[Day 27] 机器学习常犯错的十件事
机器学习常犯错的十件事
今日学习目标
- 探讨机器学习常犯的十件错误
前言
人工智慧近年来成为任何产业热门的话题之一,各公司积极地导入机器学习技术协助产业 AI 化。例如:智慧医疗、智慧交通、智慧制造......等。正是因为 AI 技术的创新与普及,训练机器学习模型再也不是理工背景的人才能做的事。此外随着 Python 开发社群茁壮,许多开源的 AI 套件如雨後春笋般的出现大大降低了机器学习建模的门槛。在今天的内容中我想藉由铁人赛来跟大家分享机器学习常犯错的十件事,并且从资料面与模型面的角度来探讨机器学习应该注意的几件事。尤其是在初学阶段,因缺乏经验往往会犯一些无可避免的错误。所以这篇文章将点出十个机器学习中常犯的隐形错误。
-
资料面
- 资料收集与处理不当
- 训练集与测试集的类别分布不一致
- 没有资料视觉化的习惯
- 使用 LabelEncoder 为特徵编码
- 资料处理不当导致资料泄漏
-
模型面
- 仅使用测试集评估模型好坏
- 在没有交叉验证的情况下判断模型性能
- 分类问题仅使用准确率作为衡量模型的指标
- 回归问题仅使用 R2 分数评估模型好坏
- 任何事情别急着想用 AI 解决
1. 资料收集与处理不当
机器学习首要的步骤是定义问题,当确定目标与方向後即可开始搜集资料。相信大家都知道现实生活中的资料得来不易,即使从资料库取得了这些资料後我们还需要花大量的时间进行资料清洗。所谓的资料清洗是资料库当中可能会有缺失值,例如:NA、Inf、NaN、NULL。
- NA:表示缺失值,是 Not Available 的缩写。
- Inf:表示无穷大,是 Infinite 的缩写。
- NaN:表示非数值,是 Not a Number 的缩写。
- NULL:表示空值,即没有内容。
当资料都完成了前处理後,即可开始建立模型与评估模型。但是当训练出来的模型表现不好有很多的因素。大家最常做的是替换模型演算法,或是尝试不同的模型超参数取得一个最佳的结果。但是在进行这些做之前,建议大家先把关注的点回到资料处理面。模型训练不好的其中一个因素是资料的标签收集不当。Landing.ai 执行长吴恩达也曾经说过当一个小资料集存在着错误标签时,模型很难给出一个正确的输出。因为资料间夹带了杂讯往往会使的模型存在着一些偏差,导致训练结果不稳定。因此笔者建议模型训练不好的时候,可以回头观察资料是否存在一些错误。而不是一昧的调整模型演算法与超参数。
2. 训练集与测试集的类别分布不一致
在分类的资料中,初学者常见的错误是忘记使用分层抽样 (stratify) 来对训练集和测试集进行切割。当测试集的分布尽可能与训练相同情况下,模型才更有可能得到更准确的预测。然而在分类的问题中,我们必须更关注每个类别的资料分布比例。以下举个例子:假设我们有三个标签的类别,而这三个类别的分布比例分别为 4:3:3。同理我们在进行资料切割的时候必须确保训练集与测试集需要有相同的资料分布比例。
大家应该都使用过 Sklearn 的 train_test_split 进行资料切割。在此方法中 Sklearn 提供了一个 stratify 参数达到分层随机抽样的目的。特别是在原始数据中样本标签分布不均衡时非常有用,一些分类问题可能会在目标类的分布中表现出很大的不平衡:例如,负样本与正样本比例悬殊(信用卡盗刷预测、离职员工预测)。以下用红酒分类预测来进行示范,首先我们不使用 stratify 随机切割资料并查看资料切割前後的三种类别比例。
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
X, y = load_wine(return_X_y=True)
# 查看全部资料三种类别比例
pd.Series(y).value_counts(normalize=True)
# 全部资料三种类别比例
1 0.398876
0 0.331461
2 0.269663
dtype: float64
# 实验一: 不使用 stratify 进行切割资料
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 查看训练集三种类别比例
pd.Series(y_train).value_counts(normalize=True)
# 查看测试集三种类别比例
pd.Series(y_test).value_counts(normalize=True)
