[Day 18] 我会把我的over fitting,drop好drop满
前言
走过了资料分析、演算法选择後,
我们得知了有些可以改善模型的方向:
- 解决资料不平衡(Done)
- 学习率的设定(To do)
- 训练轮数(To do)
- 模型深度(No, I want my model to be more efficient ! )
- 阶段式训练(To do)
我用尝试调整类别权重(class weight)解决资料不平衡的问题
但是在介绍学习率之前,
我想先解决一个经典的问题: over fitting
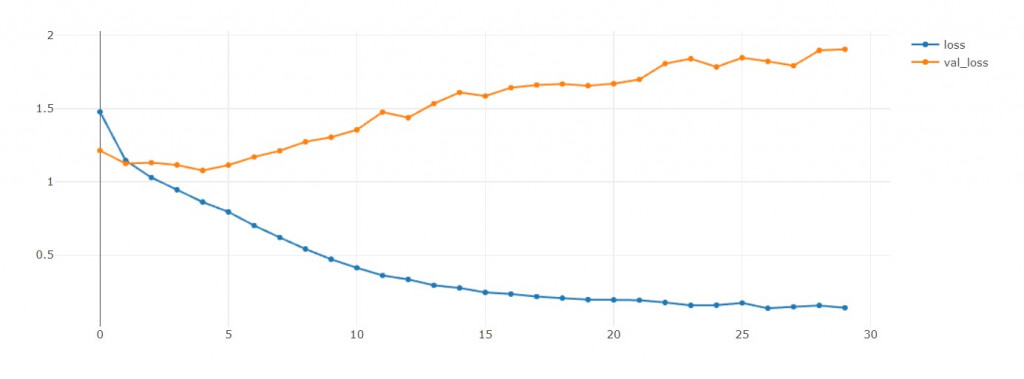
因为在EFN_base当中,
loss和val loss在训练初期就开始往不同方向成长了,
我非常伤心
实验设计
我根据EFN_base的结构,在不同层度上插入dropout layer。
先说一下甚麽是Global Max Pooling(GMP),
就是把每个feature map用最大值取代。
(从"面"变成"点",aka 降维)
假设我最後一层Conv layer有18个feature maps,
那经过GMP後,我就有一层长度为18的网路层。
简单来说就是取代传统Flatten + Dense layer的作法,
来大量地减少参数量,所以可以缓和过拟合问题。
因为GMP本身没有参数,
所以我个人猜想...
- GMP後有些神经元是冗员
- 在GMP後面加一层Dense layer学习,应该可以提升fitting能力。
於是乎我有下列两个设置
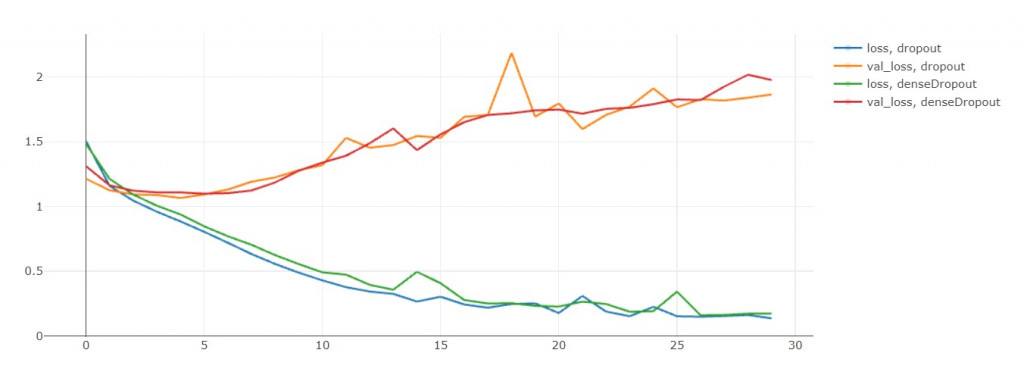
A. Global Pooling後接Dropout (EFN_drop)

B. Global Pooling後接Dense + Dropout (EFN_densedrop)

一样是训练30轮,来看看谁能够帮我解决EFN_base的过拟合问题
实验结果
loss and val_loss
可以看出加上drop对於overfitting没甚麽太大的帮助= =
训练初期(第3轮开始)就val loss就和loss分道扬镳了,
comparing all metrics
| 模型 | 训练时长(秒) | acc | loss | val_acc | val_loss |
|---|---|---|---|---|---|
| EFN_drop | 2471 | 0.953(胜) | 0.136(胜) | 0.635(胜) | 1.865(胜) |
| EFN_densedrop | 2478 | 0.942 | 0.172 | 0.611 | 1.977 |
| EFN_base | 2004 | 0.952 | 0.139 | 0.617 | 1.905 |
结语
看来是EFN_drop在各方面辗压般的胜利,
但这是一个警讯,
即使加了dropout也会过拟合的非常严重,
除了dropout之外,normalization也能减小过拟合问题。
未来我在训练完整模型时,绝对会用到它!
>>: ASP.NET MVC 从入门到放弃(Day28)- MVC web api 加入swagger介绍
高层架构介绍
本系列文章同步发布於笔者网站 我们在前几篇文章介绍了 NIST 对云端的定义,从今天开始文章将会进入...
[Day 20] Facial Recognition: OpenCV + Dlib可以一次满足
想起小时候常看到的一个广告:三个愿望、一次满足! 前两天讲到的孪生网路, 提到一个概念:相似度 (...
Day11 - 使用 Rails Routes 识别用户输入
GitHub 网址:https://github.com/ Heroku 网址:https://w...
Angular 深入浅出三十天:表单与测试 Day13 - 整合测试实作 - 被保人 by Template Driven Forms
昨天帮我们用 Template Driven Forms 所撰写的被保人表单写完单元测试之後,今天...
我们的基因体时代-AI, Data和生物资讯 Day12-基因疗法中之腺病毒载体与机器学习
上一篇我们的基因体时代-AI, Data和生物资讯 Day11-基因疗法中之腺病毒载体与机器学习 我...