[Day 23] 资料分布与离群值处理
资料分布与离群值处理
今日学习目标
- 资料特徵观察与离群值分析
- 检视资料的分布状态
- 偏度 (Skewness)
- 峰度 (Kurtosis)
- 修正特徵偏度的方法
前言
资料前处理 (Data Preprocessing),是机器学习中最重要的一部分。今日的内容可分为两部份,前半部份算是一些对资料的观察与分析,後半部主要是针对特徵 x 进行统计方法的资料分布观察以及如何修正资料单峰偏左和偏右的常见方法。
载入资料
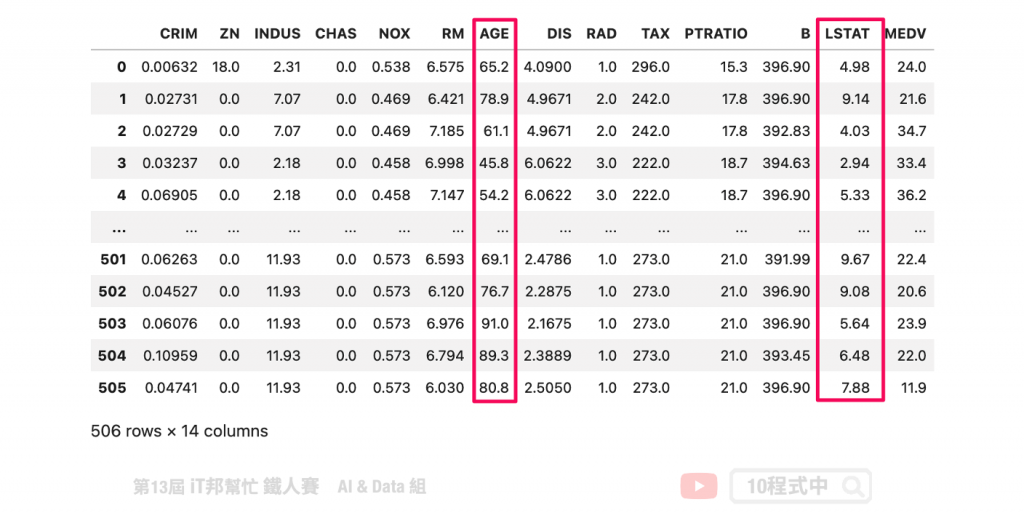
在今日的范例中我们采用波士顿房价预测的资料集。此资料集共有 506 笔资料。其中我们挑选两个特徵来进行示范,分别有 LSTAT: 区域中被认为是低收入阶层的比例、AGE: 1940年之前建成的自用房屋比例。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
# 载入资料集
boston_dataset = load_boston()
# 将资料转换成pd.DataFrame格式。目标输出是MEDIV,剩下的就是特徵即为输入特徵。
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)
boston['MEDV'] = boston_dataset.target
boston
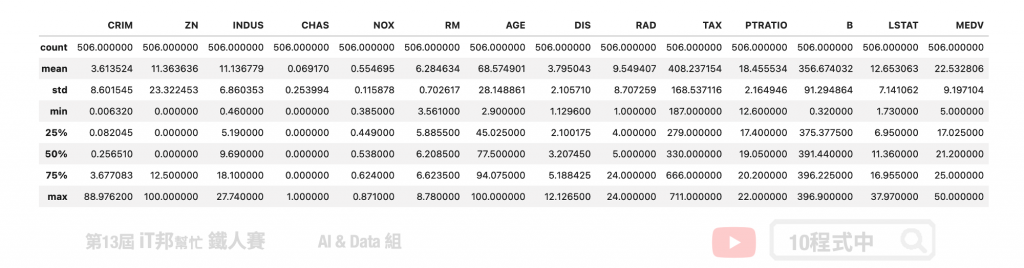
我们可以透过 Pandas 的 describe() 方法先来查看每个特徵的平均数、标准差、四分位数以及最大值与最小值。
# 查看资料分布状况
boston.describe()
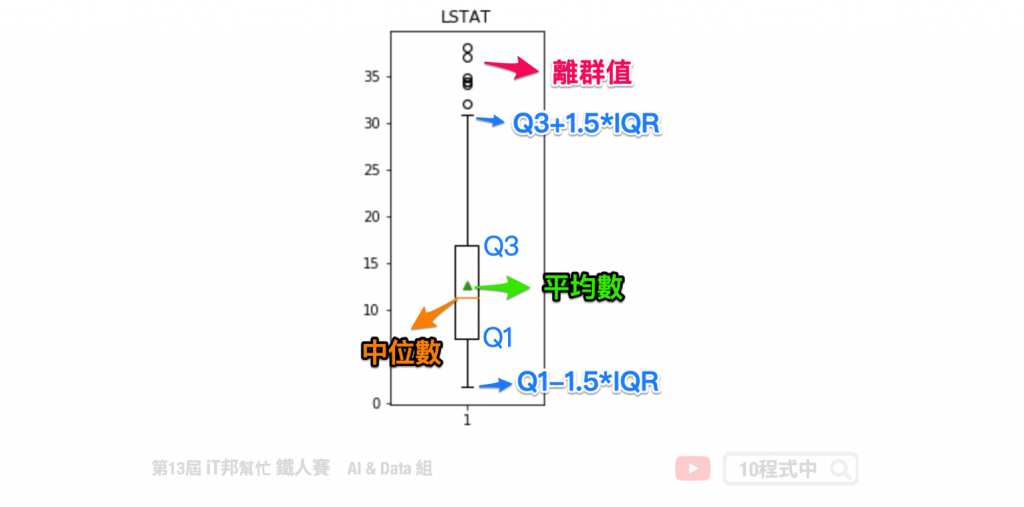
