[DAY23] Experiment, Run, MLflow
DAY23 Experiment, Run, MLflow
今天开始的几天内,会进入 Azure Machine Learning(下称 AML) SDK 比较难的地方,但也是最核心且最强大的地方罗!
Experiment(实验)and Run
一个科学家,会做很多很大量的实验,来证明某些东西。而资料科学家也是,需要做很多实验,才找到 insight。在 AML 里面提供了 Experiment 这个类别,可以让你可以更好管理你的每次的实验。你可以使用不同的资料、不同的程序码来执行同一个实验,然後发布到 AML 纪录每一次执行的结果,让你更好的管理资料科学的研究。
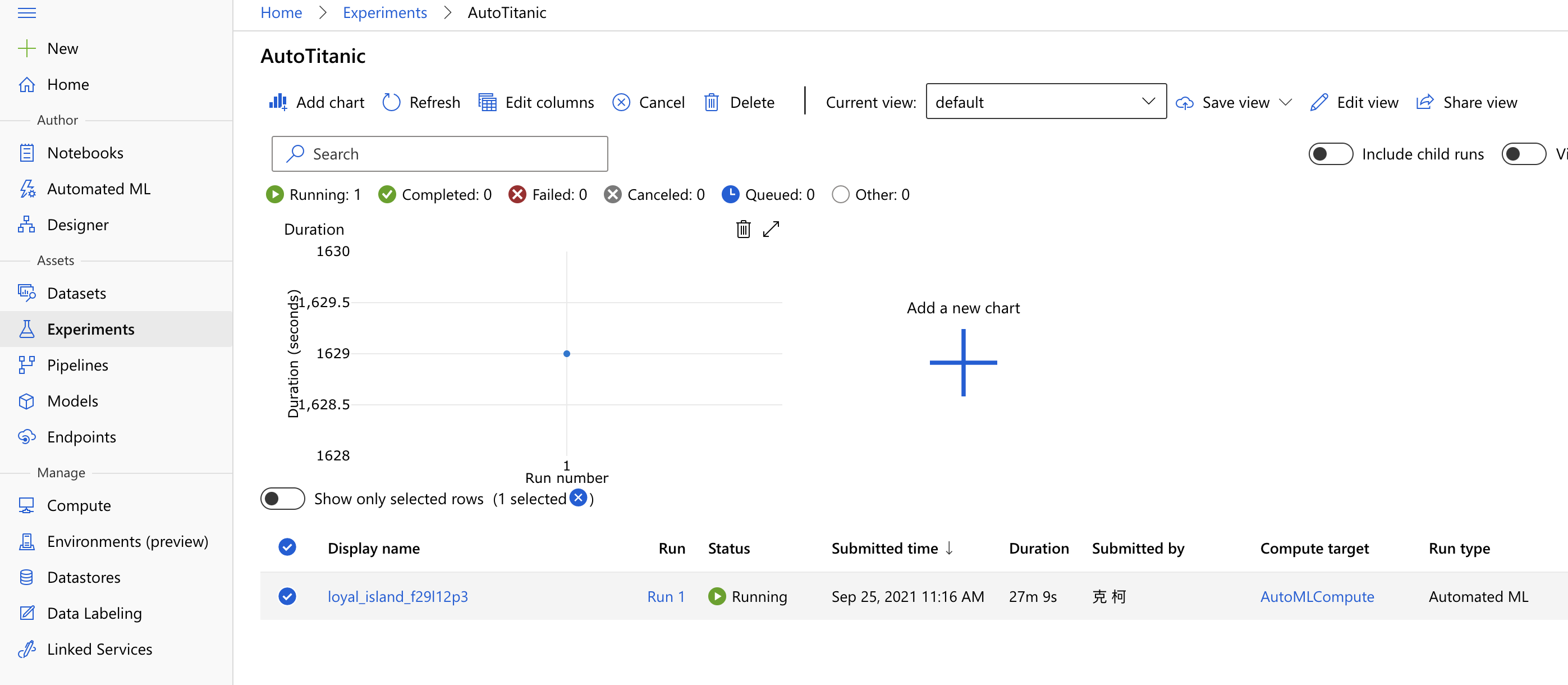
而 Run,就是每一次实验「跑」的过程,你可以透过 Run 物件来纪录你跑的过程。一个实验里面可以有很多次的 Run,还记得下面这张图吗?这是我们在 AutoML 的章节里最後的结果。这张图里面的 Experiment 叫做 AutoTitanic,然後有一个 Run。如果你再调整後再跑一次,又会再多出个 Run 出来。这就是 Experiment 和 Run 的关系。
在 SDK 里操作 Experiment and Run
