分布式可观测性 Tracing、Time Series Data、LSM浅谈
上篇回顾
分布式可观测性 Logging 浅谈
分布式可观测性 Structured Log
分布式可观测性 Metrics 浅谈
继续浅谈Observability的最後一个基石
Trace
单体架构下, 基本上调用关系仅在同一个process的记忆体内做调用, 通常都是透过stack trace做调用链路的trace.
将这些资讯给汇出後, 再通过类似Flame Graph的工具, 进行可观测性的分析. 也可透过图, 来得知调用关系.
但是在Distributed System下常常, 服务之间相互调用, 其调用的机器与网路甚至不是同一个.
一样也是要透过调用链路收集的工具, 把Distributed System的调用链路整成一个跟stack trace很像的结构与资讯. 其中也包含每个调用链路的耗时时长.
这就是Distributed Tracing, 能参考去年我的文章Distributed Tracing & OpenTelemetry介绍
Time Series Data
前面两个维度讲的资料, 都是以Time Series Data的方式呈现.
Time Series Data反应的是Metric指标在某一个时间点上的状态.
这种资料与MySQL这类的OLTP资料有所不同.
- 资料不可变
- 只有一直生成新数据, 不会去修改旧数据, 时间过了, 改变过去没意义
- 按照时间依序生成一系列的数据
- 必备的栏位有Timestamp, 还会加上少说一个主要栏位(服务名称,设备名称...)当作索引
- 通常数据量比OLTP的数据庞大非常多
- 这些指标数据, 通常会以1s的间隔做聚合, 换句话说 就是看同一秒内机器的整体效能, 或是服务的效能
- 通常只对近期数据做关注, 一阵子以前的通常非常非常少被存取
- Metric指标或Label标签要能被Aggregation聚合, 计算平均值、Maximum、Minimum之类的
Time Series Data会有一些独特的概念
- Metric 指标
- 被监控的对象, 温度、速率、反应时间...
- 一个Metric可以有多个Tag
- 有几种Type, 可参考Prometheus给的
- Label/Tag 标签
- 对指标特徵维度的说明
- Key Value形式呈现
- path=/Order -> 表示这metric是针对api/order的可能counter可能是respone time的取样, 要看metric是什麽
- 所以若是Log没以Structured Log格式呈现, 不方便取Key来当这Label的Key
所以 Metric+Label决定了一个计量的单位.
如果以MySQL来存放, 那一个Metric就会是一张表了, Label则是里面的栏位, 可能还会有其他栏位像是Timestamp.
再来MySQL这类的资料库, 通常以B+Tree做资料存储结构, 通常会以读取的顺序依序做排序,
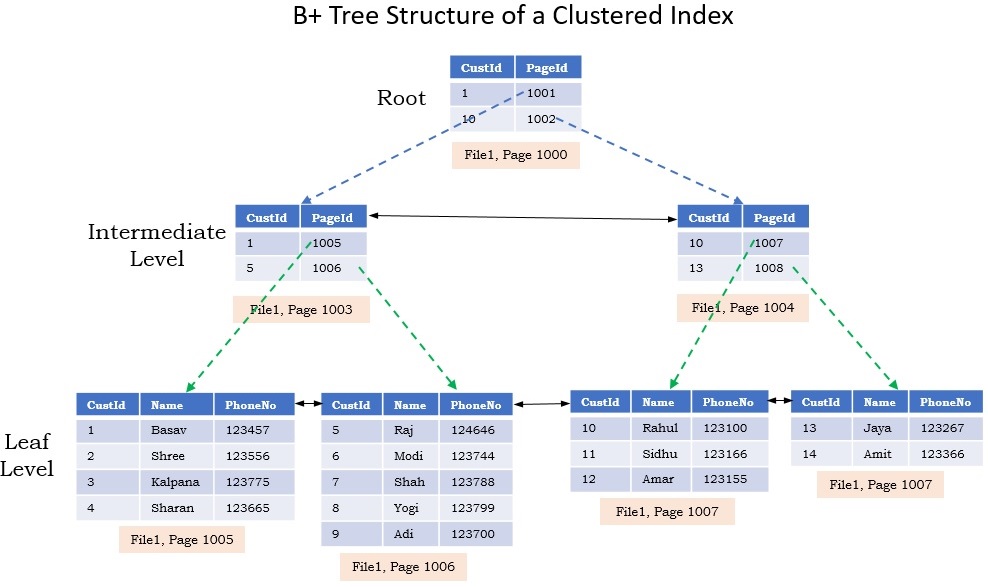
因为B+Tree预设是为了对磁碟做存取操作的, 它所有资料都存在Leaf叶子节点中.
每次查询时, 需要从Root节点查询到Leaf节点, 在从Leaf节点对应的位子进行读取, 其存放的顺序刚好跟读取所需要的顺序是一致的. 然後Leaf节点的资料是放在磁碟内的Page, 读取一整个page出来後放到Memory中.
