分布式可观测性 Logging 浅谈
小弟我在去年有分享了
Distributed Tracing 分布式链路追踪简介
主要讲到Distributed Tracing出现的缘由,
跟Distributed System Observability(可观测性)的三大基石

- Logging
- Metrics
- Tracing
当时就列出定义而已
这次就多聊点
当业务系统简单可能就单纯对MVC+DB时, 或者是初期流量或数据吞吐量都很少时, 大概都是以单体式架构的形式,
快速开发完成後上线.
在单体式架构上, 查找Log我们通常是直接Login server, 用head、tail、less等命令查看, 也能搭配其几天介绍的grep、awk、sed 来对Log这类的文字进行处理跟分析.
但是在Distributed System, 面对布署在数十数百台机器上,
往往为了快速查找问题, 还是需要一个Log收集、处理、存放、查询的系统.
从Logging角度来谈
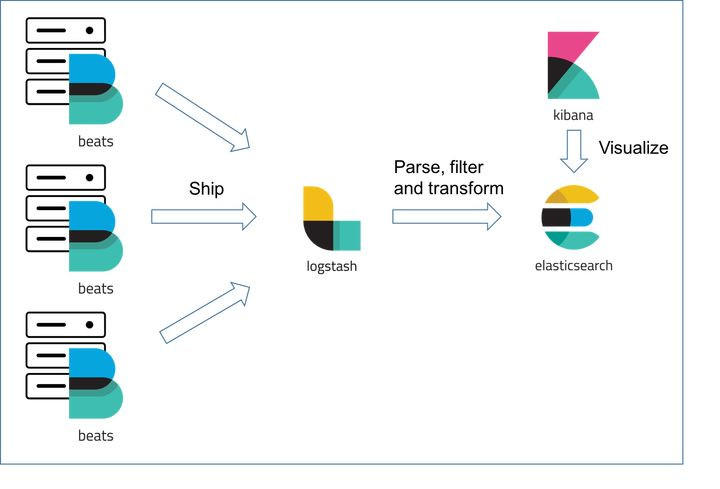
从之前到现在, 主流的还是ELK, 其中的角色满足上面的处理流程.
Logstah负责收集跟处理,
ElaticSearch负责存放JSON跟Index,
Kibana负责查询跟数据展示.
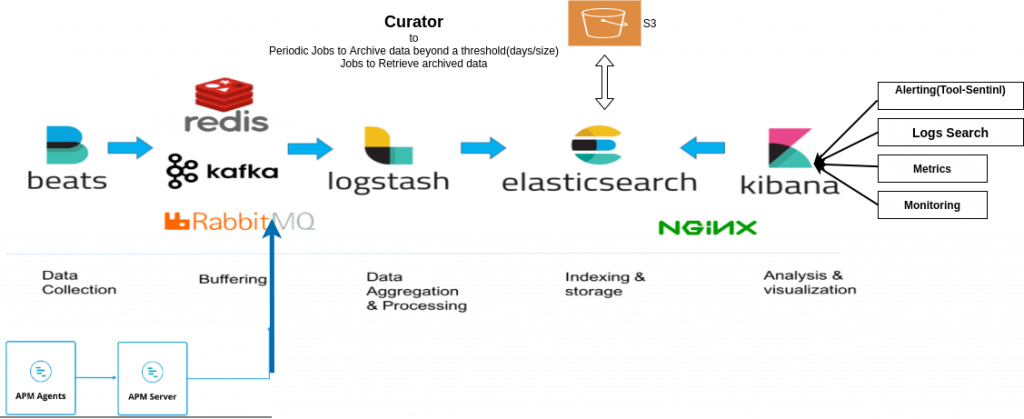
但Elatic并不满足於Log领域,
而後又出现有了Beats家族中的MetricsBeat来负责监控数据的收集.
Elasstic APM负责Distributed Tracing链路追踪的数据收集.
所以Elastic系统已经是一套整合Distributed System Observability三大基石的服务了.
但ElaticSearch的查询与处理, 非常依赖Index, 且ES使用倒序索引来支持全文检索,
这特性有时在监控体系下显得有点杀鸡用牛刀了
後来Docker与Kubernetes出现後, Distributed System的设计几乎是常态了.
