[神经机器翻译理论与实作] 从头建立英中文翻译器 (IV)
前言
今天会将昨天训练好的翻译模型在测试资料集进行预测,若进度符合期待,将会使用 BLEU 分数来评估模型的翻译能力,关於此评测机制的详细原理与范例程序码可见下方参考文章[1][2]。
翻译器建立实作
我们可将昨天训练好的 Keras 模型与其权重从硬碟载入程序中,不需要再经过漫长的学习历程(与教育部公告的108课纲无关):
from tensorflow.keras.models import load_model
# load pre-trained model
eng_cn_translator = load_model("models/eng-cn_translator_v1.h5")
翻译单一文句
我们让模型预测每一笔测试资料,并打印出第一个英文句子的输出结果:
# predict model
trans_seqs = eng_cn_translator.predict(
X_test,
batch_size = 60,
verbose = 1,
use_multiprocessing = True
)
print(trans_seqs[0])
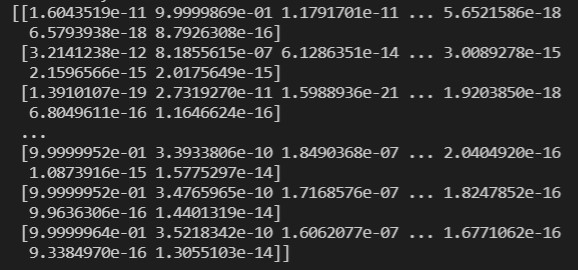
以上显示为 X_test 当中第一个句子的神经网络原始输出,其为每个时间点属於每个经过 one-hot 编码单词的机率。我们可以透过以下函式来预测一个句子:
def pred_seq(model, single_seq_pair, reverse_tgt_vocab_dict):
"""
Predicts a single sentence
---------------------------
single_seq_pair:
sequence pair that is made up of only one source sequence and one target sequence [(src_max_seq_length, ), (tgt_max_seq_length, )]
type: list of NumPy arrays
"""
# print("raw prediction: ", model.predict(single_seq_pair))
# model gives a one-hot encoded array
pred = model.predict(single_seq_pair)[0]
# turns into label encoded array (word_id's)
pred_le = [np.argmax(oneHot_vec) for oneHot_vec in pred]
# print("pred_le: ", pred_le)
pred_tokens = []
for id in pred_le:
try:
word = reverse_tgt_vocab_dict[id]
pred_tokens.append(word)
except KeyError:
break
return ' '.join(pred_tokens)
# predict the 5th sentence in X_test
i = 5
# ground truth sentences
print("actual source sentence: {}".format([reverse_src_vocab_dict[id] for id in X_test[0][i] if id != 0]))
print("actual target sentence: {}".format([reverse_tgt_vocab_dict[id] for id in X_test[1][i] if id != 0]))
首先我们来看真实的英文输入句以及中文对应句:

以及翻译模型预测的结果:

可以看得出「忠」被翻译成了「丈」,其余单词皆精准预测,至於这样的翻译效果好与不好呢?请见下回介绍如何以 BLEU 分数来评估翻译器的好坏。
结语
我们目前利用了模型翻译单一个句子,然而尚未走完模型训练的阶段。以下为翻译实作任务的几项残留课题:
- (训练阶段)评估模型的翻译品质:计算模型在语料库上的整体 BLEU 分数
- (训练阶段)以 alignment matrix 检视输入与输出单词之间的关联性
- 模型推论
今天发出了第三十篇文章,也完成了铁人赛。然而此系列文将会介绍完整个翻译器的实作任务,因此明天还会再相见,各位晚安~~

阅读更多
- A Gentle Introduction to Calculating the BLEU Score for Text in Python
- BLEU: a method for automatic evaluation of machine translation
<<: 成为工具人应有的工具包-23 FileTypesMan
>>: Day23 - 针对 Metasploitable 3 进行渗透测试(4) - 认识 Metasploit
色码转换器再进化
前言 今天来优化 Day24 做的色码挑战器,主要增加的功能如下: 新增转换成RGBA 点选色码可以...
伸缩自如的Flask [day5] session
假设,你今天写了一个页面或是储存了一些简单的状态或资讯,call了另外一个API或是跳转到不同页面并...
[Day28] Tableau 轻松学 - TabPy 备份与还原
前言 在勒索病毒盛行的年代,为资讯系统做好备份是最基本的工作,有效的备份除了可以抵挡病毒的攻击,同时...
EP12 - 重构并模组化 Terraform 程序码
传统的架构上, 我们会使用独立机械建置 Git、Jenkins, 最後部署至目标环境, 到目前为止,...
display : Inline、Block、Inline-Block
display:Inline、Block、Inline-Block 前言 display是用来设置每...