[DAY14] 在 Azure Machine Learning 里 Label data(下)
DAY14 在 Azure Machine Learning 里 Label data(下)
我们昨天建立好 Label 专案之後,今天就来进行资料标记吧!
开始进行 Data Labeling
-
我们点进去专案之後,可以看到一个 Dashboard,这里会显示你这个标记专案的进度。我们点击左上的 Label Data。
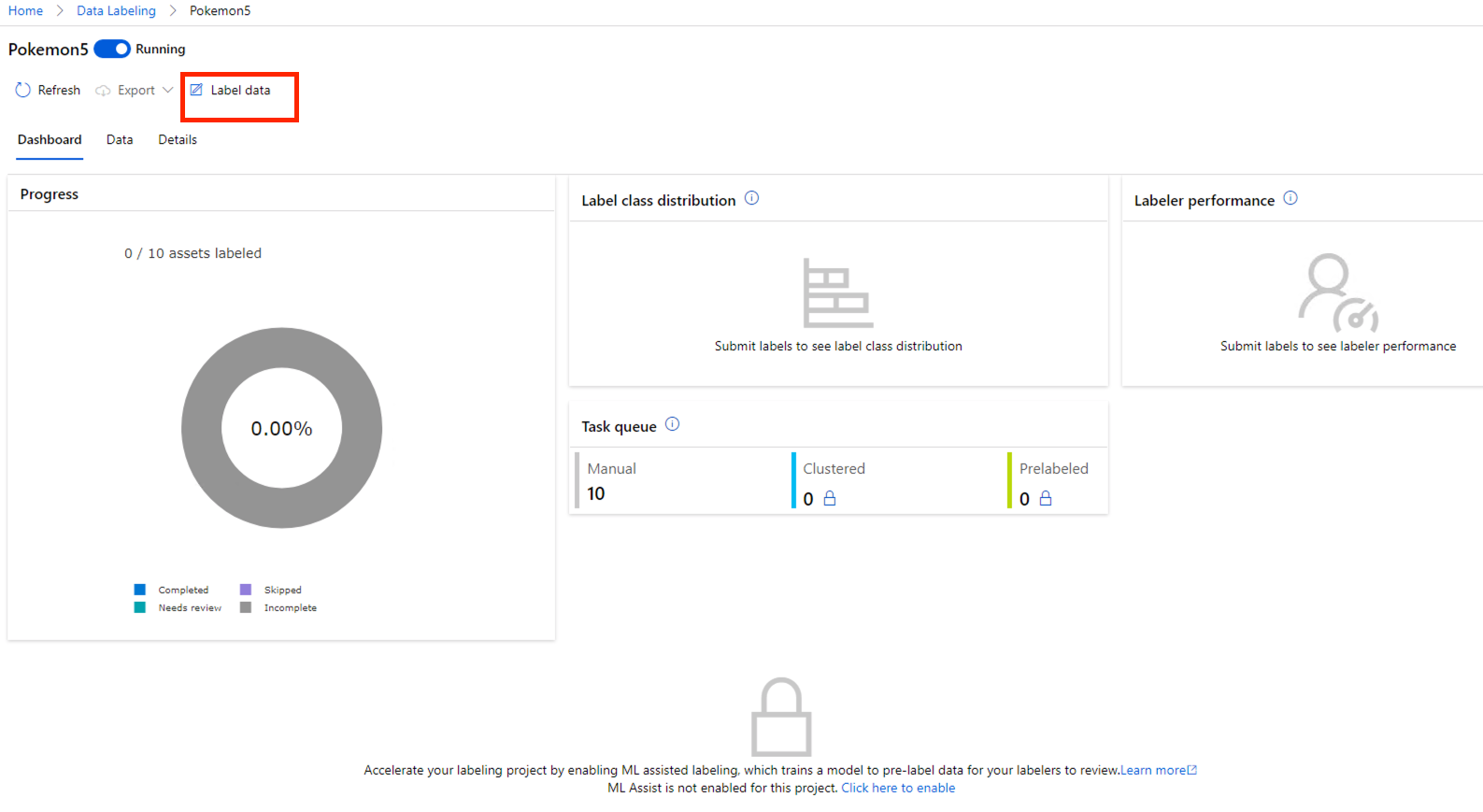
-
接着会先进入 Instructions 的部份,可以看到我们昨天输入的内容。这里我们再补充一下写 Instructions 的原则,根据微软的建议如下:
- 他们会看到什麽标签,以及要如何从中选择? 是否有参考文字可供参考?