# 训练集三种类别比例
1 0.390977
0 0.330827
2 0.278195
dtype: float64
# 测试集三种类别比例
1 0.511111
0 0.266667
2 0.222222
dtype: float64
从上面切出来的训练集与测试集可以发现三个类别的资料分布比例都不同。因此我们可以使用 stratify 参数再切割一次。
# 实验二: 使用 stratify 进行切割资料
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
# 查看训练集三种类别比例
pd.Series(y_train).value_counts(normalize=True)
# 查看测试集三种类别比例
pd.Series(y_test).value_counts(normalize=True)
# 训练集三种类别比例
1 0.400000
0 0.333333
2 0.266667
dtype: float64
# 测试集三种类别比例
1 0.398496
0 0.330827
2 0.270677
dtype: float64
我们可以发现将 stratify 设置为目标 (y) 在训练和测试集中产生相同的分布。因为改变的类别的比例是一个严重的问题,可能会使模型更偏向於特定的类别。因此训练资料的分布必须要与实际情况越接近越好。
3. 没有资料视觉化的习惯
资料视觉化的好处多多,在本系列文章 [Day 3] 你真了解资料吗?试试看视觉化分析吧! 与 [Day 22] Python 视觉化解释数据 - Plotly Express 讲解了许多 Python 资料视觉化的技巧。资料视觉化可以帮助我们分析与统计资料的型态,往往有好的资料清洗与前处理对模型预测结果会有大幅的提升。有兴趣的读者可以参考安斯库姆四重 (Anscombe’s quartet)。他主要是是透过四个小资料集并透过视觉化与统计来观察,并说明在分析数据前先绘制图表的重要性,以及离群值对统计的影响之大。
4. 使用 LabelEncoder 为特徵编码
通常我们要为类别的特徵进行编码,直觉会想到 Sklearn 的 LabelEncoder。但是如果一个资料集中有多个特徵是属於类别型的资料,岂不是很麻烦?必须要一个一个呼叫 LabelEncoder 分别为这些特徵进行转换。如果你看到这边有同感的,在这里要告诉你事实并非如此!我们看看 在官方文件下 LabelEncoder 的描述:
This transformer should be used to encode target values, i.e. y, and not the input X.
简单来说 LabelEncoder 只是被用来编码输出项 y 而已的!你还在用它来编码你的每个 x 吗?(晕
那麽我们该用什麽方法来编码有顺序的类别特徵呢?如果你仔细阅读有关编码分类特徵的 Sklearn 用户指南,你会看到它清楚地说明:
To convert categorical features to integer codes, we can use the OrdinalEncoder. This estimator transforms each categorical feature to one new feature of integers (0 to n_categories - 1)
看到这边大家应该知道阅读官方文件的重要性吧!官方文件中建议 x 项的输入特徵可以采用 OrdinalEncoder 一次为所有特徵依序做 Label Encoding。OrdinalEncoder 编码器的使用方式如下:
from sklearn.preprocessing import OrdinalEncoder
enc = OrdinalEncoder()
X = [['Male', 1], ['Female', 3], ['Female', 2]]
enc.fit(X)
print(enc.categories_)
enc.transform([['Female', 3], ['Male', 1]])
[array(['Female', 'Male'], dtype=object), array([1, 2, 3], dtype=object)]
array([[0., 2.],
[1., 0.]])