离群值分析
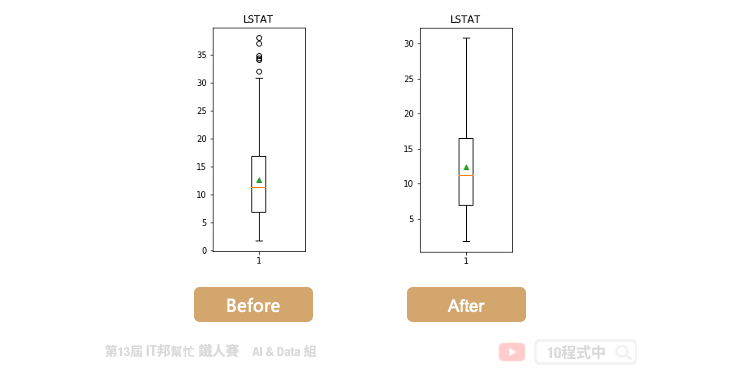
以 LSTAT 特徵举例。我们可以透过 boxplot 来查看该特徵在 506 笔资料中的分布状况,我们可以看出平均值约 12,最大值接近 38,最小值接近 2。我们可以发现大於 32 以外有多个零散的数据点,这些资料我们可以来分析是否为异常点。因为这些异常点所造成的离群值可能会造成特徵的分布状况严重的偏移。
plt.figure(figsize=(2,5))
plt.boxplot(boston['LSTAT'],showmeans=True)
plt.title('LSTAT')
plt.show()
偏度 & 峰度
偏度 (Skewness)
偏度 (Skewness) 是用来衡量资料分布的型态,同时也说明资料分配不对称的程度。其判别方式如下:
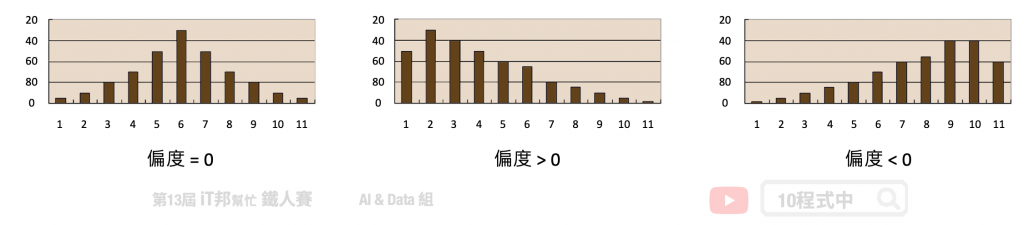
- 右偏(正偏),表示有少数几笔资料很大,故平均数>中位数,所以偏度>0。
- 偏度=0 表示资料分布对称,呈钟形常态分布。
- 左偏(负偏),表示有少数几笔资料很小,故平均数<中位数,所以偏度<0。
峰度 (Kurtosis)
峰度 (Kurtossis) 可以反映资料的分布形状。例如该资料是否比较高耸或是扁平的形状。其判别方式如下:
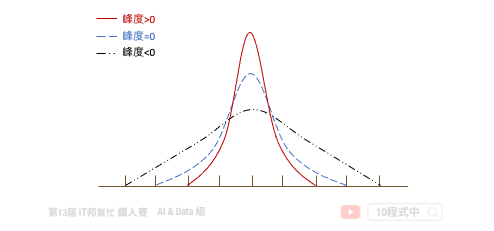
- 峰度>0 表示资料呈现高峡峰。
- 峰度=0 表示资料呈现常态峰。
- 峰度<0 表示资料呈现低润峰。
分布状态
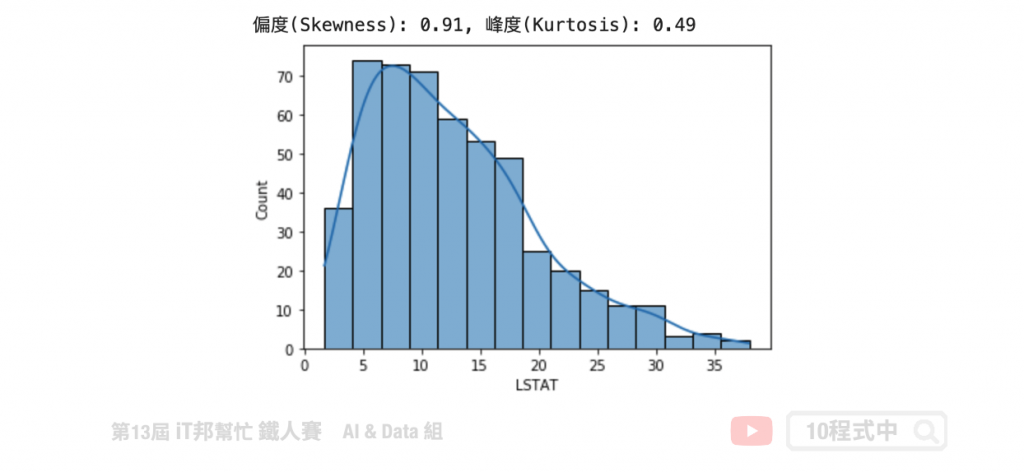
LSTAT 特徵观察
