day20 在ui蒐集flow,能取代liveData吗?
好的,前一篇讲到了flow可以完全取代liveData,其实错!!
直接从结论开始讲,flow并不支援data binding,也有其限制,用stateflow才能完全取代liveData
flow适用於当数据的开始/停止需要和观察者匹配
如何正确的从ui蒐集flow
A cold flow backed by a channel or using operators with buffers such as buffer, conflate, flowOn, or shareIn is not safe to collect with some of the existing APIs such as CoroutineScope.launch, Flow< T>.launchIn, or LifecycleCoroutineScope.launchWhenX, unless you manually cancel the Job that started the coroutine when the activity goes to the background.
通过cahnnel产生的flow,或是使用buffer的flow,像是buffer()、conflate()、flowOn、shareIn(),在coroutine.launch、flow.launchIn、lifecycleCoroutineScope.launchwhen...并不能安全地蒐集,除非你在ui进入背景时手动取消job,因为上述的api会持续收集资料,即使ui已经进入背景
/**
* 错误示范
* */
// Collects from the flow when the View is at least STARTED and
// SUSPENDS the collection when the lifecycle is STOPPED.
// Collecting the flow cancels when the View is DESTROYED.
lifecycleScope.launchWhenStarted {
locationProvider.locationFlow().collect {
// New location! Update the map
}
}
这种写法,当ui进入背景,新资料不会被处理,但是某些情况下producer还是会持续进行(blog的范例用channel 的offer),此外,lifecycleScope.launch和launchIn会更危险,即使ui进入背景,仍会不断处理资料,最终可能导致应用崩溃
//正确写法
var manuallyCanaelJob:Job?= null
...
manuallyCanaelJob = lifecycleScope.launch{
locationProvider.locationFlow().collect {
}
}
...
override fun onDestory(){
manuallyCanaelJob?.cancel()
}
尽管这种写法正确,但比较麻烦,其实也就一个原因,flow不知道lifecycle
flow不知道lifecycle怎麽办?
聪明的读者们,应该从前一篇就有个疑问了吧?flow有collect了为甚麽还要asLiveData呢?是不是他不知道lifecycle呀
没错,他就是不知道lifecycle,大家回想一下,应该还记得当年学android为甚麽要用liveData吧,那flow不知道lifecycle不就要我们自己处理,好麻烦好麻烦,还是用asLiveData好了
且慢,其实~已经写好罗
首先,确定gradle版本 androidx.lifecycle:lifecycle-*:2.4.0-alpha03
要在alpha01後的才有repeatOnLifecycle
implementation "androidx.lifecycle:lifecycle-viewmodel-ktx:2.4.0-beta01"
lifecycleScope.launch {
lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED){
//只有在lifecycle到start及start之後
}
}
注意:
The minCompileSdk (31) specified in a
dependency's AAR metadata (META-INF/com/android/build/gradle/aar-metadata.properties)
is greater than this module's compileSdkVersion (android-30).
Dependency: androidx.lifecycle:lifecycle-viewmodel-ktx:2.4.0-beta01.
对android compile版本也有要求,最低31
gradle>android compileSdk 最低要31
repeatOnLifecycle
他是一个suspend方法,会接受一个生命周期的状态作为参数,当生命周期到该状态时,会建立一个coroutine,并执行区块中的代码; 而当生命周期低於该状态时,会自动取消coroutine
如此一来,repeatOnLifecycle就能为我们管理collect的取消,正如大多数函式,建议在activity的onCreat或fragment的onviewCreate中使用
fragment
Important: Fragments should always use the viewLifecycleOwner to trigger UI updates. However, that’s not the case for DialogFragments which might not have a View sometimes. For DialogFragments, you can use the lifecycleOwner.
