JS中的排序法_下
今天Icebear要实作排序演算法简介中的另外3个演算法
积排序(HeapSort)
运作方式 :
在堆积的资料结构中,堆积中的最大值总是位於根节点(在优先伫列中使用堆积的话堆积中的最小值位於根节点)。堆积中定义以下几种操作:
- 最大堆积调整(Max Heapify):将堆积的末端子节点作调整,使得子节点永远小於父节点
- 建立最大堆积(Build Max Heap):将堆积中的所有数据重新排序
- 堆积排序(HeapSort):移除位在第一个数据的根节点,并做最大堆积调整的递回运算
堆积节点的存取 :是通过一维阵列来实现的,在阵列起始位置为0的情形中:
• 父节点i的左子节点在位置(2i+1);
• 父节点i的右子节点在位置(2i+1);
• 子节点i的父节点在位置(2i+1);
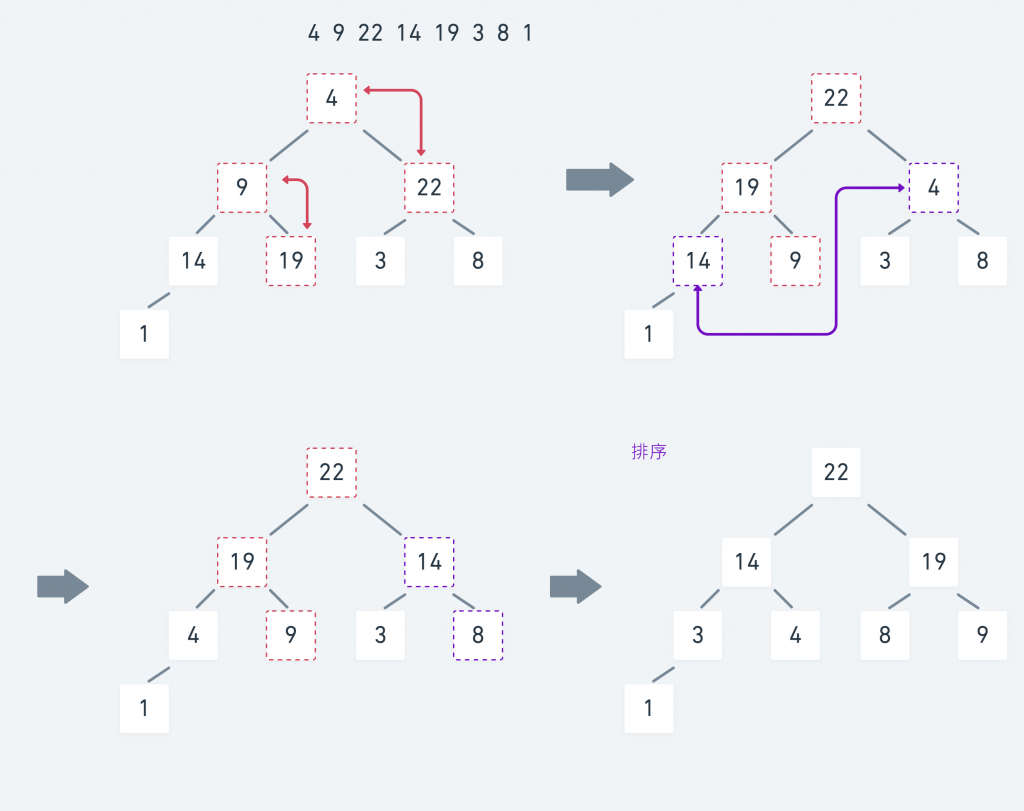
执行过程 :
合并排序(MergeSort)
运作方式 :
• 递回法(Top-down)
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并後的序列
- 设定两个指标,最初位置分别为两个已经排序序列的起始位置
- 比较两个指标所指向的元素,选择相对小的元素放入到合并空间,并移动指标到下一位置
- 重复步骤3直到某一指标到达序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
• 迭代法(Bottom-up) - 原理如下(假设序列共有n个元素)
- 将序列每相邻两个数字进行合并操作,形成(n/2)个序列,排序後每个序列包含两/一个元素
- 若此时序列数不是1个则将上述序列再次合并,形成(n/4)个序列,每个序列包含四/三个元素
- 重复步骤2,直到所有元素排序完毕,即序列数为1
