[神经机器翻译理论与实作] 将Encoder、Decoder和Attention统统包起来
前言
今天的任务只有一个:采用物件导向设计法将附带注意力机制的 seq2seq 神经网络封装起来
浅谈物件导向设计的封装概念
物件导向程序设计( object-oriented programming, OOP )让程序具有描述抽象概念的能力,相当於人类具有抽象思考的行为。
类别( class )与物件( object ):
- 类别拥有某些特定特性与功能的抽象概念,例如手机有制造商、型号、出厂年份等特性( attributes ),也能拨打电话、照相、上网等功能( methods )。不同程序语言称呼特性及功能的方式略有差异,在 Python 当中特性被称作属性( attribute ),功能则被称为方法( method )。
- 物件则是拥有类别所描述抽象化概念的实体化( instantiation )结果,例如不到两周前刚发表的手机 iPhone 13 Pro 就是手机这个类别的实物。
Python 也具有物件导向的概念,其类别成员( attributes 与 methods )的访问( access )权限由宽松到严格又分为 public 、 protected 和 private 三种,可藉由 name mangling 的方式修改成员名称来制定不同等级的访问权限。然而关於物件导向的细节就不在这里详细描述了,有兴趣的小夥伴可以参考本篇最下方文章[3]。
物件导向三大特性:封装( encapsulation )、继承( heritance )、多型( polymorphism )
维基百科上对於封装的定义:
In object-oriented programming (OOP), encapsulation refers to the bundling of data with the methods that operate on that data, or the restricting of direct access to some of an object's components. Encapsulation is used to hide the values or state of a structured data object inside a class, preventing direct access to them by clients in a way that could expose hidden implementation details or violate state invariance maintained by the methods.
文字来源:Wikipedia
白话来说,封装就是将一堆执行特定功能的程序码打包起来写入类别,要使用时才被外界呼叫的过程。封装除了使得具有特定功能的程序码被有结构性地呈现而不会散落在各处,能够被妥善管理、便於维护之外,透过指定成员的访问权限,还能使得程序不会任意被更改,达到保护资讯的效果。
图片来源:shouts.dev
使用封装概念定义Encoder、Decoder、Attention及Seq2Seq类别
不免俗套,首先我们引入必要的模组、类别与函式:
from tensorflow.keras import Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Layer, Dense, LSTM, Embedding, Dot, Activation, concatenate
import pydot as pyd
from tensorflow.keras.utils import plot_model
我们先定义 LuongAttention 类别,其继承了 tf.keras.layers.Layer :
class LuongAttention(Layer):
"""
Luong attention layer.
"""
def __init__(self, latent_dim, tgt_wordEmbed_dim):
super().__init__()
self.AttentionFunction = Dot(axes = [2, 2], name = "attention_function")
self.SoftMax = Activation("softmax", name = "softmax_attention")
self.WeightedSum = Dot(axes = [2, 1], name = "weighted_sum")
self.dense_tanh = Dense(latent_dim, use_bias = False, activation = "tanh", name = "dense_tanh")
self.dense_softmax = Dense(tgt_wordEmbed_dim, use_bias = False, activation = "softmax", name = "dense_softmax")
def call(self, enc_outputs_top, dec_outputs_top):
attention_scores = self.AttentionFunction([enc_outputs_top, dec_outputs_top])
attenton_weights = self.SoftMax(attention_scores)
context_vec = self.WeightedSum([attenton_weights, enc_outputs_top])
ht_context_vec = concatenate([context_vec, dec_outputs_top], name = "concatentated_vector")
attention_vec = self.dense_tanh(ht_context_vec)
return attention_vec
接下来定义 Encoder 类别,和 LuongAttention 一样亦为 tf.keras.layers.Layer 的子类别( subclass ):
class Encoder(Layer):
"""
2-layer Encoder LSTM with/ without attention mechanism.