因为这个repeatOnLifecycle现在还蛮新的,这三种写法都可以编译过,目前是没发现什麽差异,但有被讲到,还是提一下
lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED)
//or
repeatOnLifecycle(Lifecycle.State.STARTED)
//or
viewLifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED)
官方好图
解释了差异
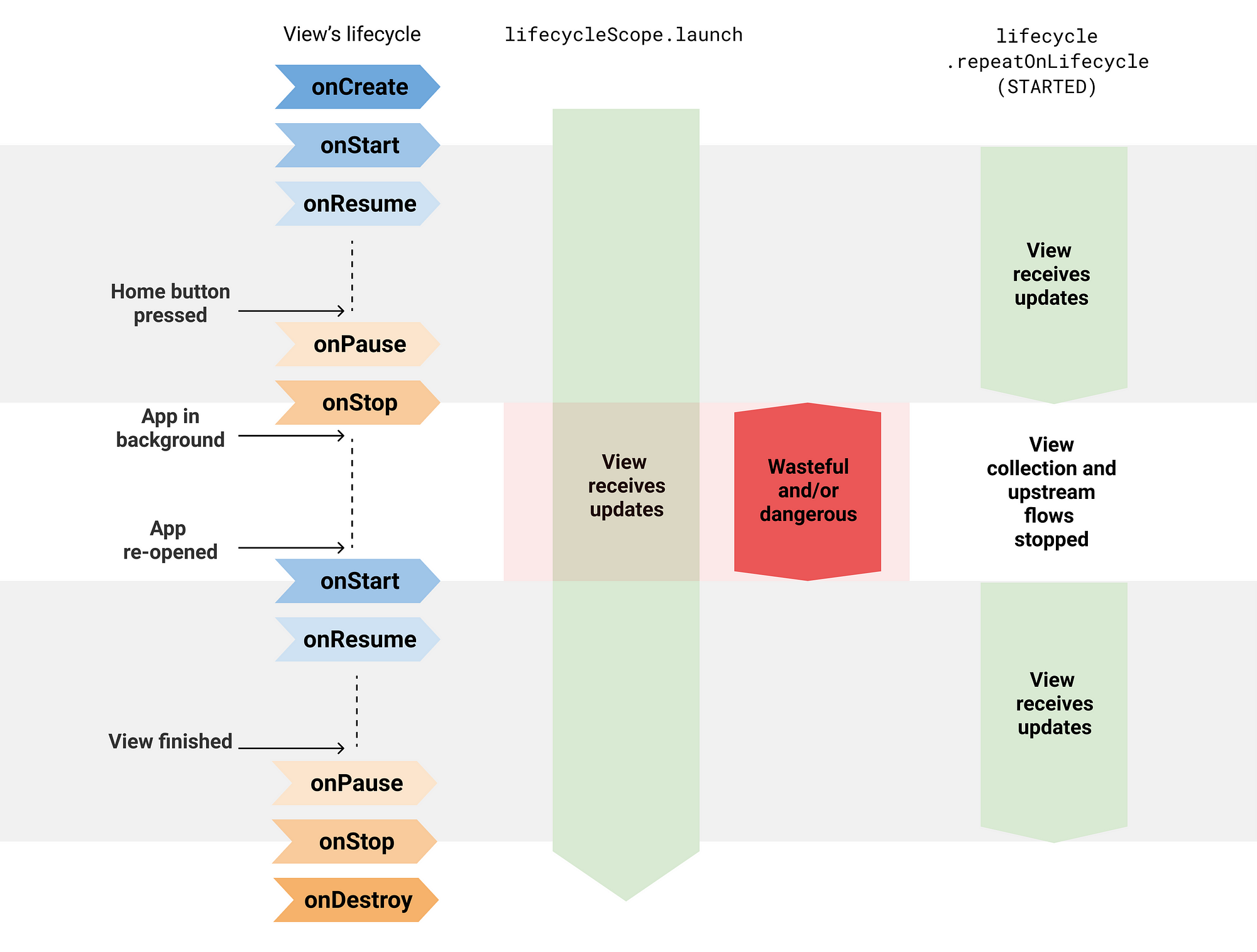
给个例子

那写一个小型范例
//retrofit
@GET("posts/{num}")
suspend fun getPostFlow(
@Path ("num") num: Int
): Post
// repo
val postFlow: Flow<Post> = flow {
var count = 1
while (true){
val result = service.getPostFlow(count)
emit(result)
count++
delay(2000L)
}
}
// viewModel
val changeId = repo.postFlow
//fragment
lifecycleScope.launch {
lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED){
viewModel.changeId.collect{
binding.apiResultText.text = it.toString()
}
viewModel.otherFlow.collect{
//do something
}
}
}
应该和liveData的内容一样很好理解,那repeatOnLifecycle其实就是告诉开发者,每次ui走到哪个生命周期後,这个block会被调用
google爸爸说封装一下好了
於是...
lifecycleScope.launch {
viewModel.changeId
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect{
}
}
对的,非常简单,但google爸爸说,这个用法有两点要注意
- Operators applied before the flowWithLifecycle operator will be cancelled when the lifecycle is below minActiveState.