以上的范例是 X 有三笔资料,每笔资料都有两个特徵。我们可以发现第一个特徵是性别 Male 与 Female,因此 OrdinalEncoder 会依造字母开头做排序 Female 编码为 0 而 Male 编码为 1。另外第二个特徵为数字 1、2、3,同理依序为他们编码成 0、1、2。只需阅读官方文档和用户指南,你就可以了解很多关於 Sklearn 的知识!是不是很棒~
5. 资料处理不当导致资料泄漏
资料泄漏 (data leakage) 是个隐形杀手,它会在不知不觉中影响模型预测结果。其发生的时机在於你在训练过程中,不应该将测试的资料的资讯泄漏到训练过程中。它会造成模型给出一个非常乐观的结果,即使在交叉验证中也是如此,但在对实际新数据进行测试时表现会非常地糟糕。
资料泄漏最常发生於资料前处理的阶段,尤其是当你的训练集和测试集尚未切割的时候。Sklearn 提供了许多资料前处理的方法,例如: 缺失值补值(imputers)、正规化 (normalizers)、标准化(standardization)以及对数(log) 转换...等。这些转换器都会依赖於你输入资料的分布,并依照此分布做相对应的拟合。
举例来说,我们在做标准化时(StandardScaler)透过从每笔资料中减去平均值并将其除以标准偏差来获得缩放後的数据。我们使用 fit() 方法在所有资料集 X 上做转换,并使得转换器学习每个特徵的整个分布的平均值和标准差。这些资料转换後如果再将这些数据拆分为训练集和测试集,则训练集会受到污染。因为 StandardScaler 从实际分布中泄露了测试集重要讯息,一般来说我们不能将测试集的分布情况与训练集混在一起。虽然我们希望训练集的分布与实际测试集的分布要越接近越好,因为使得模型表现结果稳定。
虽然我们把测试集与训练集混在一起并做转换,这一步骤对我们来说可能没什麽。但是对於 Sklearn 强大的演算法,可能会透过这个遗漏测试集的分布的讯息把模型拟合的很好。届时模型训练完成後,测试集不够新颖,无法在实际看不见的数据上测试模型的性能。
最简单的解决办法,就是不要使用 fit() 一次转换所有的资料。在做任何资料转换之前要先确保训练集与测试集已经完整地被切开。即使切开後也不要再拿测试集呼叫 fit() 或 fit_transform(),这一样会导致相同问题发生。因为训练集和测试集必须进行相同的转换,依照官方的范例我们必须先使用 fit_transform() 在训练集上进行拟合与转换。这确保了转换器仅从训练集学习,从中找出参数例如平均值与变异数并同时对其进行变换。接着使用 transform() 方法在测试资料上进行转换,根据从训练数据中学到的讯息进行转换。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=44)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
更强大的解决方案是使用 Sklearn 内建的 pipeline,它能够保护模型免於资料泄漏的问题。此方法能够确保训练资料仅参与转换拟合与模型训练,而测试资料仅用於计算并验证模型。
6. 仅使用测试集评估模型好坏
如果你的测试资料 R2 score 得到了 0.85 就代表很好了吗?不尽然!尽管有高的测试分数通常意味着模型表现佳,但在解释测试结果时仍有一些重要的注意事项。首先最重要的,无论分数值如何测试集的分数一定要与训练集相比较才能确保模型训练好与坏。当你的模型训练集分数高於测试集的分数,并且两者都足够高以满足专案的目标期望时这代表你训练了一个好模型。然而这并不意味着训练和测试分数之间的差异越大越好。举个例子,若训练集的 R2 score 为 0.85 测试集为 0.8 即代表模型既不过度拟合(overfit)也不欠拟合(underfit)。但是如果训练集 0.9 测试集 0.8 的时候,你的模型就是过拟合。其原因是该模型没有在训练期间进行泛化,而是记住了一些训练数据,从而导致测试分数低得多。