"""
def __init__(self, latent_dim, src_wordEmbed_dim, src_max_seq_length):
super().__init__()
# self.inputs = Input(shape = (src_max_seq_length, src_wordEmbed_dim), name = "encoder_inputs")
self.latent_dim = latent_dim
self.embedding_dim = src_wordEmbed_dim
self.max_seq_length = src_max_seq_length
self.lstm_input = LSTM(units = latent_dim, return_sequences = True, return_state = True, name = "1st_layer_enc_LSTM")
self.lstm = LSTM(units = latent_dim, return_sequences = False, return_state = True, name = "2nd_layer_enc_LSTM")
self.lstm_return_seqs = LSTM(units = latent_dim, return_sequences = True, return_state = True, name = "2nd_layer_enc_LSTM")
def call(self, inputs, withAttention = False):
outputs_1, h1, c1 = self.lstm_input(inputs)
if withAttention:
outputs_2, h2, c2 = self.lstm_return_seqs(outputs_1)
else:
outputs_2, h2, c2 = self.lstm(outputs_1)
states = [h1, c1, h2, h2]
return outputs_2, states
然後是 Decoder 类别:
class Decoder(Layer):
"""
2-layer Decoder LSTM with/ without attention mechanism.
"""
def __init__(self, latent_dim, tgt_wordEmbed_dim, tgt_max_seq_length):
super().__init__()
self.latent_dim = latent_dim
self.embedding_dim = tgt_wordEmbed_dim
self.max_seq_length = tgt_max_seq_length
self.lstm_input = LSTM(units = latent_dim, return_sequences = True, return_state = True, name = "1st_layer_dec_LSTM")
self.lstm_return_no_states = LSTM(units = latent_dim, return_sequences = True, return_state = False, name = "2nd_layer_dec_LSTM")
self.lstm = LSTM(units = latent_dim, return_sequences = True, return_state = True, name = "2nd_layer_dec_LSTM")
self.dense = Dense(tgt_wordEmbed_dim, activation = "softmax", name = "softmax_dec_LSTM")
def call(self, inputs, enc_states, enc_outputs_top = None, withAttention = False):
# unpack encoder states [h1, c1, h2, c2]
enc_h1, enc_c1, enc_h2, enc_c2 = enc_states
outputs_1, h1, c1 = self.lstm_input(inputs, initial_state = [enc_h1, enc_c1])
if withAttention:
# instantiate Luong attention layer
attention_layer = LuongAttention(latent_dim = self.latent_dim, tgt_wordEmbed_dim = self.max_seq_length)
dec_outputs_top = self.lstm_return_no_states(outputs_1, initial_state = [enc_h2, enc_c2])
attention_vec = attention_layer(dec_outputs_top, enc_outputs_top)
outputs_final = self.dense_softmax(attention_vec)
else:
outputs_2, h2, c2 = self.lstm(outputs_1, initial_state = [enc_h2, enc_c2])
outputs_final = self.dense(outputs_2)
return outputs_final
以上定义完了神往网络层,接着定义模型本身 My_Seq2Seq ,其继承了 tf.keras.models.Model 类别:
class My_Seq2Seq(Model):
"""
2-Layer LSTM Encoder-Decoder with/ without Luong attention mechanism.
"""
