[Day 18] 机器学习 boosting 神器 - CatBoost
CatBoost
今日学习目标
- 了解 CatBoost 模型
- 实作 CatBoost 回归模型-房价预测
- 模型训练、特徵筛选
- 超参数搜索
- 自动处理类别型的特徵
- 可解释化模型
前言
CatBoost 同样是基於 Gradient Boosting Tree 的梯度提升树模型框架,最大的特点对类别特徵的直接支援,甚至允许字串类型的特徵进行模型训练。近年来在 Kaggle 上的比赛陆续有人使用 CatBoost 方法并取得不错的成绩,於是就来撰写文章顺便来瞧瞧它与其他 Boosting 演算法不同之处。其中最特别的地方是 CatBoost 能够处理非数值型态的资料,也就是説无需对数据特徵进行任何的预处理就可以将类别转换爲数字。CatBoost 采用决策树梯度提升方法并宣称在效能上比 XGBoost 和 LightGBM 更加优化,同时支援 CPU 和 GPU 运算。与其他 Boosting 方法相比 CatBoost 是一种相对较新的开源机器学习算法。该演算法是由一间俄罗斯的公司 Yandex 於 2017 年所提出,同时在 arxiv 有一篇 CatBoost: unbiased boosting with categorical features 的论文,文中作者详细说明了 CatBoost 的方法与优点。
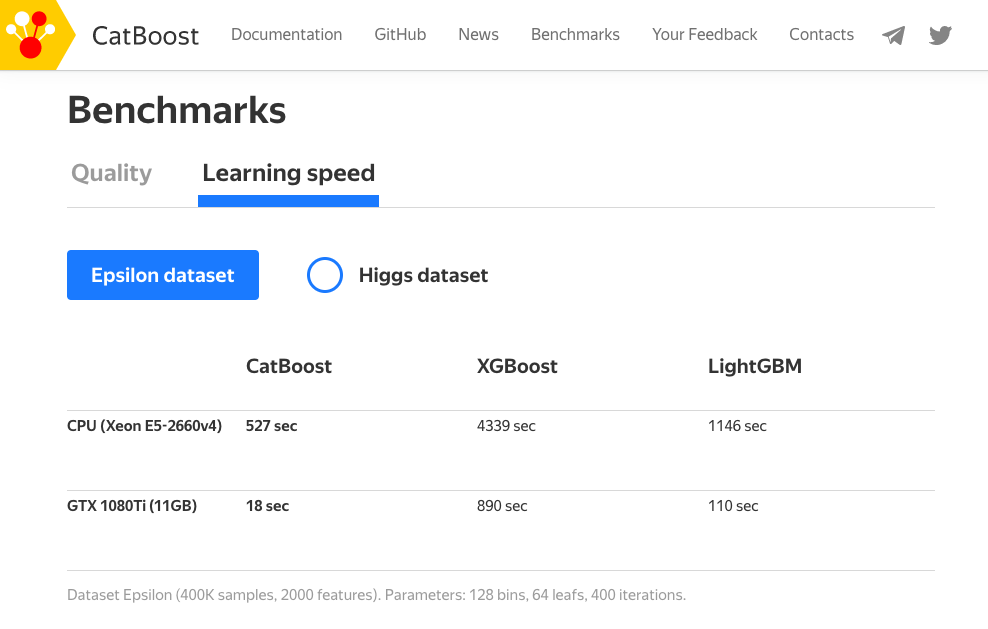
CatBoost 优点
CatBoost 名称源於 Category 和 Boost 两个单词,承袭 Boosting 的优点之外该演算法在类别型的特徵上做了一些更公平的特徵工程。训练过程中允许没有编码的类别特徵,透过分类和数字特徵组合的各种统计量为类别型的特徵做编码。不过在训练前必须确保该特徵中无缺失值。其训练资料若有缺失值 CatBoost 预设会将数值型的资料补上最小值,详细内容可以参考。另外对於 GPU 的使用者,它也能处理字串(类别)型态的特徵。
- 自动处理类别型的特徵
- 自动处理缺失值
- 可以处理各种数据类型,如音频、文字、图像
- 减少人工调参的需要,并降低了过拟合的机会
CatBoost 安装
CatBoost 演算法可以解决分类 (CatBoostClassifier) 和回归 (CatBoostRegressor) 的问题。安装的方式也非常简单,使用 pip 就能轻松安装。
pip install catboost
CatBoost Parameters
CatBoost 基本上可以自由的让演算法去选择最佳的模型,不过 API 还是提供一些基本的超参数让使用者手动调整。
Parameters:
- iterations: 总共迭代的次数,即决策树的个数。预设值为 1000。
- use_best_model: 设定 True 时必须给定验证集,将会留下验证集分中数最高的模型。
- early_stopping_rounds: 连续训练N代,若结果未改善则提早停止训练。
- od_type: IncToDec/Iter,预设 Iter 防止 Overfitting 评估方式,若设定前者需要设定阀值。
- eval_metric: 模型评估方式。
- loss_function: 计算loss方法。
- verbose: True(1)/Flase(0),预设1显示训练过程。
- random_state: 乱数种子,确保每次训练结果都一样。
