爬虫怎麽爬 从零开始的爬虫自学 DAY25 python网路爬虫开爬6-资料储存
前言
各位早安,书接上回我们将程序码改得更方便阅读,还加上抓取连结的功能,今天我们要来把这些抓到的资料存起来方便我们去使用
开爬-资料储存
我们经过前天的优化是让资料的内容更方便使用
今天我们要来让它变成可以存放也可以单独使用的档案
而这就要用到昨天介绍过的 python 的档案读写
file = open(档名, 模式, 编码)
file.write()
file.close()
要把资料存起来首先面对的第一个难题是要把开关写入档案放在哪
最後我选择把它放在最外面的 for 回圈内 因为如果放在 getData() 里面
会开关档比较多次 对运算的负担比较大
第二个难题是 getData() 原本是 return 下一页网址也就是一个字串而已
但是现在有整页的标题加上 URL 所以很明显不能再 return 一个字串而已了
所以我最後选择使用 list 来当作 return 的对象 能完美放入大量资料
原本的 URL 我选择放在 list 的第一格 也就是 [0] 的位置
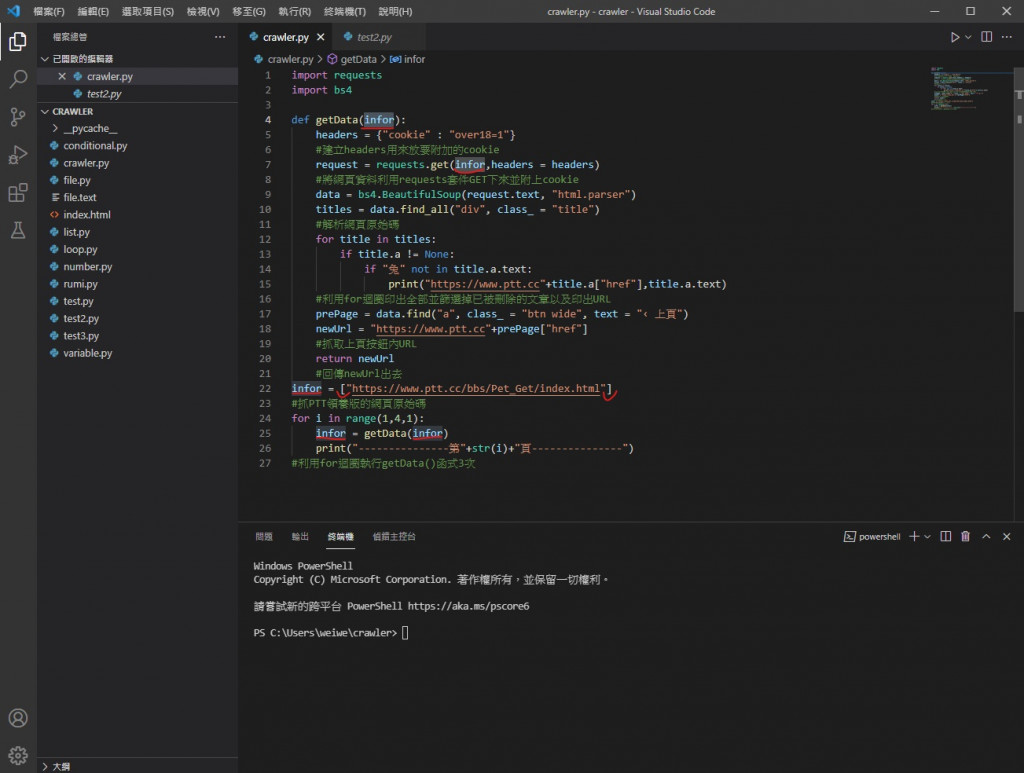
所以首先我把所有 url 变数都改成 infor 并把第一页的网址存成 list
接下来
把 request 里的 infor 加上 [0]
因为我们的 list infor 内第一个位置 infor[0] 就是专门用来放 URL 的
再来是把原本印出所有标题加连结的 for 回圈
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
print("https://www.ptt.cc"+title.a["href"],title.a.text)
改成这样
i = 1
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
infor.insert(i, "https://www.ptt.cc"+title.a["href"]+" "+title.a.text+"\n")
i = i+1
就是把原本印出的功能换成 infor.insert 也就是新增进 infor 内