def __init__(self, latent_dim, src_wordEmbed_dim, src_max_seq_length, tgt_wordEmbed_dim, tgt_max_seq_length, model_name = None, withAttention = False,
input_text_processor = None, output_text_processor = None):
super().__init__(name = model_name)
self.encoder = Encoder(latent_dim, src_wordEmbed_dim, src_max_seq_length)
self.decoder = Decoder(latent_dim, tgt_wordEmbed_dim, tgt_max_seq_length)
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.withAttention = withAttention
def call(self, enc_inputs, dec_inputs):
enc_outputs, enc_states = self.encoder(enc_inputs)
dec_outputs = self.decoder(inputs = dec_inputs, enc_states = enc_states, enc_outputs_top = enc_outputs, withAttention = self.withAttention)
return dec_outputs
def plot_model_arch(self, enc_inputs, dec_inputs, outfile_path = None):
tmp_model = Model(inputs = [enc_inputs, dec_inputs], outputs = self.call(enc_inputs, dec_inputs))
plot_model(tmp_model, to_file = outfile_path, dpi = 100, show_shapes = True, show_layer_names = True)
试着执行一下封装的结果:
if __name__ == "__main__":
# hyperparameters
src_wordEmbed_dim = 18
src_max_seq_length = 4
tgt_wordEmbed_dim = 27
tgt_max_seq_length = 12
latent_dim = 256
# specifying data shapes
enc_inputs = Input(shape = (src_max_seq_length, src_wordEmbed_dim))
dec_inputs = Input(shape = (tgt_max_seq_length, tgt_wordEmbed_dim))
# instantiate My_Seq2Seq class
seq2seq = My_Seq2Seq(latent_dim, src_wordEmbed_dim, src_max_seq_length, tgt_wordEmbed_dim, tgt_max_seq_length, withAttention = True, model_name = "seq2seq_no_attention")
# build model
dec_outputs = seq2seq(
enc_inputs = Input(shape = (src_max_seq_length, src_wordEmbed_dim)),
dec_inputs = Input(shape = (tgt_max_seq_length, tgt_wordEmbed_dim))
)
print("model name: {}".format(seq2seq.name))
seq2seq.summary()
seq2seq.plot_model_arch(enc_inputs, dec_inputs, outfile_path = "output/seq2seq_LSTM_with_attention.png")
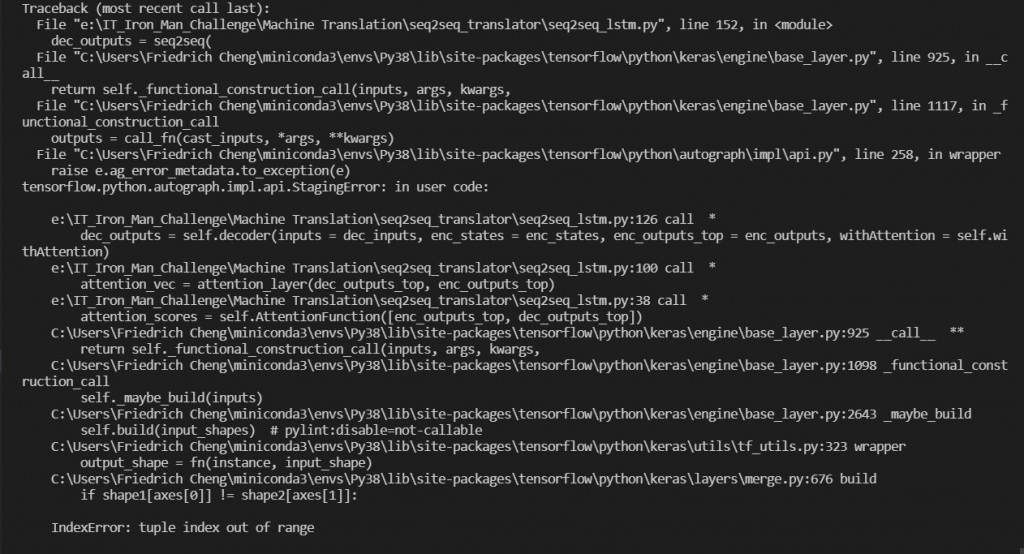
类别虽然定义好了,但执行起来还有一些 bug 
结语
我们有以下残留课题:
- 除虫!
- 用 alignment matrix 呈现输入单词与目标单词之间的关联性
- 比较有无附带注意力机制的 seq2seq 翻译模型之预测准确度
我们将上述问题留着明天继续解决,各位晚安!
阅读更多
- Attention? Attention!
- 什麽是OO?物件导向与封装
- Python进阶技巧 (1) — Private member on Python
- Neural machine translation with attention | TensorFlow
<<: 【在厨房想30天的演算法】Day 18 演算法 : 搜寻 search II 指数搜寻、内插搜寻
.NET Core第18天_InputTagHelper的使用
InputTagHelper: 是针对原生HTML 的封装 新增InputController.cs...
Day14 Django资料库介绍
我们这几天已经学了一些Django的入门技巧了,但之後如果实作时,势必需要储存一些资料在後台。 但我...
Day 10 :Longest Palindromic Substring
不知道做完 Easy版本的Valid Palindrome看到这一题 Medium版Longest ...
[想试试看JavaScript ] for回圈
回圈 for 回圈 for 回圈,很适合用来处理数值会依照次数,有「递增」或「递减」的变化 范例如下...
Day 22 活泼是为了不让人倦怠
一个人应该:活泼而守纪律,天真而不幼稚,勇敢而不鲁莽,倔强而有原则,热情而不冲动,乐观而不盲目。 《...