但没人说物理Page刚好位子都是相邻的.
这样的结构好处是插入删除的时间复杂度是O(log2N), 查询要看情况, 可以非常好也能很不好.
这种随机读写的场景蛮常见的, 会导致时间大多花在磁盘寻址上.
大家应该组机很常去跑CrystalDisskMark这工具, 来看磁碟的随机读写与顺序读写的速度快慢.
可以发现顺序读写的效率跟俗机读写的效率不是一个量级的
哪怕你是SSD
但Time Series Data的另一个特徵是海量的资料量, 这些资料量在写入是挑战,
如果几十万笔, Log2N才多少, 但若是1亿笔就可怕了
所以有下面结构的资料库
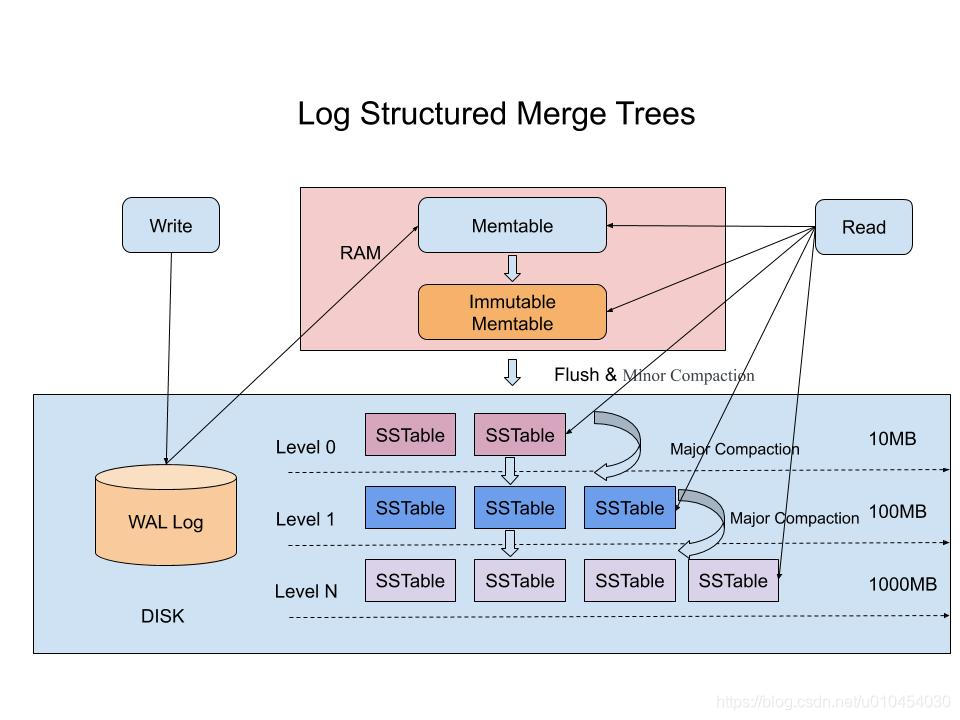
LSM-Tree
所以有令一种资料库很适合存放Time Series Data, 它叫LSM-Tree (Log Structured Merge Tree)
核心思想是 将离散的随机写入请求都转成批量的顺序写入请求
透过在记忆体整理後, 只要确保在记忆体时, 资料是按照顺序排列的,
当记忆体的资料累积到一个量时, 会做一些归并整理, 在直接写到硬碟中.
这样子就不用一直的写入了, 毕竟写到记忆体是非常高效率的.
为了避免资料在资料库当机後遗失, 也是会采取WAL(Write Ahead Log)的机制.
虽然它没解决掉查找还是随机位置的问题,
但记得 监控在意的是过去短时间内的聚合资料而已. 近期的资料会在记忆体中, 查询依然非常高效率.
这类的介绍, 明年看有否机会深入.
>>: 30天学习笔记-day 23- Dagger (上篇)
初学者跪着学JavaScript Day17: 物件:new Set()
一日客语:中文:不好意思 客语:paiˇse! ㄆㄞˇ 厶ㄟ 1.set 是一个集合 2.集合没有索...
DAY 20:Adapter Pattern,统一不同产品的介面
Creational 建立相关的 patterns 已经告一段落,接下来要进入 Structural...
Android Studio初学笔记-Day17-ItemTouchHelper
ItemTouchHelper 接续昨天的RecyclerView,今天来让RecyclerView...
Day 04. Zabbix 可监控的服务、设备、应用
我把它分成使用基本款 (可安装 Agent)、通用款 (支援监控类通讯协定)、简易款 (无法安装 A...
【Day 3】Git x GitHub x 版本控制的基础:吴宝春的成功秘诀
tags: 铁人赛 Git GitHub 版本控制 概述 碎念时间 为什麽我们需要 版本控制 ? 每...