insert(位置编号, 资料)
i 是设计用来让资料被依序放入从 [1] 开始的位置内 (因为 [0] 用来放翻页用的 URL 了)
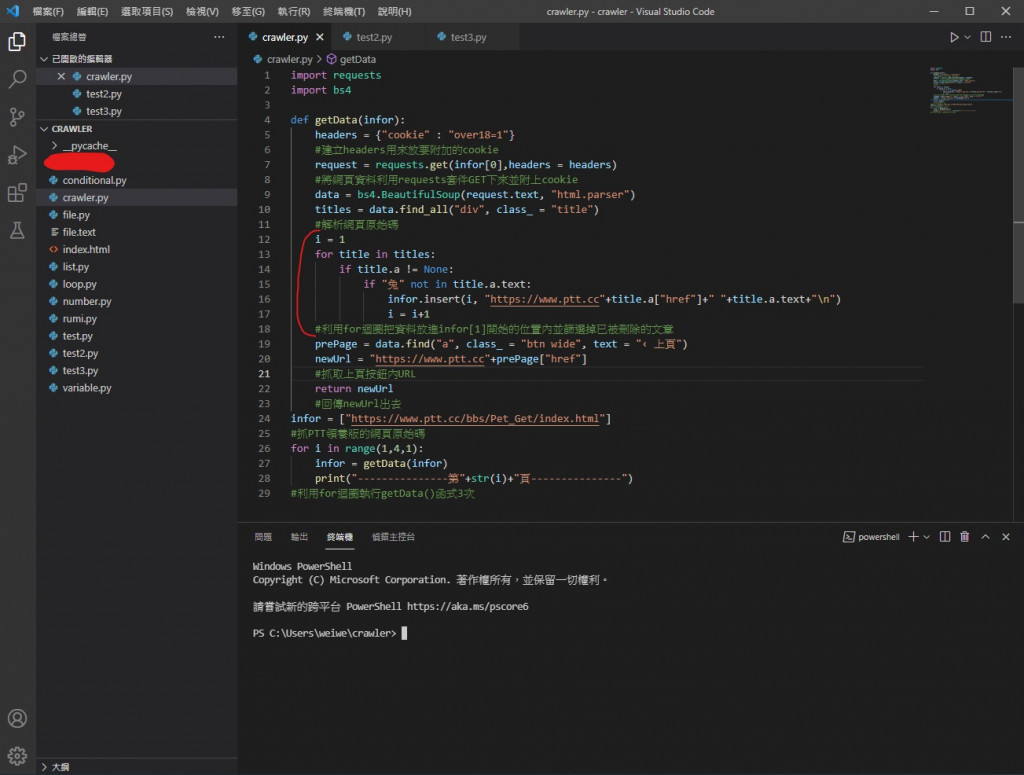
再来就是要处理输出的部分
我们要把 newUrl 放到 infor[0] 里
return newUrl
把它改成
infor[0] = newUrl
return infor
最後就是改外面的 for 回圈并加上 把资料存档的功能
for i in range(1,4,1):
infor = getData(infor)
print("---------------第"+str(i)+"页---------------")
改成
file = open("Pet_Get.txt", "w", encoding="utf-8")
for i in range(1,4,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"页--------------------\n")
for inf in infor:
file.write(inf)
file.close()
print("爬完了")
首先第一行开档 模式是写入 编码 utf-8 特别编码是因为没指定编码系统读不懂
再来第二第三行 for 回圈是让他跑进 getData() 内执行功能
并带出我们要的 infor (装着满满资料)
第四行是用来隔页方便阅读的
第五第六行是用来写入的 for 回圈 它会把 infor 内的资料都写进去
第七行关档
第八行用来显示执行完成
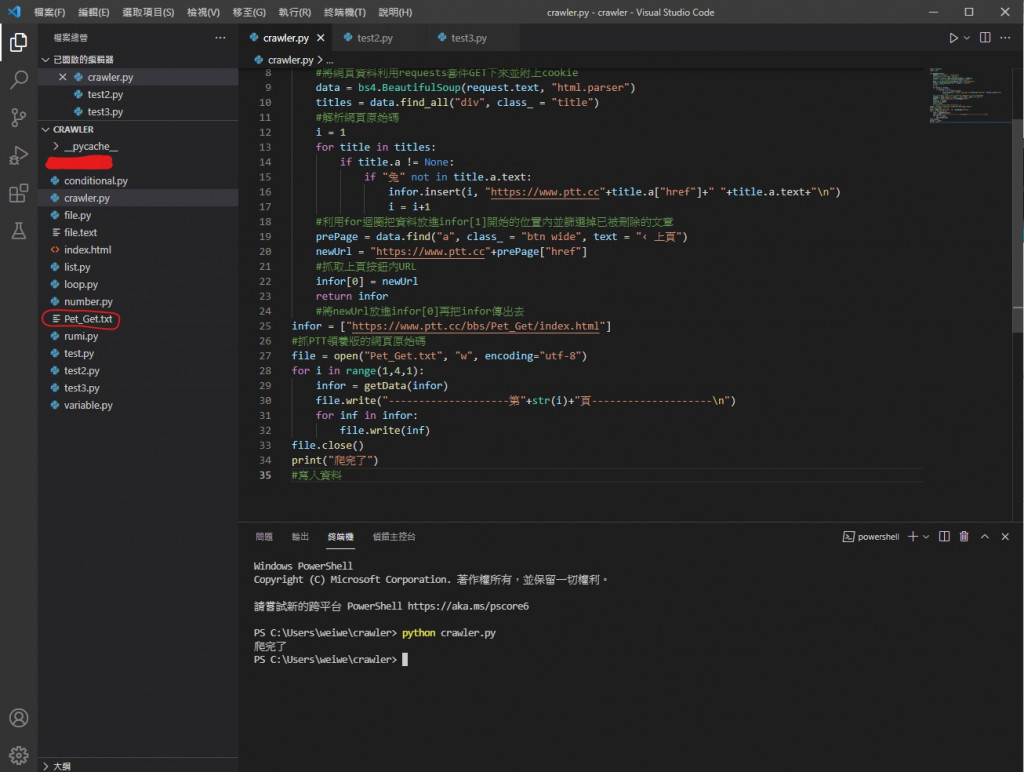
可以看到跑出我们写入的档案了 (系统建立的)
把它打开来看
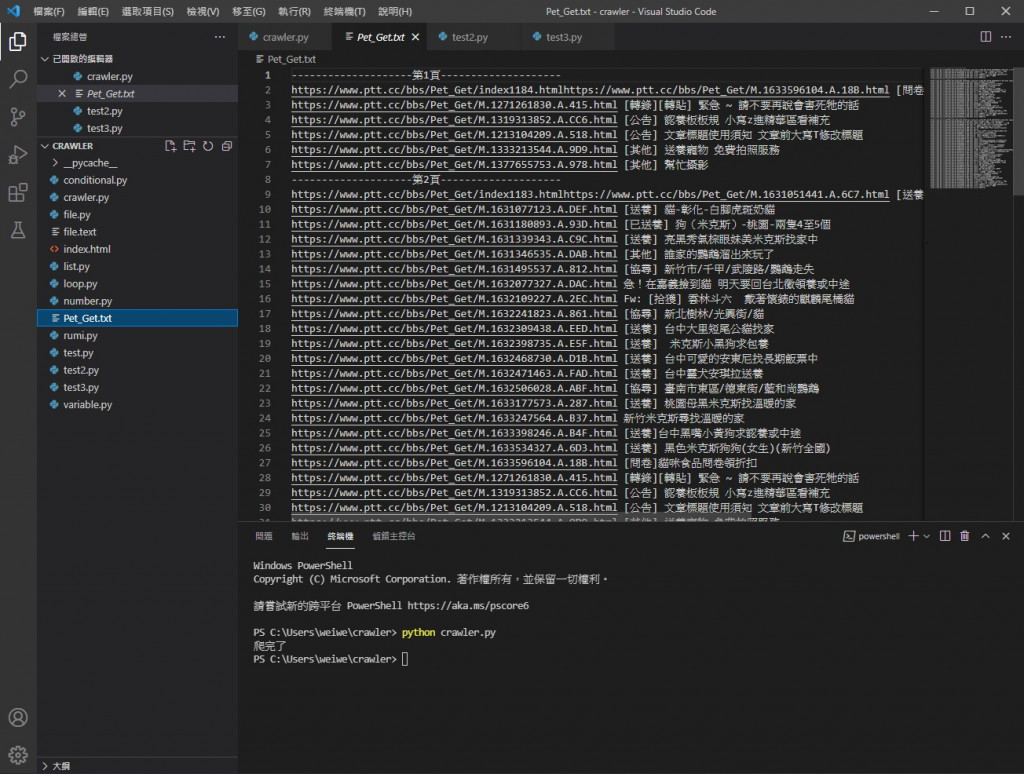
可以看到我们爬取的资料都写进来了
也可以直接从外面看
它被建立在跟我们python档案同一个资料夹里
也就是终端执行的位置 C:\Users\你的名字\crawler
打开来看看
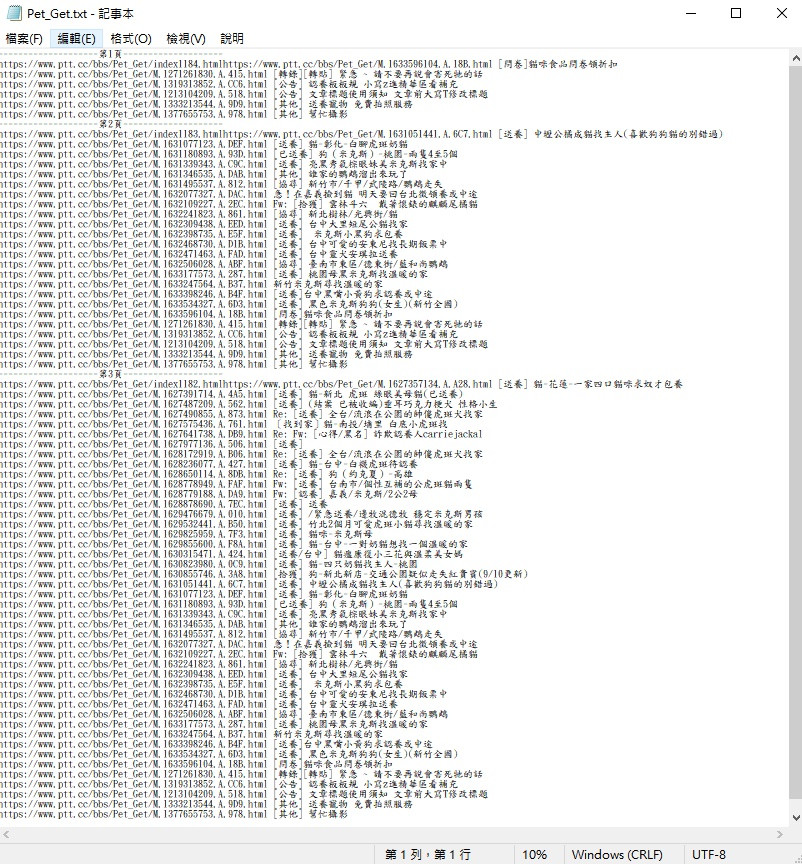
我们爬虫抓到的资料都在这里
太好了大成功~
今天的程序码