- learning_rate: 预设 automatically。
- depth: 树的深度,预设 6。
- cat_features: 输入类别特徵的索引,它会自动帮你处理。
Attributes:
- feature_importances_: 查询模型特徵的重要程度。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
如果需要手动处理 Overfitting 问题可以参考这份官方文件
模型训练
模型训练方式基本上与 XGBoost 一样,如果你熟悉 sklearn 的话 CatBoost 的使用方式基本上大同小异。只不过在 CatBoost 中多了一些方便的方法和参数可以使用。像是在训练过程中可以加上 plot=True,并在 eval_set 参数中插入测试集可以即时看到训练过程的视觉化分析。甚至可以使用交叉验证,在不同的分割上观察模型准确度的平均和标准偏差。
from catboost import CatBoostRegressor
# 建立模型
model = CatBoostRegressor(random_state=42,
loss_function='RMSE',
eval_metric='RMSE',
use_best_model=True)
# 使用训练资料训练模型
model.fit(X_train,y_train, eval_set=(X_test, y_test), verbose=0, plot=True)
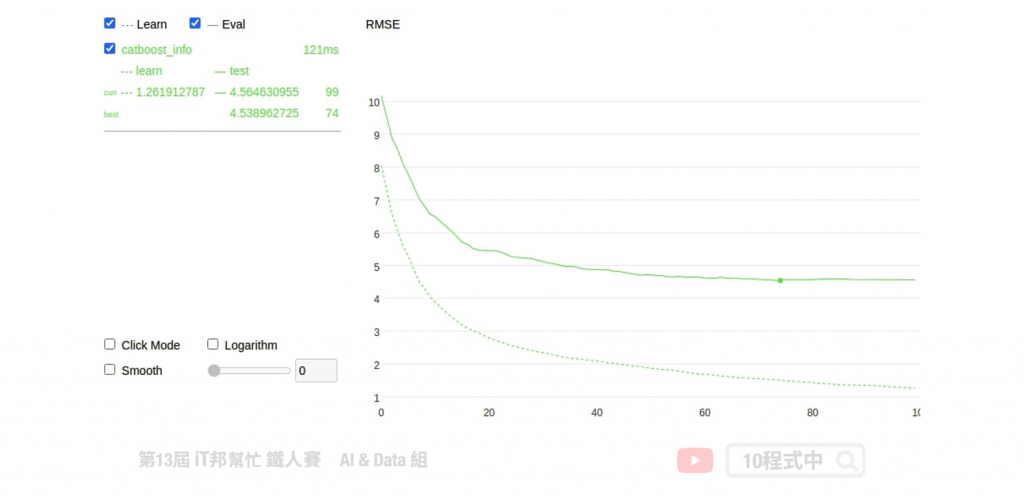
特徵筛选
训练过程中会自动从资料中筛选对模型预测有用的特徵,并移除无帮助预测的特徵。
from catboost import CatBoostRegressor, Pool, EShapCalcType, EFeaturesSelectionAlgorithm
# feature_names = ['F{}'.format(i) for i in range(X_train.shape[1])]
train_pool = Pool(X_train, y_train, feature_names=boston_dataset.feature_names.tolist())
test_pool = Pool(X_test, y_test, feature_names=boston_dataset.feature_names.tolist())
model = CatBoostRegressor(random_state=42,
loss_function='RMSE',
eval_metric='RMSE',
use_best_model=True)
summary = model.select_features(
train_pool,
eval_set=test_pool,
features_for_select='0-12',
num_features_to_select=3,
steps=2,
algorithm=EFeaturesSelectionAlgorithm.RecursiveByShapValues,
shap_calc_type=EShapCalcType.Regular,
train_final_model=True,
logging_level='Silent',
plot=False
