Day 18 : 静态爬虫
今天就来讲讲最基本的静态爬虫吧,这里要装的套件是bs4(BeautifulSoup4),它是用来做静态爬虫的一个专用的库,利用pip install来安装bs4套件
pip install bs4
并且将它引入
from bs4 import Berautifulsoup
再来我们需要用来对HTTP做出请求的库,叫做requests,也是一样利用pip install来安装套件
pip install requests
import requests
爬虫的部分我直接找个范例来做中学,假设今天我们需要IT邦当下的文章标题,以这个为题目撰写一 只爬虫程序。
其实程序码非常的简单,大致分成三个部分,分为HTTP请求、资料爬取及处理以及回圈爬取。
HTTP请求
我们首先要先用request来对指定的URL(网址)送出请求,有点像是使用者连进网站时会对网站送出请求,网站同意後你才能连进去一样,我们在程序码新增下面的程序:
response = requests.get("https://ithelp.ithome.com.tw/articles?tab=tech")
代表我们使用了requests.get这个方法来对後面的网址送出请求,并且将这个事情存到response这个变数中。
这时候如果使用type会发现这个变数的型态叫做这样:

有些网站会专门挡自动化程序或机器人,所以通常在爬虫时都会先伪装成使用者,这时候就需要用到headers这个功能,那这个东西内要放甚麽呢,我们需要放入User-Agent(使用者代理),让网站认为你是真人,这个东西的取的方法很简单,还记得在网站中按下F12可以取得网页原始码吗,同样的,也可以取得User-Agent,先按下F12,应该会看到这个画面(以Chrome做示范):