import requests
import bs4
def getData(infor):
headers = {"cookie" : "over18=1"}
#建立headers用来放要附加的cookie
request = requests.get(infor[0],headers = headers)
#将网页资料利用requests套件GET下来并附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析网页原始码
i = 1
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
infor.insert(i, "https://www.ptt.cc"+title.a["href"]+" "+title.a.text+"\n")
i = i+1
#利用for回圈把资料放进infor[1]开始的位置内并筛选掉已被删除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上页")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上页按钮内URL
infor[0] = newUrl
return infor
#将newUrl放进infor[0]再把infor传出去
infor = ["https://www.ptt.cc/bbs/Pet_Get/index.html"]
#抓PTT领养版的网页原始码
file = open("Pet_Get.txt", "w", encoding="utf-8")
for i in range(1,4,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"页--------------------\n")
for inf in infor:
file.write(inf)
file.close()
print("爬完了")
#写入资料
今天我们成功把文章标题跟连结抓下来存起来了 明天我们要再优化我们的爬虫
参考资料
https://medium.com/ccclub/ccclub-python-for-beginners-tutorial-bf0648108581
https://selflearningsuccess.com/python-for-loop/
http://kaiching.org/pydoing/py/python-return.html
https://www.runoob.com/python/att-list-insert.html
https://segmentfault.com/q/1010000007854405/a-1020000007854709
https://oxygentw.net/blog/computer/python-file-utf8-encoding/
https://www.itread01.com/content/1549631901.html
https://www.runoob.com/python/file-methods.html
早安闲聊区
你知道吗?
法国人做出了会飞的雨伞喔
每日二选一
如果必须选你会选择超热大晴天还是倾盆大雷雨呢
<<: Day 24 - 实战演练 — FormControl
>>: 今天就改变你的人生!不要寄望将来,立即行动,停止拖延。
EP 29: Archive and Publish TopStore App for Android in Visual Studio
Hello, 各位 iT邦帮忙 的粉丝们大家好~~~ 本篇是 Re: 从零开始用 Xamarin 技...
Day1 Let's ODOO: 前言
前言 因工作需求碰到ODOO这套ERP,藉由铁人赛纪录所学与遇到的问题,若有错误也欢迎不吝指出。 O...
DAY14 - firestore 使用条件来进阶查询
上一篇介绍 firestore CRUD 的各种方式,今天要来介绍进阶的查询资料方式,利用条件去过滤...
[第二十六天]从0开始的UnityAR手机游戏开发-输出64位元的APP
点开Project Settings的other,把Scripting Backend改为IL2CP...
33岁转职者的前端笔记-DAY 21 英寸转公分单位转换器练习笔记
基本语法笔记 四舍五入: Math.round(); 无条件进位: Math.ceil(); 无条件...