- 简单的 Experiment and Run 程序码参考如下:
from azureml.core import Experiment
# 建立一个 Experiment
experiment = Experiment(workspace = ws, name = "experiment_sdk")
# 开始一个实验并纪录
run = experiment.start_logging()
data = pd.read_csv('data.csv')
row_count = (len(data))
# 用 log 纪录下来
run.log('资料大小', row_count)
# 实验完成
run.complete()
-
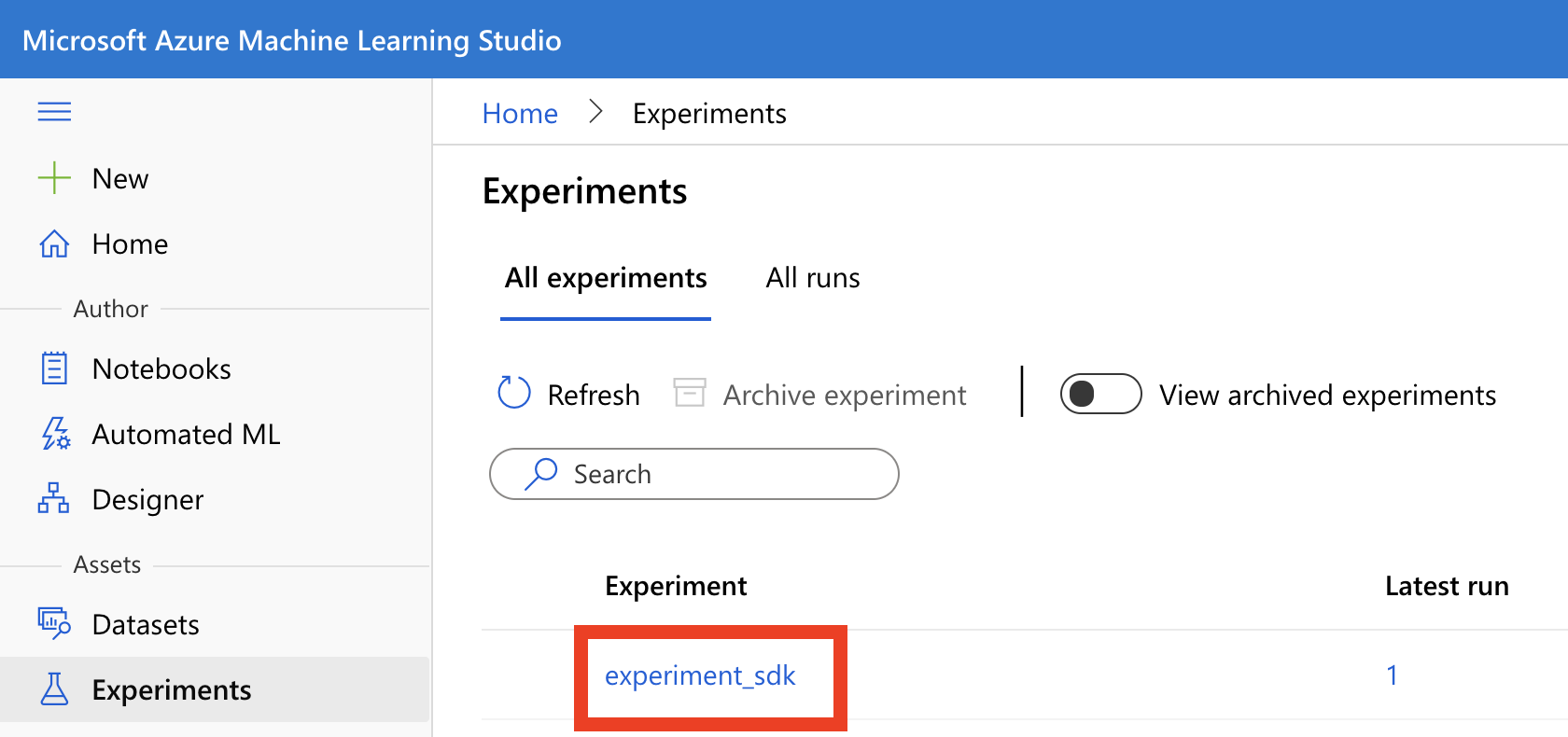
接着我们进到 AML 的介面,点左边选单的 Experiment,就会看到我们刚刚建起来的实验:experiment_sdk 了。
-
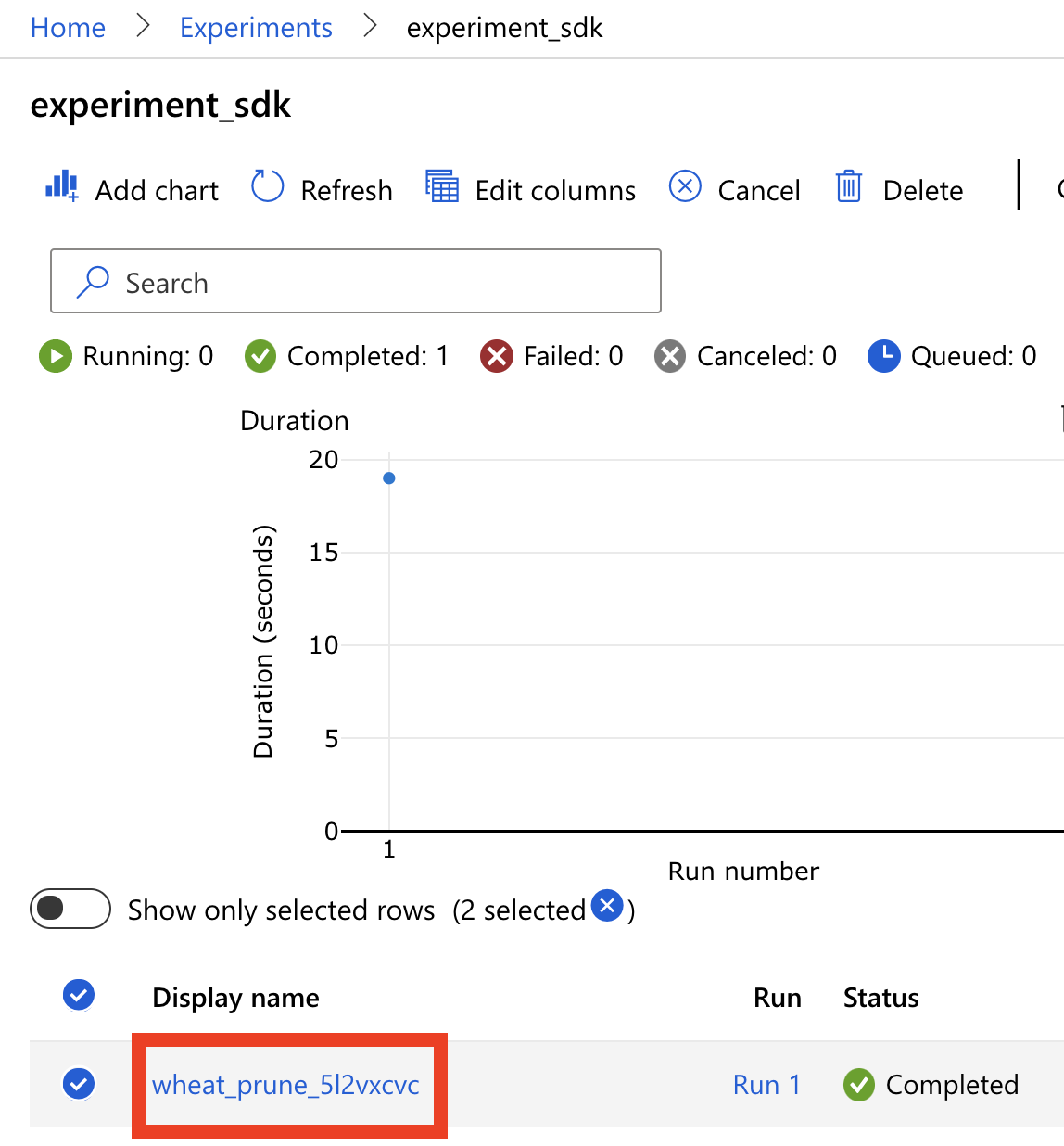
接着我们点进去刚刚建起来的实验:experiment_sdk,会看到下图的画面,有一个 Run 1,Run 的名称是随机产生的,可以手动更改。我们点进去这个 Run 1 来看看。
-
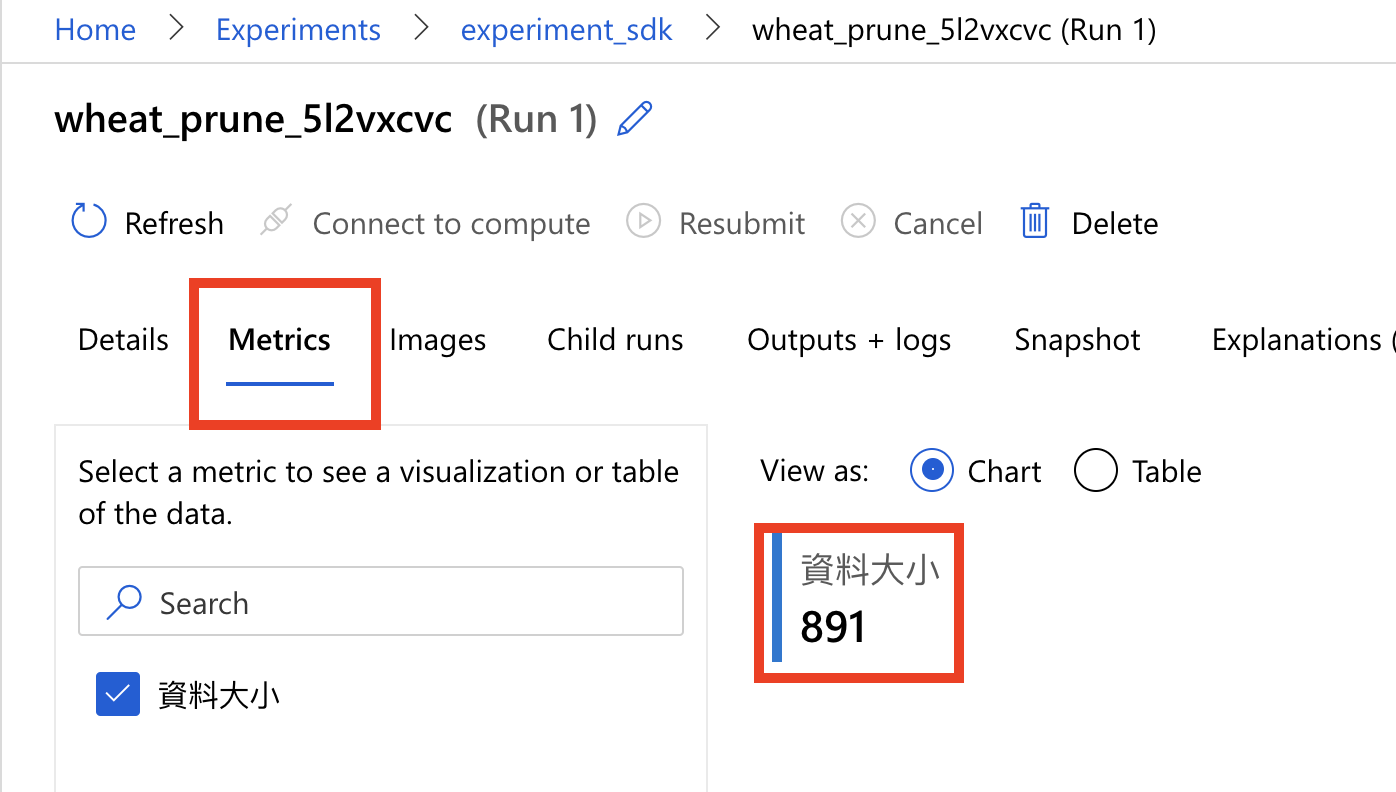
