【16】如果把图片从RGB转成HSV和灰阶再拿去训练会怎样
普遍我们拿来训练的图片都是RGB,普遍都是机器学习的CNN层找到一些局部特徵来做分类,这些局部特徵对我们人来说,即使是转成视觉化的特徵值,依然是个谜,既然这样子,如果我们把图片转成HSV,机器一样能够完成任务吗?毕竟对於机器来说,这些像素都是数值。
第二个问题是,其实我们今天把某些照片转成灰阶照片,我们仍然可以一眼看出图片代表什麽(比如猫狗照片转成灰阶,你仍然可以认得哪张是猫哪张是狗),那在机器学习任务时,我们是不是也能够教机器学习灰阶图片呢?这样子训练出来的模型和原先的RGB模型又会有什麽样的差别呢?这就是我们今天要来实验的主题。
在进行训练之前,我们先来看看 tf.image.* 提供了哪些API供我们使用,很刚好地,转成HSV和灰阶都刚好有做好的API可以用。
import cv2
from google.colab.patches import cv2_imshow
def convert_img(image, label):
image = tf.cast(image, tf.float32)
normal = image / 255.
hsv = tf.image.rgb_to_hsv(normal)
hsv = hsv * 255.
gray = tf.image.rgb_to_grayscale(image)
return image, hsv, gray
ds_train = train_split.map(
convert_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
为了确保我们使用 Tensorflow API 转换是正确的,我另外写了和 OpenCV 转换的对照版本,来实测转换是否一致。
首先是 tf.image.rgb_to_hsv,一般我们图片读近来是 uint8 的格式,数值落在 [0, 255],但根据 tensorflow 官方文档,我们发现
The output is only well defined if the value in images are in [0,1]
输入的 image 必须是 [0,+1] 的范围,所以一开始我们必须先将 image / 255. ,转完 hsv 之後,再乘上 255. 变回去 uint8 的数值。
而 tf.image.rgb_to_grayscale ,相对简单,原先的 uint8 就可以直接读进来。
for example in ds_train.take(2):
ex = example
origin = cv2.cvtColor(example[0].numpy().astype(np.uint8), cv2.COLOR_RGB2BGR)
hsv = example[1].numpy().astype(np.uint8)
gray = example[2].numpy().astype(np.uint8)
print('Origin:')
cv2_imshow(origin)
print('\nOpenCV HSV:')
cv2_imshow(cv2.cvtColor(origin, cv2.COLOR_BGR2HSV))
print('\nTF HSV:')
cv2_imshow(hsv)
print('\nOpenCV Gray:')
cv2_imshow(cv2.cvtColor(origin, cv2.COLOR_BGR2GRAY))
print('\nTF Gray:')
cv2_imshow(gray)
我们来看看和 OpenCV 的差异:
原图:

OpenCV 的 HSV:

TF 的 HSV:

发现这两者转换的数值还是有些微的差异,但後面的训练仍用 tensorflow 转换即可,我们只想知道训练最後的 loss 和准确度。
OpenCV 的 灰阶:

TF 的 灰阶:

两者并无太大差异,灰阶转换是OK的。
实验一:使用经过HSV转换的图片来训练
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
image = image / 255.
image = tf.image.rgb_to_hsv(image)
return image, label
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 4.5527e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.9874 - val_sparse_categorical_accuracy: 0.7402
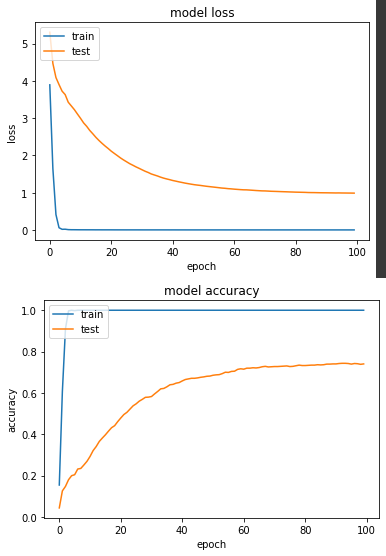
实验二:使用经过灰阶转换的图片来训练
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
image = tf.image.rgb_to_grayscale(image)
image = tf.repeat(image, 3, axis=2) # mobilenet input channel is 3
return image / 255., label
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
这边有个比较麻烦的地方是,原先 mobilenetV2 输入的 channel 是3个,但是灰阶 channel 只有1,所以我透过 tf.repeat 复制成3个 channel,为了不变动模型这样做其实有点冗赘。
产出:
loss: 4.2608e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.8360 - val_sparse_categorical_accuracy: 0.7931
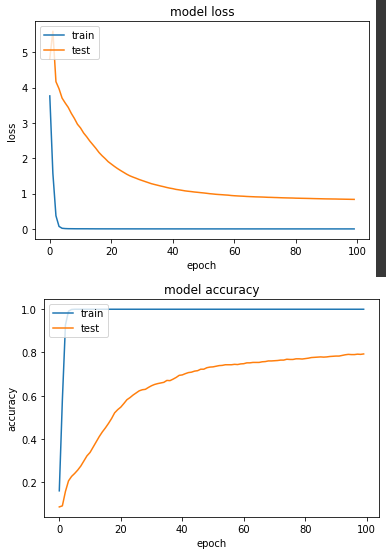
HSV的准确度和灰阶的准确度分别是74%和79.3%,相较於昨天RGB实验一的88.2%,看到这样的结果,想了一下觉得毕竟今天照片呈现的物件是什麽,是由我们人的肉眼根据形状和颜色等所定义,如果今天这个转换去除了颜色这个因素,对机器来说就是个差异性很大的事情,今天只是个小实验满足我的好奇心,各位在做训练任务时还是使用RGB吧。
Day 27 - State Monad II
在上一章,我们提到了如何用一般方法实作 PRNG 乱数生成器,本章将介绍 State Monad 以...
Google Apps Script 语言
Google Apps Script 语言 https://wolkesau.medium.com/...
Day14 - 做一半的产品编辑 modal
今天回顾六角的课程范例,重做一遍产品编辑 modal ,但目前只做了一半 <template&...
【资料结构】前後序求值
前序求值 程序说明 相关函式 get_value():计算并回报结果 说明: 将引入的两个运算元与运...
[Day4]专案始动-续(後端篇)
今天就直接来设定一下MongoDB以及Spring专案的架构,昨天有提到MongoDB是使用Dock...