Kubernetes主要使用另一组服务Fluent-bit来替代Logstash的脚色, 来收集Log.
且ELK的一些功能要收费之外, 吃的资源也相对较重, 在任何资源都需要持续收费的云端服务上,
就会想能省则省.
刚好CNCF的Observability and Analysis的列表中

Grafana家族在Monitor有Grafana, 在Logging有Loki, 在Tracing有Tempo
跟Prometheus来整合, 达成Observability三大基石.
-
Fluent-bit : 各种Log甚至Http, TCP, MQTT等等的收集与分析过滤
- Promtail : 如果只爬Log文字类型的档案, Grafana提供了这agent来收集Log, 跟Logstash/Filebeat一样的脚色
- Loki : 负责存放, 跟Elasticsearch一样的脚色
-
Grafana : 负责查询与资料展示, 跟Kibana一样的脚色
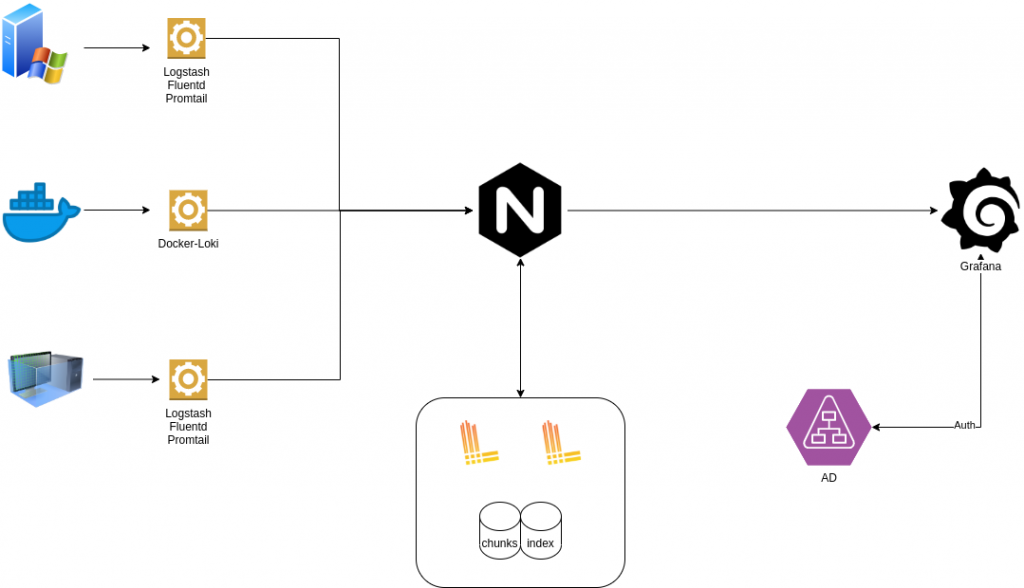
其实2组架构差异不大, 最大差别在Loki, 它并非使用Index与全文检索的机制在提供查询.
而是采用原始的chunk, 只对时间和特定的Label标签做Index.
这听起来跟Prometheus很像?
没错, 就是基於Prometheus的概念出来的.
只是Prometheus强调在Metrics
而Loki则是强调在Logging.
明天来介绍一下Structured Log
後日继续从Metrics与Tracing来介绍.
----参考来源
The Three Pillars of Observability
Rails幼幼班--由seeds认识Rake
什麽时候知道自己已经是大叔了...从看到国民妹妹会露出姨母笑时... 或许这部分比较简单,网路上查不...
【Day6】如何检查型别
前面提到「变数本身没有型别问题,变数带的值才有型别资讯」,所以要判断型别,当然是去检查变数所带的值...
Day5 Android - Layout版面(下)
继昨天讲了的ConstraintLayout,今天要来介绍自己也常用的另外两个布局,LinearLa...
day15 job的骚操作
今天再讲些简单的,顺便复习复习前面的东西,之後又有几天比较硬的内容 我们每次创建coroutine都...
Day 27 PostgreSQL 慢查询提速 50+ 倍?
Odoo的整体运作速度算是很快, 但遇到单资料表破千万笔资料时, 仍然有不断转圈圈的时候, 那该怎麽...