我们进去後,切到 Metrics 的页签,可以看到刚刚我们在 log 里写的「资料大小」,被写进去了。这个就是 log 的作用。(其实刚刚在首页,应该也是看得到这个资料大小的数据哦!)
-
run.log() 的形式有很多种,分别说明如下:
- log:纪录单一值,像我们范例里只纪录了资料的大小。
- log_list:纪录 List。
- log_row:纪录多个资料行的资料列。
- log_table:以资料表形式纪录字典。
- log_image:纪录影像档或绘图,例如 matplotlib 画出的图。
MLflow
-
如果是资料科学界的老司机的话,看到这里记录 log 的功能,应该会立刻联想到一款知名的工具
MLflow。没错,MLflow 在 AML 的世界里也是可以使用的哦!必须要安装两个套件:pip install mlflow还有pip install azureml-mlflow。 -
MLflow 的用法和原生的几乎是一样的,参考程序码如下:
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
# 设定 MLflow URI 给 AML
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
mlflow.log_text('mlflow', 'my_log')
mlflow.end_run()
- 进到 AML 介面後,一样可以看到这个 Experiment 被建立起来了!(也可以去 outputs 的页签看输出的内容哦!)
今天的内容有没有开始觉得困难了呢?不过深入理解的话,会发现这些 SDK 的内容都是很强大的工具。明天我们来讲 ScriptRunConfig,还有 Experiment and Run 的另一种使用方式哦!
ps 天啊今天的内容快要3000字了。
C++时间日期,需收费另外再跟我说明
交出来的程序最少都要有headerfile(.h)档和mainfile(.cpp)档这两个档案才行,...
04. Unit Test x Cart Class
我想大部分的人学测试不是想用在写 leetcode 吧,因此我们来模拟一下购物车。 我们来写一个有点...
跌破有色眼镜,就是打破惯性框架
「再一双拥抱真理的手臂,让第三只眼睛可以破开谜语。」 在尝试将刚刚学会的概念再做一次练习,发现到想像...
【CSS】【Bootstrap】关於order
【前言】 本系列为个人前端学习之路的学习笔记,在过往的学习过程中累积了很多笔记,如今想藉着IT邦帮忙...
3. STM32-GPIO初探
Open Drain (漏极开路)与 push-pull(推挽) 介绍 Open Drain 输出为...