[Day 26] 交叉验证 K-Fold Cross-Validation
今日学习目标
- 了解 K-Fold 各种不同变形
- K-Fold Cross-Validation
- Nested K-Fold Cross Validation
- Repeated K-Fold
- Stratified K-Fold
- Group K-Fold
前言
交叉验证又称为样本外测试,是资料科学中重要的一环。透过资料间的重复采样过程,用於评估机器学习模型并验证模型对独立测试数据集的泛化能力。在今天的文章中我们将详细的来介绍每一种 K-Fold 变型。
K-Fold Cross-Validation
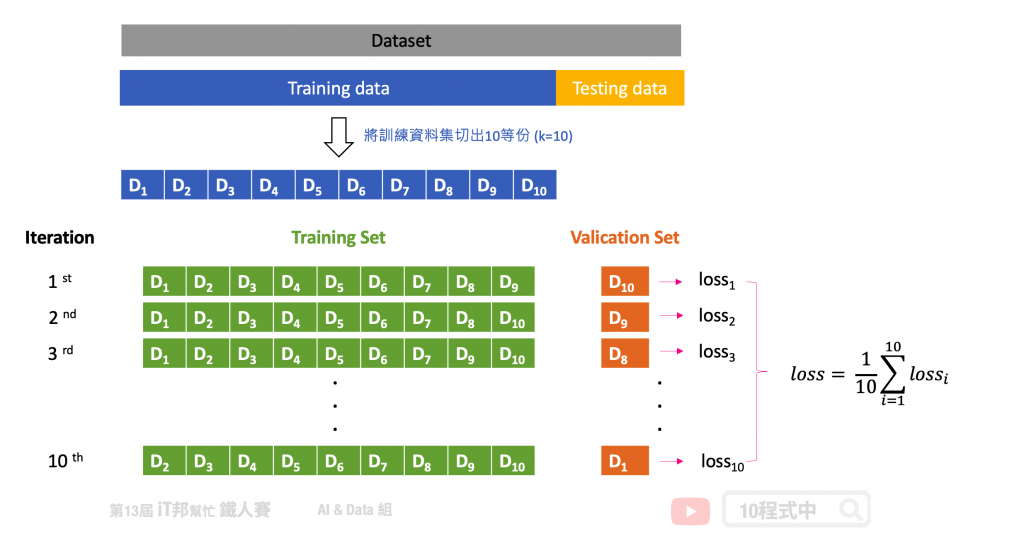
在 K-Fold 的方法中我们会将资料切分为 K 等份,K 是由我们自由调控的,以下图为例:假设我们设定 K=10,也就是将训练集切割为十等份。这意味着相同的模型要训练十次,每一次的训练都会从这十等份挑选其中九等份作为训练资料,剩下一等份未参与训练并作为验证集。因此训练十回将会有十个不同验证集的 Error,这个 Error 通常我们会称作 loss 也就是模型评估方式。模型评估方式有很多种,以回归问题来说就有 MSE、MAE、RMSE...等。最终把这十次的 loss 加总起来取平均就可以当成最终结果。透过这种方式,不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不会那麽敏感。
Nested K-Fold Cross Validation
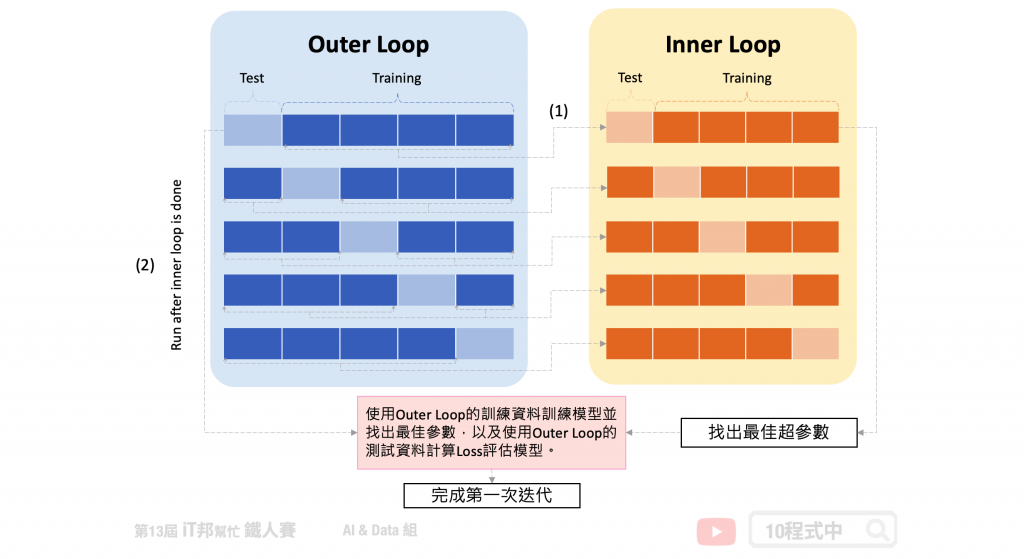
此方法为 K-Fold 的变型,Nested 意指双回圈(巢状)的意思。分别有外层回圈(Outer Loop)为一般正常的 K-Fold。唯一不同的是我们在每一次迭代中会将外层 K-Fold 的训练集拿出来再进入到内层回圈(Inner Loop)再做一次 K-Fold。由下图可以看到,(1)我们可以在第一个外层回圈中将训练资料又切为五份训练集和测试集,内层圈透过 Grid Search 等演算法来寻找最佳超参数。等找到最好的模型超参数後,我们再拿(2)外层回圈的测试资料进行模型评估并计算 loss。最终我们会得到五个测试集 loss 的平均作为交叉验证模型评估结果。

Repeated K-Fold
另一个 K-Fold 变型为 Repeated K-Fold 顾名思义就是重复 n 次 K-Fold cross-validation。假设 K=2、n=2 代表 2-fold cross validation,在每一回合又会将资料将会打乱得到新组合。因此最终会得到 4 组的资料,意味着模型将训练四遍。此种方法会确保每次组合的随机资料并不会重复。简单来说执行 K-Fold 交叉验证,然後重新洗牌数据,然後再次执行 K-Fold。