- only for one flow collect
- repeatOnLifecycle must be used with the viewLifecycleOwner in Fragments
https://miro.medium.com/max/2000/1*fmQRBPMPpnO7NAO2bg0GKw.
为什麽用flow不用channel
记得我们之前讲过channel吧,透过send()和receive()可以在不同corouitne之前传递值,而flow透过emit()和collect()发送流,两个看起来~ 阿不就差不多
错了错了,从设计原因来看channel是为了同步设计的,而flow是为了数据流而设计的,也因为设计的实现不同,他们会有各自适合的工作,留个地方放之後写比较的连结
而flow在设计上考量到许多数据流的痛点,也为此设计了很多操作符,更重要的是,flow是透过终端操作符来启动数据留
close flow
flow分三个部分,producer、intermediary、consumer,consumer会启动流,而当producer的代码执行完毕、出现Exception、或是consumer停止,便会关闭数据流
因此flow比起channel更难在producer端出现异常(blog写说不会或是非常难),而channel如果没有正常关闭,会在prioducer端浪费资源
我们之前讲过flow是一个冷数据流,他必须有人呼叫consumer的方法才会执行,而每次呼叫,都会创造出一个新的数据流
一个永远不会被suspend的流,永远不会被取消
choose between flow and broadcastChannel
何时用broadcastChannel
当producer和consumer在不同lifecycle或是完全独立存在时
broadcastChannel是基於Channel的实现,他能让producer基於不同的lifecycle,并且广播给任何监听他的对象,而他的producer就不会每次都重新启动
注意,如果用broadcastChannel.asFlow(),转换为数据流,这时关闭flow并不会取消订阅/观察broadcastChannel,此时资源仍处在活耀状态,直到vroadcastChannel取消或关闭。而关闭後只能在创造新的实例
更新,在shareFlow的文件哩,讲明了会取代他,所以我就不讲了
能取代liveData吗?
看到这里应该会发现,已经没有liveData了,没错,只要flow也能和lifecycle合作,就能够一定程度上取代liveData,注意,只有一定程度
限制
- kotlin限定
- flow不支援data binding(之後的文章会讲道)
- 无法透过value取最新值(Flow is stateless (no .value access).)
- 每个collect都会创建新的实例,这代表在model层的操作会是重复的
这其实不是flow的缺点,而是特性,在某些状态下他会非常实用
优点
- 有更多的操作符
- 方便的切换thread
那不用databinding的开发者,选哪个livedata还是flow呢?
看code reviewer有没有要求,现在repeatOnLifecycle()还在alpha阶段,之後可能还会有变动,但可以一边用asLiveData,一边了解新写法
p.s.今天时间比较赶,应该有遗漏细节,之後会回来捕,或是你们直接留言告诉我哈哈哈
连结
必看
lessons-learnt-using-coroutines-flow
a-safer-way-to-collect-flows-from-android-uis
repeatonlifecycle-api-design-story
coroutines-best-practices
Substituting Android’s LiveData: StateFlow or SharedFlow?
<<: LeetCode 双刀流: 90. Subsets II
>>: JavaScript学习日记 : Day23 - 解构赋值
[Day 08] 使用 fastAPI 部署 YOLOv4 (2/2) — 自行撰写 Client 进行互动
前言 昨天我们使用了 fastAPI 内建 client 的 UI 来与 API 互动,今天我们改为...
【左京淳的JAVA学习笔记】第一章 JAVA基础
阿姆斯壮的一小步-准备好装备 在网路上搜寻、下载并安装好最新的JDK(JAVA编辑器套装) 设定系统...
事件查看练习(一)--可忽略的错误
前前後後说了这多,从登录档到资料夹意义,系统权限到事件纪录日志,今天要来实际测试怎麽解决问题,就以笔...
Day12 订单是什麽? 能吃吗
在前些日子里面讲的金流单其实也是订单的一种, 属於商家跟金融服务提供方的订单, 接下来我们要谈的是对...
DAY10 资料室--Vuex模组化
为什麽需要Vuex模组化? 试想一个电商网站,页面繁多,资料的部分前台会有购物车、商品、评价、促销活...