我们可以发现 LSTAT 特徵呈现右偏。透过 Pandas 计算该特徵的偏度与峰度。由结果可以得知偏度 0.91>0 呈右偏,而峰度 0.49>0 呈现高峡峰形状。
# 使用的资料是 LSTAT: 区域中被认为是低收入阶层的比例
# skewness 与 kurtosis
skewness = round(boston['LSTAT'].skew(), 2)
kurtosis = round(boston['LSTAT'].kurt(), 2)
print(f"偏度(Skewness): {skewness}, 峰度(Kurtosis): {kurtosis}")
# 绘制分布图
sns.histplot(boston['LSTAT'], kde=True)
plt.show()
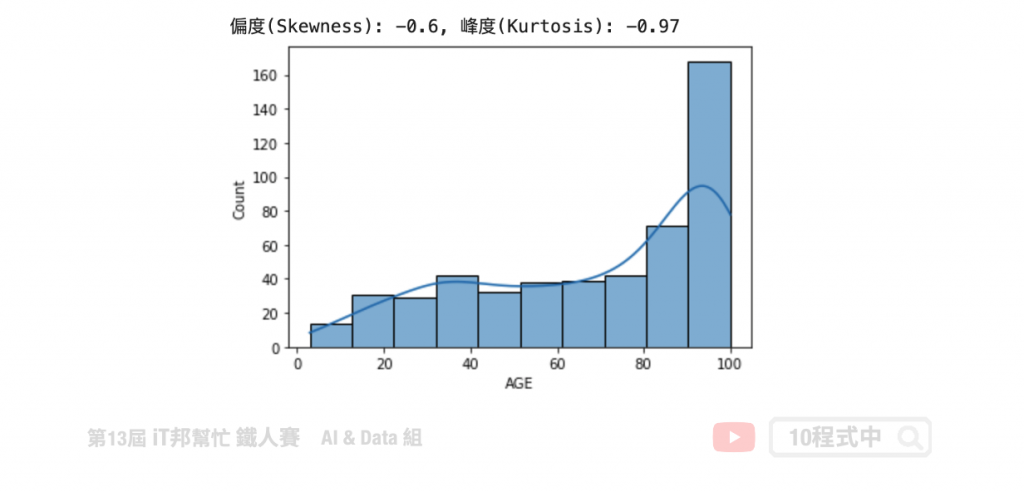
AGE 特徵观察
我们可以发现 AGE 特徵呈现左偏。透过 Pandas 计算该特徵的偏度与峰度。由结果可以得知偏度 -0.6<0 呈左偏,而峰度 -0.97<0 呈现低润峰形状。
# 使用的资料是 AGE: 1940年之前建成的自用房屋比例
#skewness 与 kurtosis
skewness = round(boston['AGE'].skew(), 2)
kurtosis = round(boston['AGE'].kurt(), 2)
print(f"偏度(Skewness): {skewness}, 峰度(Kurtosis): {kurtosis}")
# 绘制分布图
sns.histplot(boston['AGE'], kde=True)
plt.show()
修正资料偏态的方法