在大多数任务中你将会看到许多人使用 tree-based 模型或是整体学习模型 (ensemble models)。例如在随机森林演算法当中如果它们的树深度太深,往往会获得非常高的训练分数,从而导致过度拟合。另外也有测试集的分数比训练集高的情况,若发生此情况时通常都会感觉是不是做错了什麽。这种情况的主要原因是资料泄漏,也就是上一节我们讨论的情况。或是你的测试资料笔数太少,没办法足以验证模型好坏。
另外有时候我们也会得到在训练集有很好的表现但测试集无敌差的情况。当训练和测试分数差异很大时,问题往往与测试集有关而不是过度拟合。这时候你可能要检查资料预处理的方式是否一致 (像是取 log 或 scale),或是只是忘记对测试集做转换处理。
这里做一个小结,总之在训练好模型时请仔细检查训练和测试分数之间的差距。并且可以透过此评估方式检视模型是否过拟合,同时也能进行模型条参或是选择最佳的资料预处理方式。并为最终的模型做最佳的准备。
7. 在没有交叉验证的情况下判断模型性能
我想大家应该都熟练掌握了 overfitting 这个议题。这是机器学习中一个迫切问题,并已经设计了无数个方法来解决它。最基本的方法是将一部分数据作为测试集来模拟和测量模型在看不见的数据上的性能。但是我们可以调整模型的超参数,直到模型在该特定测试集上达到最高分数,这又意味着某种含义的过度拟合。因此我们可以会将完整数据的另一部分作为验证集再次解决这个问题。模型将在训练数据上进行训练,并在验证集上微调其参数,并在测试集上进行最终评估。
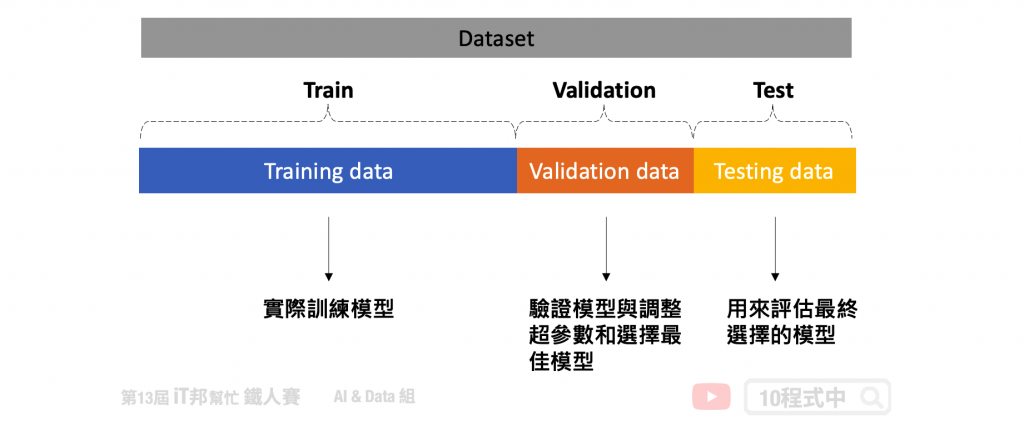
但是将我们宝贵的数据分成三组意味着模型可以学习的数据量更少。此外模型的整体预测性能将取决於那对特定的训练集和验证集。因此在进行机器学习时最常使用 K-Fold cross-validation 解决上述问题。详细内容可以参考我的前两天文章[Day 25] 交叉验证 Cross-Validation 简介以及[Day 26] 交叉验证 K-Fold Cross-Validation。根据我们设定的 K 值,可以完整的将数据被分成 K 组 folds,对於每个 folds 每次模型训练会把 K-1 组作为训练集,而剩下的被归类为验证集。当模型交叉验证结束後,训练集所有资料会被完整的训练。

8. 分类问题仅使用准确率作为衡量模型的指标
在预设的情况下所有 Sklearn 分类器在呼叫 score() 函数时都使用准确度作为评分方法。由於准确率的计算方式简单与容易理解,因此经常会看到初学者广泛使用它来判断其模型的性能。不幸的是这种一般准确率的评估方式只对类别平衡的二元分类问题有用。
然而在其他的状况下它是一个误导性的指标,即使是表现最差的模型也可能背後隐藏着高准确度的分数。举例来说有个侦测垃圾邮件的模型它的准确率 90%,但是实际上它根本无法侦测到垃圾邮件。这是为什麽?由於垃圾邮件并不常见,分类器可以检测所有非垃圾邮件,即使分类器完全无法达到其目的这也可以提高其准确性。因为这个分类器仅可以分类这些正常邮件,稀少的垃圾邮件根本变认不出来。
对於多元类分类的问题更是应该注意你的模型评估指标。如果达到 80% 的准确率,是否意味着模型在预测类别1、类别2、类别3甚至所有类时一样准确呢?一般的准确率永远无法回答此类问题,但幸运的是其他分类指标提供了更多的讯息指标。它就是混淆矩阵(confusion matrix)。
from sklearn.metrics import confusion_matrix
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
confusion_matrix(y_true, y_pred)
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])
组成混淆矩阵的四个元素分别有 TP、TN、FP、FN。基本上混淆矩阵会拿这四个指标做参考,同时算出来的分数也更能去评估你的模型训练的结果。此外我们可以利用混淆矩阵来计算 Precision、Recall、Accuracy 等分数。
- TP(True Positive): 正确预测成功的正样本,例如真实答案(Ground True)是猫,成功的把一张猫的照片预测成猫,即为TP
