution 的问题,详细内容可以参考这篇文章。如果要追求执行速度与安全性,建议可以采用 JSON 格式来存取模型的参数与设定。
1) 载入资料集
今日的范例还是拿鸢尾花朵资料集进行示范。首先我们先载入资料集并进行资料的切割。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
iris = load_iris()
df_data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= ['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species'])
df_data
2) 切割训练集与测试集
from sklearn.model_selection import train_test_split
X = df_data.drop(labels=['Species'],axis=1).values # 移除Species并取得剩下栏位资料
y = df_data['Species'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
print('train shape:', X_train.shape)
print('test shape:', X_test.shape)
训练模型 - XGBoost
XGBoost 模型是目前最热门的演算法模型之一,详细的内容可以参考 [Day 15] 机器学习常胜军 - XGBoost。里面会有介绍详细的模型说明与手把手实作。当然大家也可以试着用其他 Sklearn 的模型训练看看,一样可以透过 pickle 来储存训练好的模型。
from xgboost import XGBClassifier
# 建立 XGBClassifier 模型
xgboostModel = XGBClassifier(n_estimators=100, learning_rate= 0.3)
# 使用训练资料训练模型
xgboostModel.fit(X_train, y_train)
# 使用训练资料预测分类
predicted = xgboostModel.predict(X_train)
储存 XGboost 模型
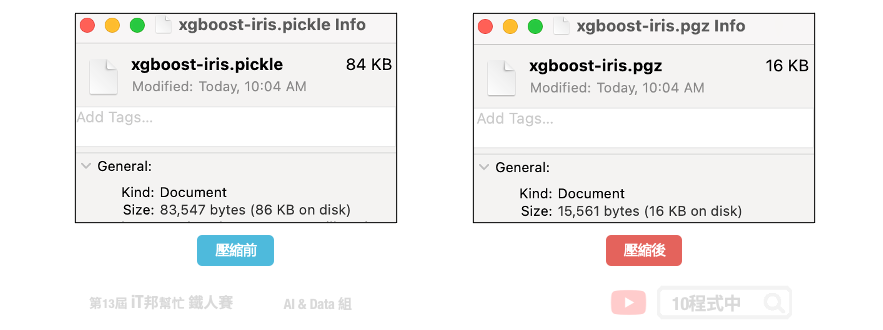
大家可以观察 .pickle 与 .gzip 两种不同副档名储存结果档案大小有何差别?
1. 使用 pickle 储存模型
import pickle
with open('./model/xgboost-iris.pickle', 'wb') as f:
pickle.dump(xgboostModel, f)
2. 使用 pickle 储存模型并利用 gzip 压缩
import pickle
import gzip
with gzip.GzipFile('./model/xgboost-iris.pgz', 'w') as f:
pickle.dump(xgboostModel, f)
载入 XGboost 模型
试着载入两种不同格式的模型,并预测一笔资料。注意模型预测输入必须为 numpy 型态,且须为二维阵列格式。
1. 载入 gzip 格式模型
import pickle
import gzip
#读取Model
with gzip.open('./model/xgboost-iris.pgz', 'r') as f:
xgboostModel = pickle.load(f)
pred=xgboostModel.predict(np.array([[5.5, 2.4, 3.7, 1. ]]))
print(pred)
2. 载入 pickle 格式模型
#读取Model
with open('./model/xgboost-iris.pickle', 'rb') as f:
xgboostModel = pickle.load(f)
pred=xgboostModel.predict(np.array([[5.5, 2.4, 3.7, 1. ]]))
print(pred)
双十1010连假愉快
Reference
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: DAY25 把这个Google maps 放在 APP 上
Day 0x13 UVa299 Train Swapping
Virtual Judge ZeroJudge 题意 输入火车的排列状态,输出需要交换多少次以排好...
[Day12] Android - Kotlin笔记:JetPack - Fragments在Navigation中的参数传递(Safe Args)
Fragments在Navigation中的参数传递 - SafeArgs 继上篇我们得知如何运用N...
申请海外新创加速器好难
今年申请了两个加速器:Y Combinator、Berkley SkyDeck 这两个加速器在国际上...
微自干的旅程没有结束
微自干的旅程没有结束,但是每日连载的部分先不要。 进入正题 如果有关看我隔壁棚的轻松小品 (?) ...
Day28 go-elasticsearch(二)
今日我们将要使用go-elasticsearch来搭配telegram完成讯息发送。 目标 前面章节...