在数学统计或是机器学习中我们都会提出假设,前提是资料样本是具有常态分布。我们可以透过刚刚所讲的偏度与峰度来评估特徵的分布状态,或是透过直方图与核密度估计视觉化查看资料分布。当资料呈现单峰偏斜时,我们会透过一些资料转换技巧,让所有资料能够修正回常态分布。以下整几几个常见的修正特徵偏度的方法:
- 对数转换 (资料不能有0或负数)
- 平方根转换 (资料不能是负数)
- 立方根转换
- 次方转换 (只能处理左偏)
- Box-Cox 转换
- 移除离群值
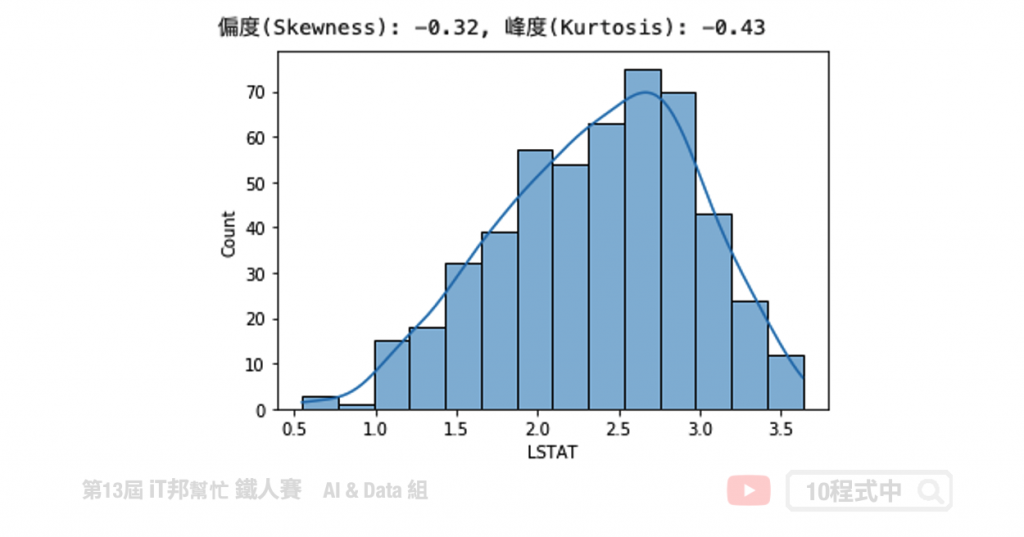
对数转换
因为资料型态左偏,因此我们可以透过取对数来将资料拉回使为更集中。
transform_data = np.log(boston['LSTAT'])
# skewness 与 kurtosis
skewness = round(transform_data.skew(), 2)
kurtosis = round(transform_data.kurt(), 2)
print(f"偏度(Skewness): {skewness}, 峰度(Kurtosis): {kurtosis}")
# 绘制分布图
sns.histplot(transform_data, kde=True)
plt.show()
平方根转换
transform_data = boston['LSTAT']**(1/2)
# skewness 与 kurtosis
skewness = round(transform_data.skew(), 2)
kurtosis = round(transform_data.kurt(), 2)
print(f"偏度(Skewness): {skewness}, 峰度(Kurtosis): {kurtosis}")
# 绘制分布图
sns.histplot(transform_data, kde=True)
plt.show()