)
summary
由於在训练将 num_features_to_select 设为三,即表示模型训练时会拿取三个最重要特徵当作做中模型预测方式。我们采用 sklearn 的房价预测资料集,结果可以发现三个最重要特徵为 ['RM', 'PTRATIO', 'LSTAT']。如果你有做 EDA 可以发现这三个特徵与房价的关联性都很高。
{'selected_features': [5, 10, 12],
'eliminated_features_names': ['DIS',
'B',
'ZN',
'CHAS',
'RAD',
'INDUS',
'CRIM',
'AGE',
'TAX',
'NOX'],
'eliminated_features': [7, 11, 1, 3, 8, 2, 0, 6, 9, 4],
'selected_features_names': ['RM', 'PTRATIO', 'LSTAT']}
Grid search
除此之外 CatBoost 提供对模型的指定参数值进行简单的网格搜索,如果有使用过 sklearn 的 Grid Search 其实他就是一样的使用方式。
from catboost import CatBoostRegressor
grid = {'iterations': [100, 150, 200],
'learning_rate': [0.03, 0.1],
'depth': [2, 4, 6, 8],
'l2_leaf_reg': [0.2, 0.5, 1, 3]}
model = CatBoostRegressor(random_state=42,
loss_function='RMSE',
eval_metric='RMSE')
model.grid_search(grid, X_train,y_train)
自动处理类别型的特徵
CatBoost 无需对数据特徵进行任何的预处理就可以将类别转换爲数字。下面程序为一个分类问题的范例,其中输入特徵的第一个为季节。在机器学习上的认知我们必须将所以字串型资料必须透过标签编码方式转换成数值,然而在 CatBoost 完全不需要。仅需在训练模型时给予参数 cat_features = [0] 即代表资料的第一个特徵需要进行类别转换。另外输出叶不一定要编码後的结果,你也可以丢入文字进行训练只要加上 loss_function='MultiClass' 即可。
from catboost import Pool, CatBoostClassifier
train_data = [["summer", 1924, 44],
["summer", 1932, 37],
["winter", 1980, 37],
["summer", 2012, 204]]
eval_data = [["winter", 1996, 197],
["winter", 1968, 37],
["summer", 2002, 77],
["summer", 1948, 59]]
train_label = ["France", "USA", "USA", "UK"]
eval_label = ["USA", "France", "USA", "UK"]
# Initialize CatBoostClassifier
model = CatBoostClassifier(iterations=10,
learning_rate=1,
depth=2,