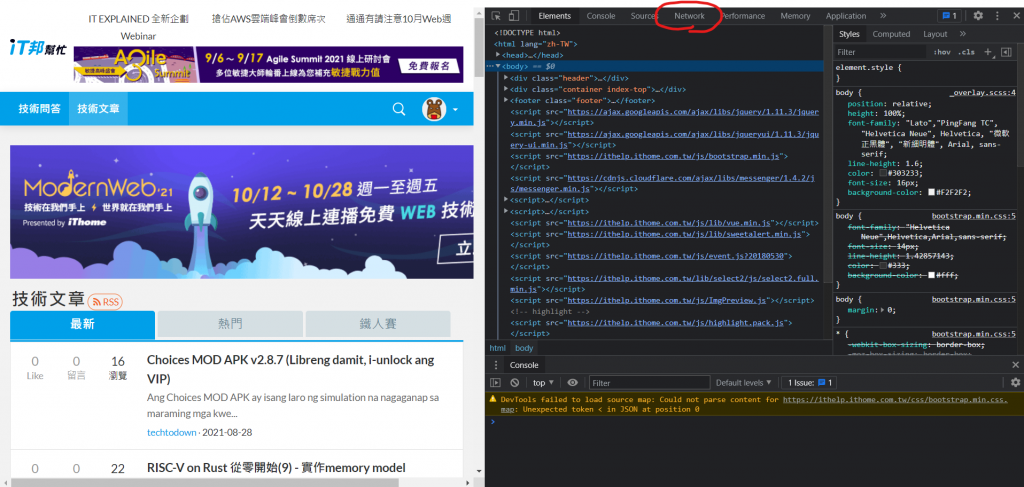
左上角Network点下去
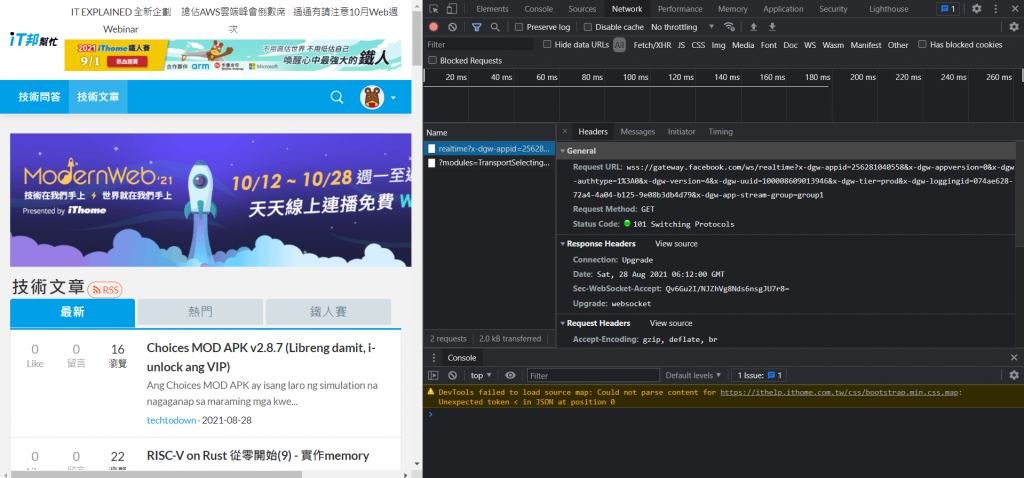
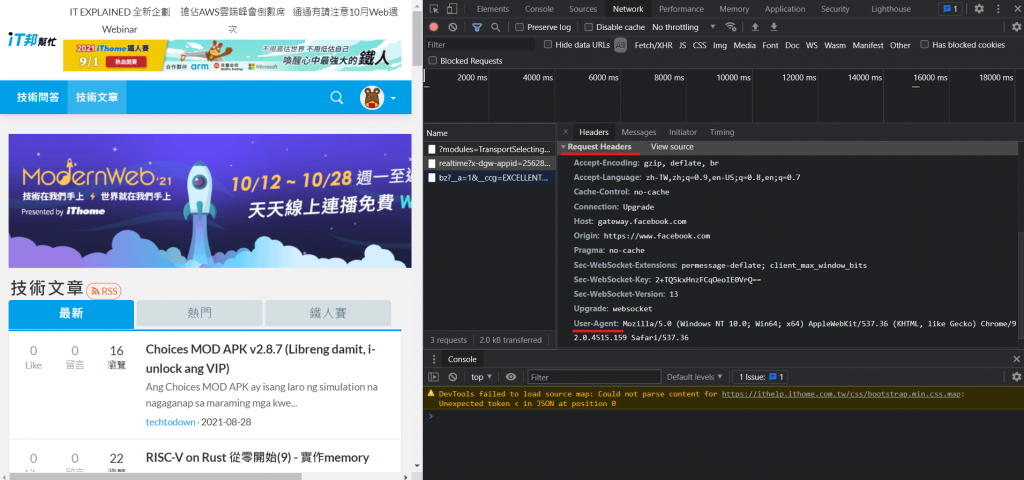
右边往下滑找到Request Headers,下面的User Agent就会显示你目前浏览器的资料了,直接复制,打入程序码中:
response = requests.get(
"https://ithelp.ithome.com.tw/articles?tab=tech",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36"
})
记得网址跟headers中间要有逗号,并且headers是用大括号包住,到这里,HTTP请求部分就好了。
资料爬取
再来重要的就是,要取得网站上的甚麽资料。这时候就要出动BeautifulSoup了,首先,我们要先利用html.parseer(HTML解析器)来解析网站,再来因为我们要取得的是文章标题,所以形式是text。程序码如下:
soup = BeautifulSoup(response.text, "html.parser")
将刚刚的网站内容(已经存到变数response中)用形式为text(文字)的方式用html.parseer解析,并且存到变数soup中。
前置作业都准备好了,再来就是重要的取得内容,我们先在网站上右键文章内容,点取检查:
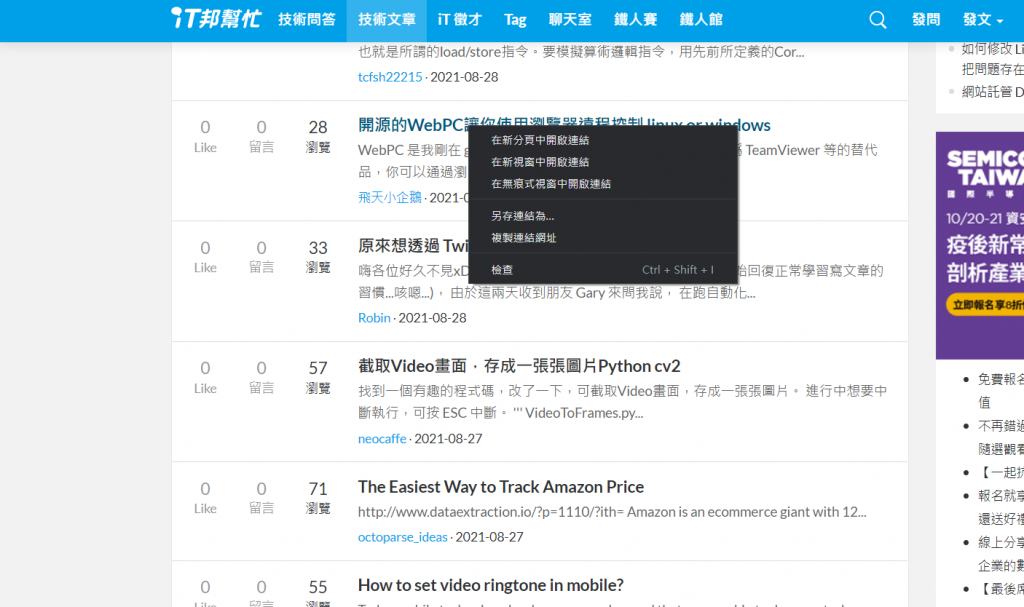
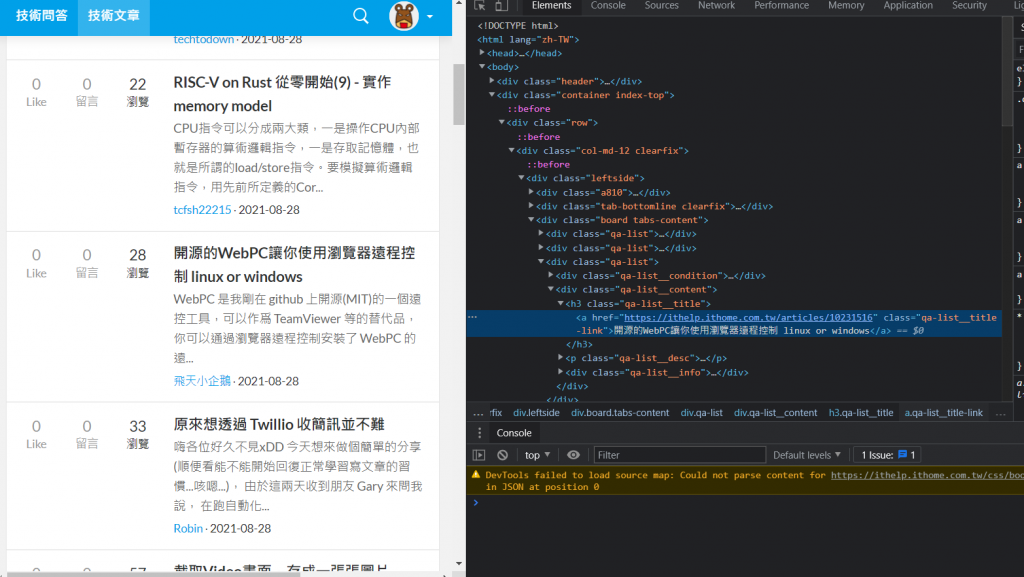
会发现这串文字就在h3 class="qa-list__title"中的a标签内。找了其他的文章名称也是在一样的组合中,所以我们可以使用回圈的方式爬取全部资料,先使用select函式来筛选指定位置的资料:
data = soup.select("h3.qa-list__title a")
将刚刚解析完的html(存到soup变数内了)利用select函式来筛选资料,这边因为是 h3 class="qa-list__title中的a标签,所以格式就是"h3.qa-list__title a",筛选完後存到data,准备进行回圈爬取。
回圈爬取
其实这部分非常的简单,写这样就好了:
for d in data:
print(d["href"], d.text)
写一个for回圈,范围是data,并且定义一个变数(这边用d),然後每次要做的事情就是在刚刚筛选的地方中,print href里面的东西以及这个a标签中的text(文字),href里面的东西就是网址,所以执行後结果会长这样:
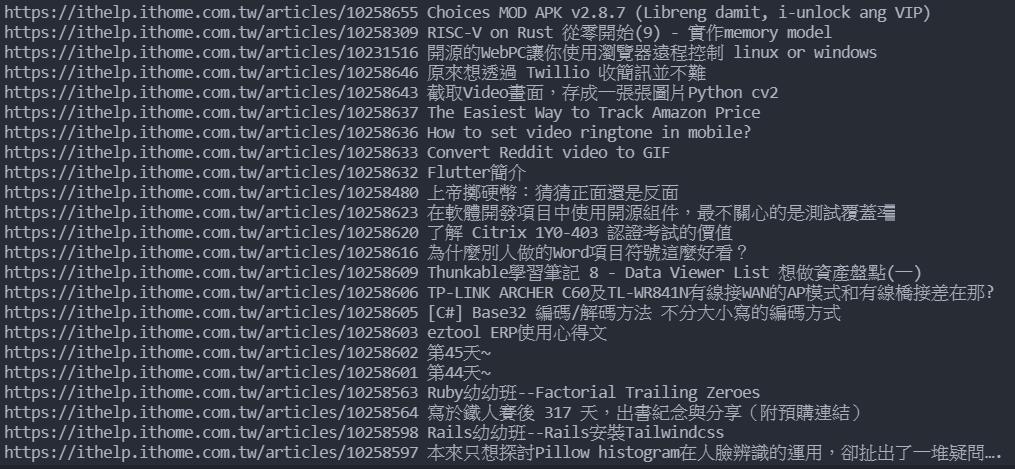
这样是是很方便做资料处理呢!
完整程序码:
import requests
from bs4 import BeautifulSoup
response = requests.get(
"https://ithelp.ithome.com.tw/articles?tab=tech",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36"