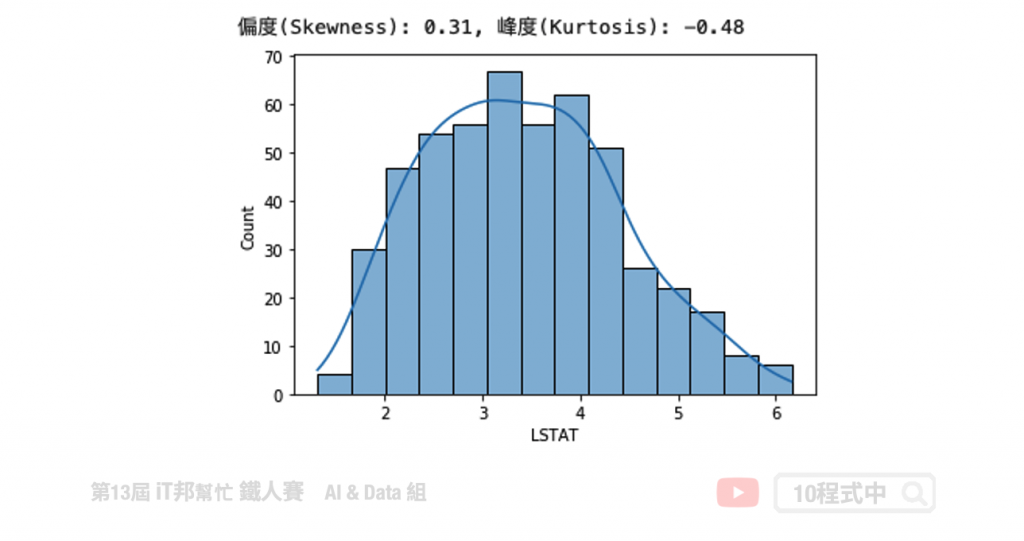
立方根转换
transform_data = boston['LSTAT']**(1/3)
# skewness 与 kurtosis
skewness = round(transform_data.skew(), 2)
kurtosis = round(transform_data.kurt(), 2)
print(f"偏度(Skewness): {skewness}, 峰度(Kurtosis): {kurtosis}")
# 绘制分布图
sns.histplot(transform_data, kde=True)
plt.show()
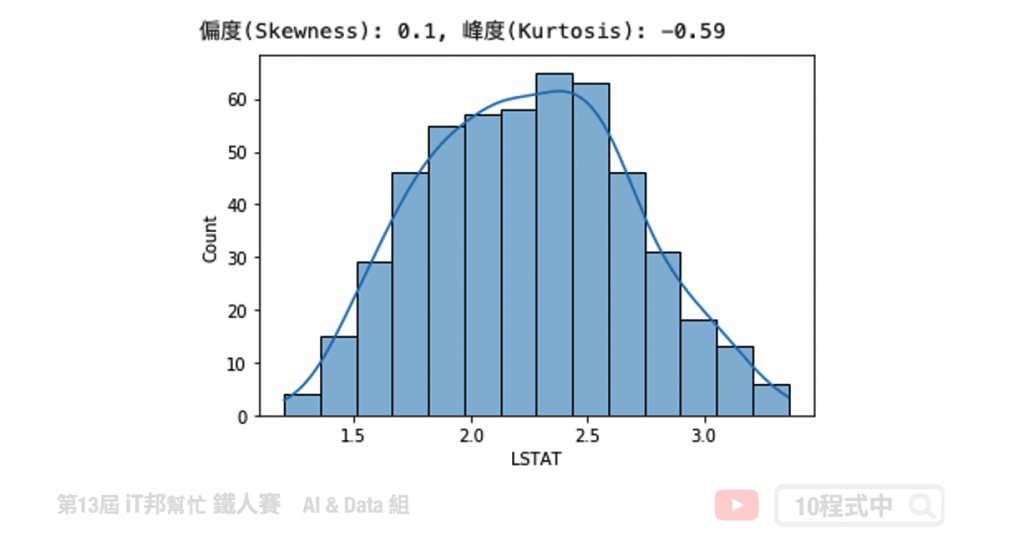
次方转换
次方转换仅能使用在偏左的资料上。
transform_data = np.power(boston['AGE'], 2)
# skewness 与 kurtosis
skewness = round(transform_data.skew(), 2)
kurtosis = round(transform_data.kurt(), 2)
print(f"偏度(Skewness): {skewness}, 峰度(Kurtosis): {kurtosis}")
# 绘制分布图
sns.histplot(transform_data, kde=True)
plt.show()
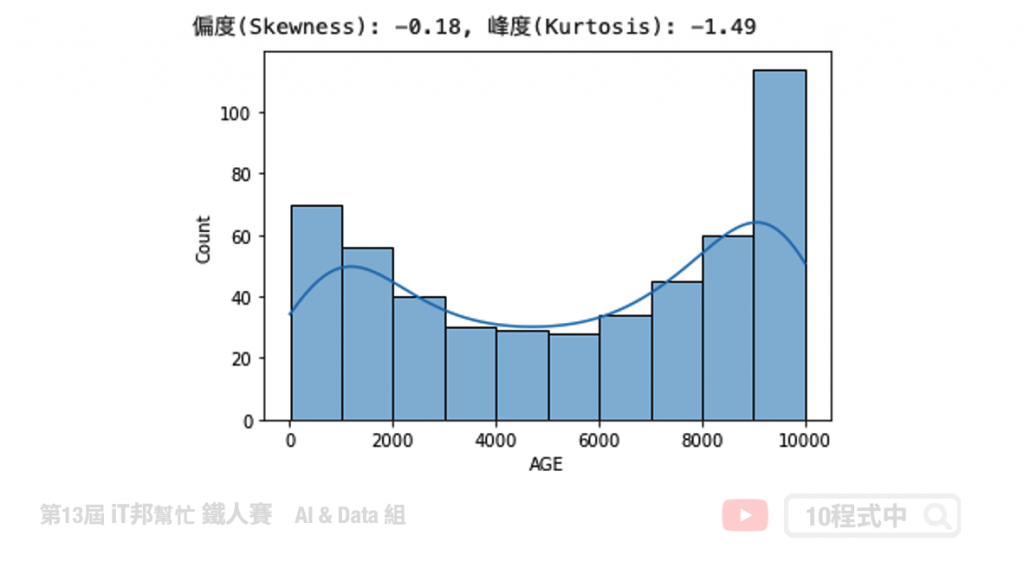
原本的资料分布低润峰且有点双峰的趋势,因此转换出来会有两座山的感觉。
Box-Cox 转换
from scipy.stats import boxcox
transform_data, lam = boxcox(boston['LSTAT'])
