Day21 - 前处理: 语者正规化
前一天在说明使用的语音特徵时有提到,模型有静态模型跟动态模型两种。在训练静态模型时,因为资料集中的语音档是由不同人(语者,21名男性;30名女性)所录制的,因此我们会使用 cross-speaker histogram equalization(CSHE) 的方式来消除不同语者间的差异性并且只保留情绪的变异。CSHE 会将多个实际语者转换为一个虚拟语者,如此一来我们就能够得到一个虚拟语者的资料分布 ,接下来将每 个实际语者的分布
都转换成虚拟语者的分布
,流程如 图 1。
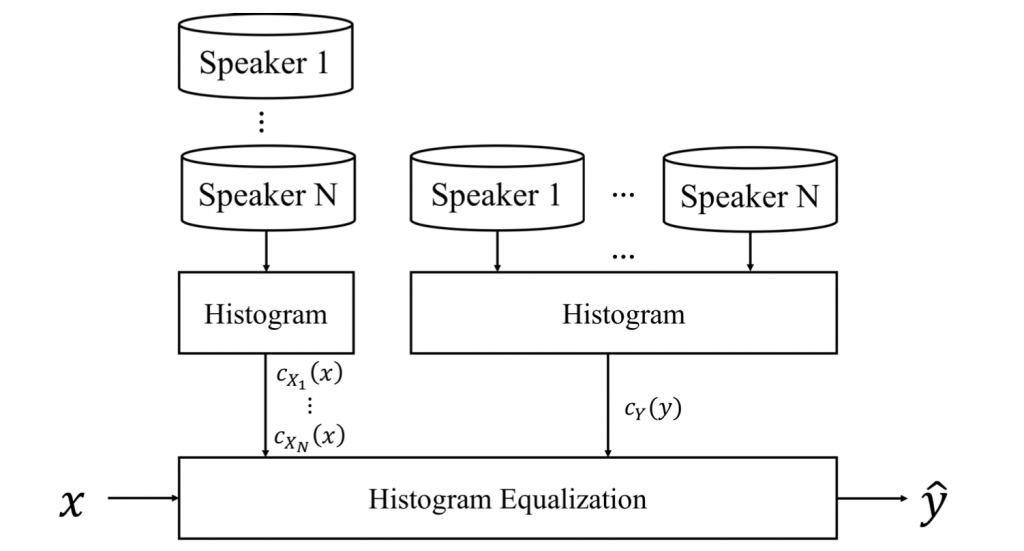
图 1: CSHE流程图。 为 N 个实际语者的分布,
为一个虚拟语者的分布
正规化的方法为直方图均衡法(Histogram Equalization, HE),直方图均衡法是将连续的特徵资料视为各自独立,并将这些资料转换到目标分布上。在此我们用 Y(y) 表示目标分布而 X(x) 表示原始特徵分布,p 表示原始特徵值,q 表示转换後的 特徵值,转换的公式如下:
我们分别计算 X(x) 与 Y(y) 的累积分布函数(Cumulative Distribution Function, CDF),再
将原始特徵值转换至目标分布。
动态模型的部分,采用的特徵正规化方式与语音辨识相同,是使用 CMVN (Day09)。不过在Day09时我们是对每一维特徵做 CMVN,而现在则是对每一个语者中的每一维特徵做 CMVN,因此 CMVN的数学式会变成:
其中,S为语者总数(训练集: 26,测试集: 25), 表示语者 s 中共有 T 个音框,
表示语者 s 中第 t 个音框的第 i 维特徵,
表示语者 s 中第 i 维特徵所有音框的平均值,
表示表示语者 s 中第 i 维特徵所有音框的标准差。
明天我们将继续介绍前处理的部分:资料平衡与标签(label)调整。
<<: 30-18 之 DataSource Layer- DataMapper
>>: DAY18 - 档案处理 - 上传档案前需要知道的FormData
Day 26: KMS/Cloud HSM/Secrets Manager 傻傻分不清楚
如果你有考过 AWS security specialty 证照你一定很常看到KMS/CloudHS...
<Day24> 什麽是上市、上柜、兴柜?什麽是ROD、IOC、FOK?
● 这章会简述及稍微解释一下上市、上柜、兴柜以及ROD、IOC、FOK的差别 首先,让我们再回顾一下...
Swift纯Code之旅 Day24. 「各个TableViewHeader下的Cell显示(1)」
前言 我们已经将TableView的Header给设置完毕了,那可以看到IPhone内建的画面: 两...
Day 23 - 绿专案管理(Green Project Management)
图片来源 继续延续前几篇的话题, 好巧不巧本月(2021年10月)刚出刊的专案经理杂志的封面故事,...
第 15 天 有甚麽事先练再说( leetcode 019 )
https://leetcode.com/problems/remove-nth-node-fro...