})
soup = BeautifulSoup(response.text, "html.parser")
data = soup.select("h3.qa-list__title a")
for d in data:
print(d["href"], d.text)
明天会继续找其他例子来进一步说明爬虫的功能,今天就先到这吧。
<<: 【Day15】代码分割 & 延迟载入 Code Splitting & Lazy loading
>>: Day16法式甜点凸肚脐贝壳-优雅玛德莲Madeleines
Day 06:我们未来再相见
前言一 因为一些原因,今天应该是我铁人赛的完赛日。完成了 20%,剩下的 80%,就留给大家去阅读更...
[Day23] 在 Codecademy 学 React ~ Component Lifecycle 生命周期我不懂你QQ
前言 原本以为生命周期应该很好懂, 但我卡在别的地方, 不过快 12 点了啊我先 po 出我目前进度...
AVFoundation 来看看 Day 19
在第17天,做了一个ISBN 查询 书本的书名、书本描述 那麽今天我希望做一个使用拍照扫描辨识出IS...
Day 30-ASP.NET & SQL资料库制作留言板(下)
-前集提要- 要如何把留言的资料(ASP.NET)存到资料库(MSSQL)的留言板。会使用到的工具有...
Lottie套件使用 及日历制作 Day27
今天根据网路上的资料,试做了一个日历跟使用Lottie套件,未来要作为使用 介绍一下Lottie套件...