Stratified K-Fold
分层交叉验证,每个 Fold 都是按照类别的比例抽出来的。假设这个分类任务一共有三个类别A、B、C,它们的比例是1:4:8。那麽每个fold中的A、B、C的比例也必须是1:4:8。其实现方式也非常简单,首先依序把A、B、C类别的数据随机分成k组,最後再把它们合并依照比例起来,就得到了k组满足1:2:10的数据了。
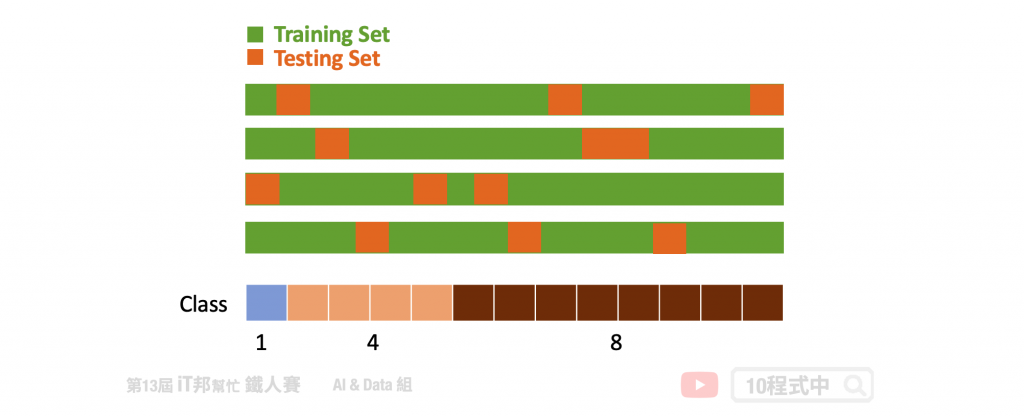
优点:
- 优於一般的 K-Fold 因为test set能充分代表整体数据。
- 预测结果的方差也会变小,使得交叉验证的 error 更可靠。
- 对於资料不平衡的数据很有用
缺点:
- 大多实例都以分类问题为主
Group K-Fold
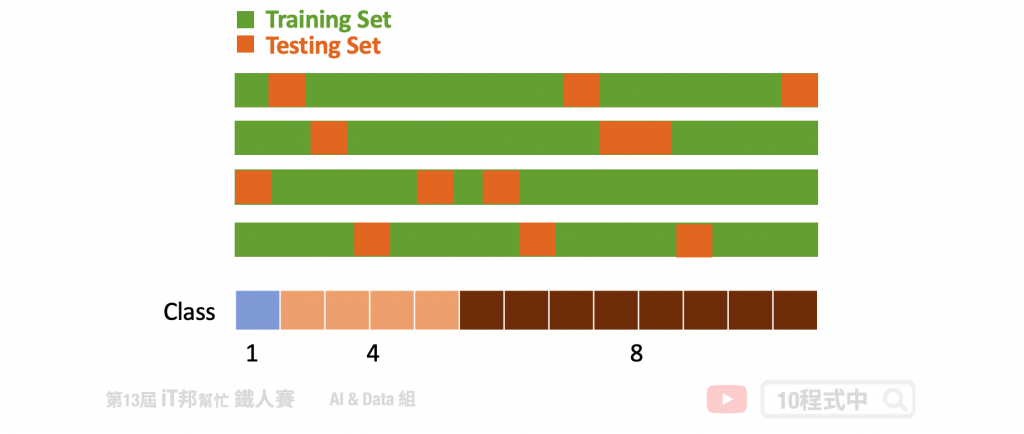
此做法为了避免取连续的资料而造成测试集或验证集偏向某一特别的状况而造成过度拟和训练集,反而在未看过的资料下表现不好。Group K-Fold 为了避免此情况发生,它切割资料时有效的从资料集中每个区块随机挑选作为验证集。同时保证每一个 Fold 的验证集并不会重复的资料。假设你有三个类别,至少验证集必须从三个不同的分组中抽样取出,同时确保每一个 Fold 所抽出来的这三个分组并不会重复。
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: 30天零负担轻松学会制作APP介面及设计【DAY 29】
>>: Day 25 大数据下的三兄弟-从Kinesis到EMR与Redshift
[Day 3]专案始动(後端篇)
到底该为一路顺畅没出Bug高兴还是遇到难题花时间克服狂喜,都几 第三天终於该来建立专案了,我是使用I...
Day 17 ( 中级 ) 灯光绕圈圈 ( 数字函式 )
灯光绕圈圈 ( 数字函式 ) 教学原文参考:灯光绕圈圈 ( 数字函式 ) 这篇文章会介绍如何使用「函...
Day-7 Excel的贴上小技巧
今日练习档 ԅ( ¯་། ¯ԅ) 复制贴上,相信这两个动作是大家都会的,但其实它还有更深入的应用喔,...
[Day14] Flutter with GetX animated_text_kit
animated_text_kit 文字特殊效果的第三方,可以参考文档的样式作选择 使用起来类似是F...
Day 21 Spies 间谍来袭!
该文章同步发布於:我的部落格 今天我们要介绍 Mock 军团的最後一员,也就是 Spies 这个用...