transform_data = pd.DataFrame(transform_data, columns=['LSTAT'])['LSTAT']
# skewness 与 kurtosis
skewness = round(transform_data.skew(), 2)
kurtosis = round(transform_data.kurt(), 2)
print(f"偏度(Skewness): {skewness}, 峰度(Kurtosis): {kurtosis}")
# 绘制分布图
sns.histplot(transform_data, kde=True)
plt.show()
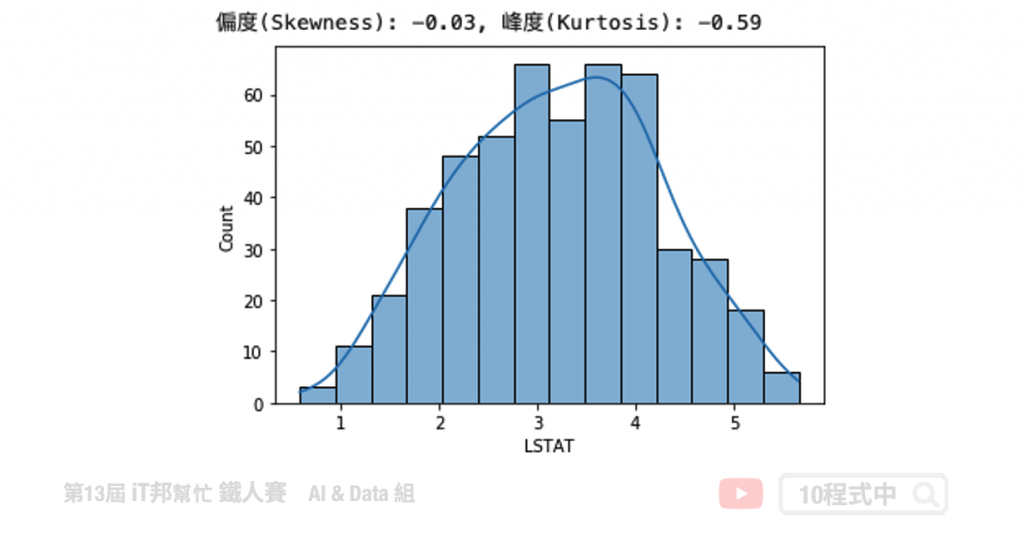
移除离群值
在 Q3+1.5IQR(四分位距)和 Q1-1.5IQR 处画两条与中位线一样的线段,这两条线段为异常值截断点,称其为内限。在 Q3+3IQR 和Q1-3IQR 处画两条线段称其为外限。处於内限以外位置的点表示的数据都是异常值,其中在内限与外限之间的异常值为温和的异常值(mild outliers),在外限以外的为极端的异常值 (extreme outliers)。
# 将所有特徵超出1.5倍IQR的概念将这些Outlier先去掉,避免对Model造成影响。
print ("Shape Of The Before Ouliers: ",boston['LSTAT'].shape)
n=1.5
#IQR = Q3-Q1
IQR = np.percentile(boston['LSTAT'],75) - np.percentile(boston['LSTAT'],25)