Array.slice() : 意思是截取阵列的某部分,小括号内是要指定撷取片段的begin和 end -> array.slice( begin , end )
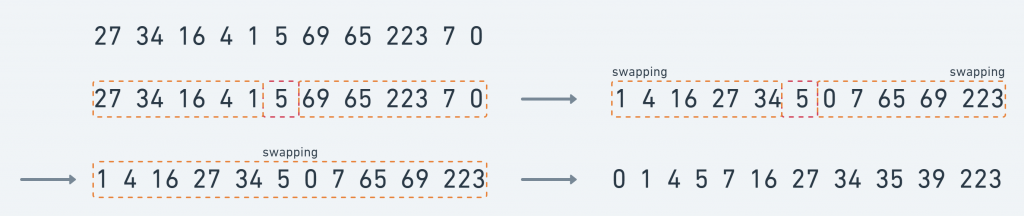
执行过程
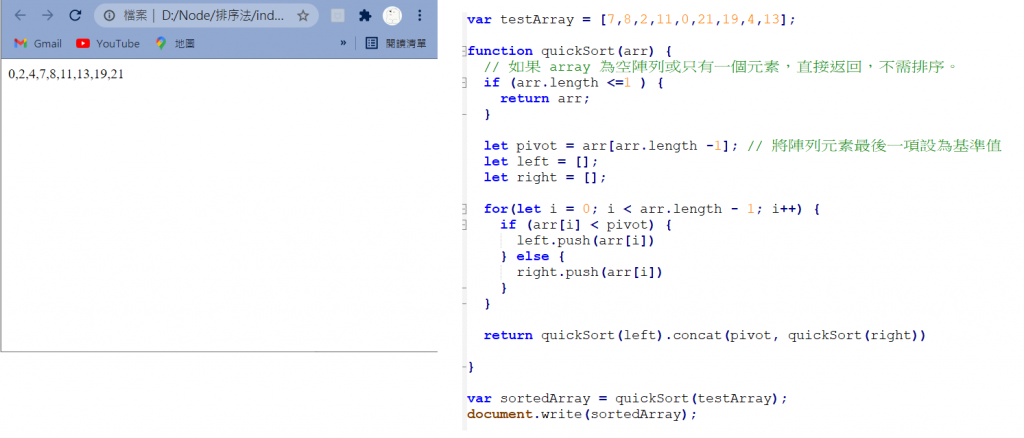
快速排序(QuickSort)
运作方式 :
- 挑选基准值:从数列中挑出一个元素,称为「基准」(pivot)。
- 分割:重新排序数列,所有比基准值小的元素摆放在基准前面 ;所有比基准值大的元素摆在基准後面(与基准值相等的数可以到任何一边)。在这个分割结束之後,对基准值的排序就已经完成。
- 递回排序子序列:利用递回将基准值左右的子序列排序。
通常在挑选基准值时,会挑选中间值或是接近平均值、第一个数或是最後一个数,基准值的选择恨执行的效率息息相关,所以千万不要随便乱选 !!
执行过程

【Day30】 晋升成铁人龙猫之总结
哈罗~ 今天是铁人赛的最後一天, 来抢个团队中第一发文的位子XD 之前每几日来个小结, 最後一天就来...
<重要> 加密货币Token投资警示分享
发生的一个加密货币Token投资的小故事 最近区块链,加密货币一直是现在趋势潮流的新宠儿,无论朋友的...
#17 Automation (5)
今天处里剩下的部分:checker 函式和它注入页面的辅助函式。 checker checker 函...
【课程推荐】2021/3/6~3/7 ISTQB Certified Tester 软件测试工程师(Foundation Level)国际认证班
课程目标 本课程定位为「软件测试入门砖」,课程规划依据「2018 ISTQB Foundation ...
[Day 26] 使用Heroku部署机器学习API
使用 Heroku 部署机器学习 API 今日学习目标 动手部署自己的机器学习 API 使用 Her...