Python & PyMongo 学习笔记_GridFS API
一、简易说明
Mongo DB 对於单个 Document 的大小限制为 16MB,
若想储存大於这个大小的资料 or 档案的话,则必须利用
官方提供的 GridFS API,来进行储存,GridFS 会将
档案拆分,并存为 Binary 型态,下面为简易的操作,
如果有错误,欢迎留言讨论!
本次测试资料来源为 政府公开资料
二、引入套件
from gridfs import GridFS
from pymongo import MongoClient
from setting import get_mongo_setting
import json
import contextlib
三、利用 contextlib 建立一个可迭代的连线物件
@contextlib.contextmanager
def get_gridfs():
database_name = "gridfs_test"
client = MongoClient(**get_mongo_setting())
mongo_girdfs = GridFS(client[database_name])
yield mongo_girdfs
四、读入测试资料
with open("./demo_data.json", "r", encoding="utf8") as file:
data = json.load(file)
五、新增资料
将资料写入进资料库,GridFS 在写入资料的时候,会回传一组 file_id
建立一个 file_id_list 储存 file_id 进行备用
file_id_list = []
with get_gridfs() as mongo_gridfs:
for row in data:
# 利用 put 进行写入
file_id = mongo_gridfs.put(json.dumps(row).encode("utf8"))
# 将 file_id 存入 list 备用
file_id_list.append(file_id)
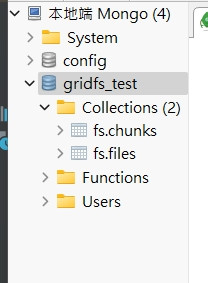
可以看到当写入成功,MongoDB 会自动帮你在指定的 database 下
自动生成两个 collection,分别为 fs.chunks 及 fs.files
六、查询资料
利用 get(file_id) 进行查询,另外 GridFS 也提供 find 等功能,但相对的在写入的时候就必须加入额外的参数才会比较有作用,本篇介绍就不另外讨论了。
由於 GridFS 会自动帮我们分割档案,因此拉回来的资料会被储存在一个 list 当中,我们必须先将 list 当中的内容组合回原本的资料内容,才可以进行读取
with get_gridfs() as mongo_gridfs:
for file_id in file_id_list:
data = list(mongo_gridfs.get(file_id))
tmp_data = ""
for _itme in data:
tmp_data += str(_item, "utf8)
print(json.loads(tmp_data))
七、修改资料
很遗憾的,目前在 GridFS 要进行资料的修改,只能透过
先将原本的 file 删除,再插入的方式,但是插入的时候可以指定 file_id
gridfs.put(data, {"_id": ObjectID(file_id)})
八、删除资料
这部分就没有和原本的 mongo 操作差太多直接使用 delete 删除即可
gridfs.delete(file_id)
九、参考文件
Python -今天我想来点爬虫程序
爬虫原理: 抓取资料->分析结构->取出要的结构文字->输出想要的格式 程序码: ...
Day 15 | 魔术方块AR游戏开发Part4 - 面的旋转(下)+游戏机制
在上一篇我们完成面的旋转,却发现旋转途中若点击放开,面会停留在旋转途中,今天我们就要来解决这个问题。...
Day -9 while与for
while 常见用法如下: //while count = 1 while count<=5:...
[2021铁人赛 Day03] 解题前的准备工作
引言 今天会介绍解题前的准备工作,以及你需要有什麽样的环境。 解题大致流程 基本上可以归纳出一个解...
Day 05 - 想要够给力的机器-EC2
来到了中秋连假的第一天,买不到云上的月亮,我们就到云上买台机器来玩玩吧 1. 使用EC2好处? EC...