- TN(True Negative): 正确预测成功的负样本,成功的把一张狗的照片标示成不是猫,即为TN
- FP(False Positive): 错误预测成正样本,实际上为负样本,例如:错误的把一张狗的照片预测成猫
- FN(False Negative): 错误预测成负样本,实际上为正样本,例如:错误的把一张猫的照片预测成不是猫
9. 回归问题仅使用 R2 分数评估模型好坏
在预测连续性数值输出的回归模型中,大家往往会直接呼叫模型提供的评估方法直接计算 score。然而这个分数在回归模型中是计算 R2 分数,又称判定系数 (coefficient of determination)。所谓的判定系数是输入特徵 (x) 去解释输出 (y) 的变异程度有多少,其计算公式是:回归模型的变异量 (SSR)/总变异量 (TSS) 。用以下变异数分析表(ANOVA table)来说 TSS 就是计算总变异,把每个实际的 y 减去平均数的平方加总起来。而 SSR 就是把所有的模型预测 y 减去平均数的平方加总起来。如果 R2 分数很高越接近 1,表示模型的解释能力很高。
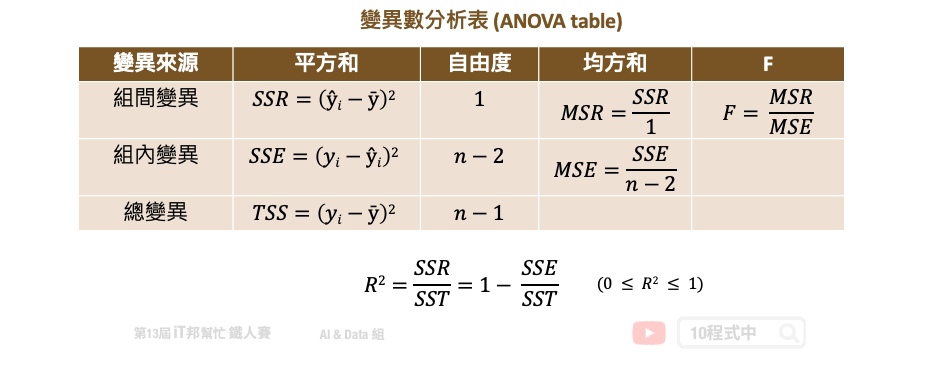
在学术研究上最直觉的观念是 R2 分数愈接近 1 越好,也有些人透过一些手段来制造 R2 分数很高的假象,详细内容可以参考这篇文章。其实只透过 R2 个评估指标就来决定一个模型的好坏是不太好的习惯。更进一步可以使用 MSE、MAE 等残差的评估值标来看每笔资料实际值与预测值的误差。或是使用相对误差来观察预测模型的可信度。此外笔者还建议可以试着把每笔资料的真实 y 与模型预测的 ŷ 绘制出来,若呈现一条明显的由左下到右上斜直线,则表示模型所预测的结果与真实答案很相近。

10. 任何事情别急着想用 AI 解决
近几年 AI 的发展想必大家有目共睹,从影像识别到物件辨识的技术有着重大的进展。此外 2016 年 Google Deepmind 团队的 AlphaGo 首度打败人类,这也在人机对弈上开启了一项重要的里程碑。甚至在自然语言方面,归功於新的模型架构与硬体资源的进步,使得自然语言有重大的突破。看到这麽多 AI 的美好让大家再次对深度学习点燃希望!只不过 AI 并非万能,切记!所有的问题并不是将资料收集好,并将资料丢给电脑学习就会得到你想要的结果。大家也许会陷入「为 AI 而 AI」 的迷思,很多的任务其实透过具有规则的专家系统或是传统演算法就可以达到很不错的结果。再者我们都对 AI 的技术感到特别欢喜与期待,但是 AI 的黑盒子人类往往不知道模型下一步会产生什麽不可预期的结果。其实 AI 有很多的限制与挑战,除了建立机器学习模型以外,我们更需要关注的是模型在想什麽。可解释人工智慧必然是我们要探讨的一段课题。AI 与机器人的出现并不是要取代人类,我认为 AI 比较适合扮演辅助人类的重要角色。
大家可以审视看看以上的内容不知道你陷入哪几点呢?这系列主题即将进入尾声~ 爆肝日子即将解脱(汗。各位连假愉快~
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: 【Day26】反馈元件 - Progress bar
灵异现象 - 我是你的恶梦
灵异现象 - 我是你的恶梦 Credit: 贾希大人不气馁! 灵感来源:UCCU Hacker 灵异...
#3 JavaScript Crash Course 2
今天教 Promise Async / Await。 Promise Promise 这个东西跟时间...
Vue.js 从零开始:Slot Props
上篇提到slot传入的内容都是由外层元件提供,如果内层元件slot也想使用内层资料时,就可以使用Sl...
DAY16 服务室--JSON Server RESTful API简单用
RESTful API操作资料的几种方法 我们先使用前天的假资料如下: { "posts&...
Day 20 BeautifulSoup模组二
接续昨天的影片,今天的内容为介绍「更精准地」搜寻HTML元素的方法~ 想在大海捞针就变得简单许多了(...