# outlier = Q3 + n*IQR
transform_data=boston[boston['LSTAT'] < np.percentile(boston['LSTAT'],75)+n*IQR]
# outlier = Q1 - n*IQR
transform_data=transform_data[transform_data['LSTAT'] > np.percentile(transform_data['LSTAT'],25)-n*IQR]['LSTAT']
print ("Shape Of The After Ouliers: ",transform_data.shape)
我们必须将超出 1.5 倍的极端异常值清掉。共有 7 笔资料被移除掉。
输出结果:
Shape Of The Before Ouliers: (506,)
Shape Of The After Ouliers: (499,)
本系列教学内容及范例程序都可以从我的 GitHub 取得!
欢迎与简单的command
Print HI@Someone 接下来,我们开始写一些可以用的指令吧~~ 好比说,打招呼之类的,而...
LeetCode解题 Day21
485. Max Consecutive Ones https://leetcode.com/pro...
[Day17] 网格交易概念
大概在去年底的时候有接触到一家叫做pionex的加密货币交易所,他里面的网格交易机器人还满有意思的,...
企划实现(1)
常常有人说做好一个企划需要勇气,但绝非这麽简单,创业不只需要勇气还需要运气、人脉、实力 、执着 做好...
Day 0x5 UVa10062 Tell me the frequencies!
Virtual Judge ZeroJudge 题意 对每一列输入,输出各字元的 ASCII &a...