cat_features = [0],
loss_function='MultiClass')
# Fit model
model.fit(train_data, train_label)
# Get predicted classes
preds_class = model.predict(eval_data)
# Get predicted probabilities for each class
preds_proba = model.predict_proba(eval_data)
# Get predicted RawFormulaVal
preds_raw = model.predict(eval_data,
prediction_type='RawFormulaVal')
善用 Verbose
训练过程中可以随时观察训练集与测试集的loss,使用verbose=10即代表每10次迭代会显示一次资讯,这种方式也解决每次叠代显示一次的困扰。训练过程中剩余时间也会显示出来。

模型的解释
CatBoost 提供了 plot 可以方便在训练时查看并作即时分析训练趋势。除此之外 CatBoost 也支援 SHAP 增加了模型可解释。详细的使用方式可以参考官方教学。
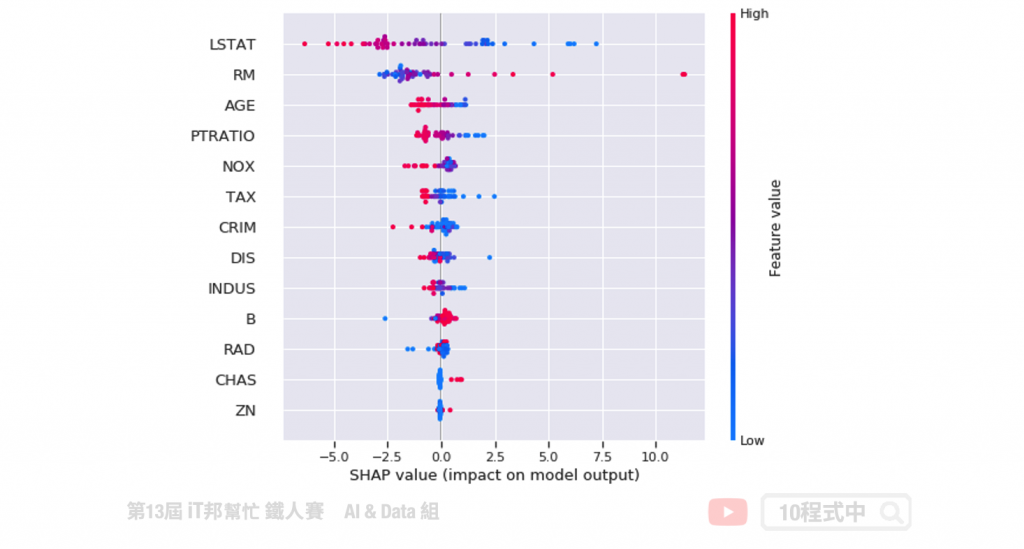
小结
CatBoost 的优点和使用方法都介绍完了,是不是觉得十分简单易用且功能强大。尤其是遇到资料需要大量处理和特徵数值化的任务时最适合使用 CatBoost 了。真的是所谓的懒人套件,名符其实的 Ying Train Yi Fa(硬Train一发)!

Reference
- Tutorial: CatBoost Overview
- SHAP Catboost tutorial
- CatBoost regression in 6 minutes
- Catboost:超越Lightgbm和XGBoost的又一个boost算法神器
- CatBoost、LightGBM、XGBoost,这些算法你都了解吗?
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: Day18 - 语音辨识神级工具-Kaldi part3
>>: LeetCode 双刀流:102. Binary Tree Level Order Traversal
【在厨房想30天的演算法】Day 08 资料结构:堆叠 Stack
Aloha~!我是少女人妻 Uerica!有天地方角头米饭,蒸笼帮的包子、馒头、肉粽起了争执,米饭米...
【Day 28】Cmd 指令很乱,主办单位要不要管一下 (下) - Cmd 指令混淆
环境 Windows 10 19043 System Monitor v13.01 前情提要 在【D...
Day27 简易小键盘小实作2
接续昨天 我们在按钮的action里加入这段程序码, 变数tag-1的部分就是按下1时呈现的数字是刚...
Day 23:1974. Minimum Time to Type Word Using Special Typewriter
今日题目 题目连结:1974. Minimum Time to Type Word Using Sp...
【左京淳的Spring学习笔记】基础案例
使用首页、输入画面、输出画面等三个基础画面,来熟悉画面之间跳转及资料移动的原理。 本练习不涉及业务...