- 如果看起来没有合适的标签,该怎麽办?
- 如果有多个看起来合适的标签,该怎麽办?
- 应该对标签套用怎样的信赖度临界值? 是否要他们在不确定时「尽其所能地猜测」?
- 若关注的物体有局部遮蔽或重叠的情形,该怎麽办?
- 若关注的物体在影像边缘遭到裁剪,该怎麽办?
- 如果他们在提交标签後发现作业有误,应怎麽做?
真实世界的专案千万不要像下图随便写写啊 XDD
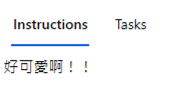
- 接着我们就可以开始进行标记啦!我们可以在右边的选单,针对这一项是什麽,开始进行标记。
- 右上有分格的框框,那个是可以让你一次看很多张以进行标记。
- 中间上方有操作功能,依序可以调整大小、亮度、对比、看属性、跳过、全萤幕。
- 标记完成後,可以点左下角的 Submit,就可以继续标记下一张。
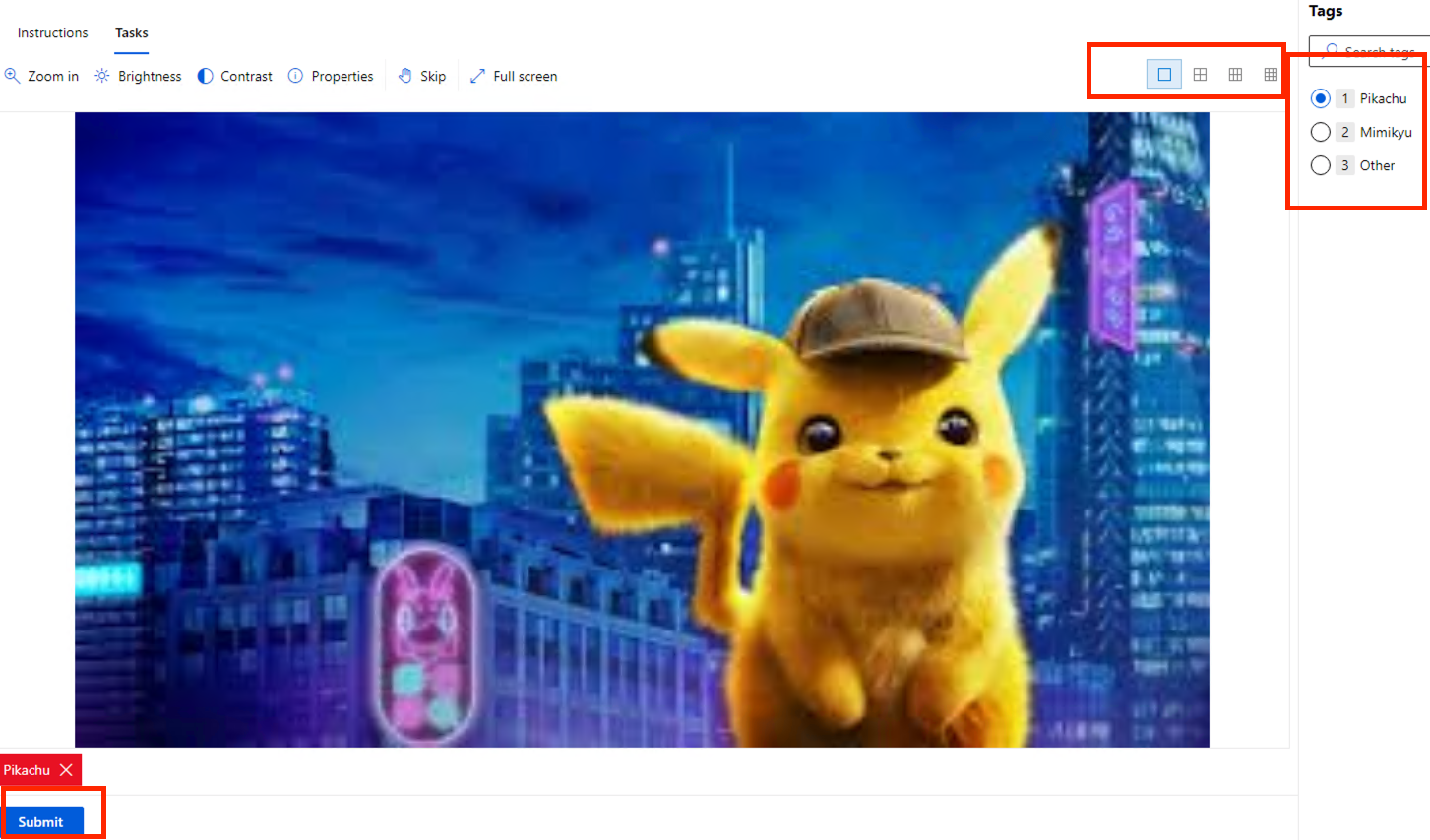
-
标记几张後,我们可以回到主页面,可以看到 Dashboard 有所变化了。
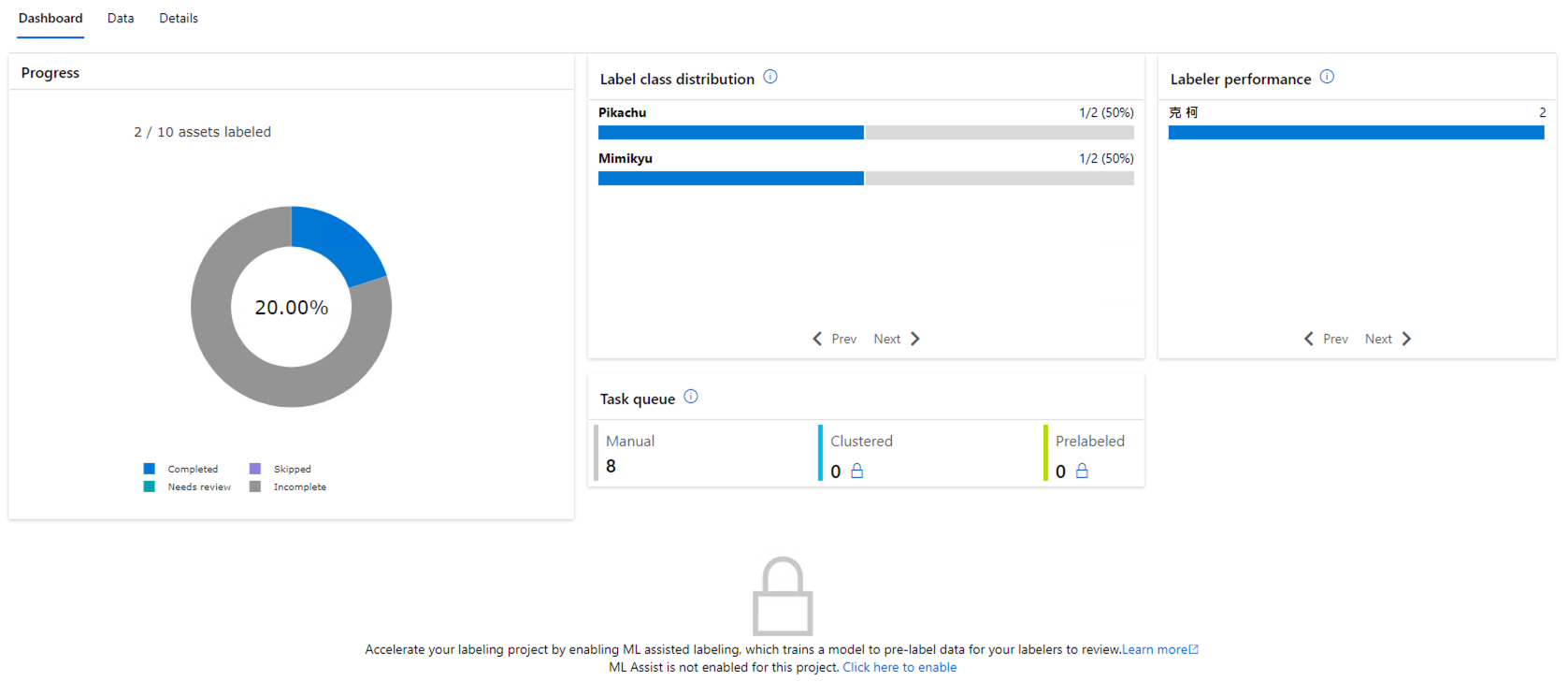
-
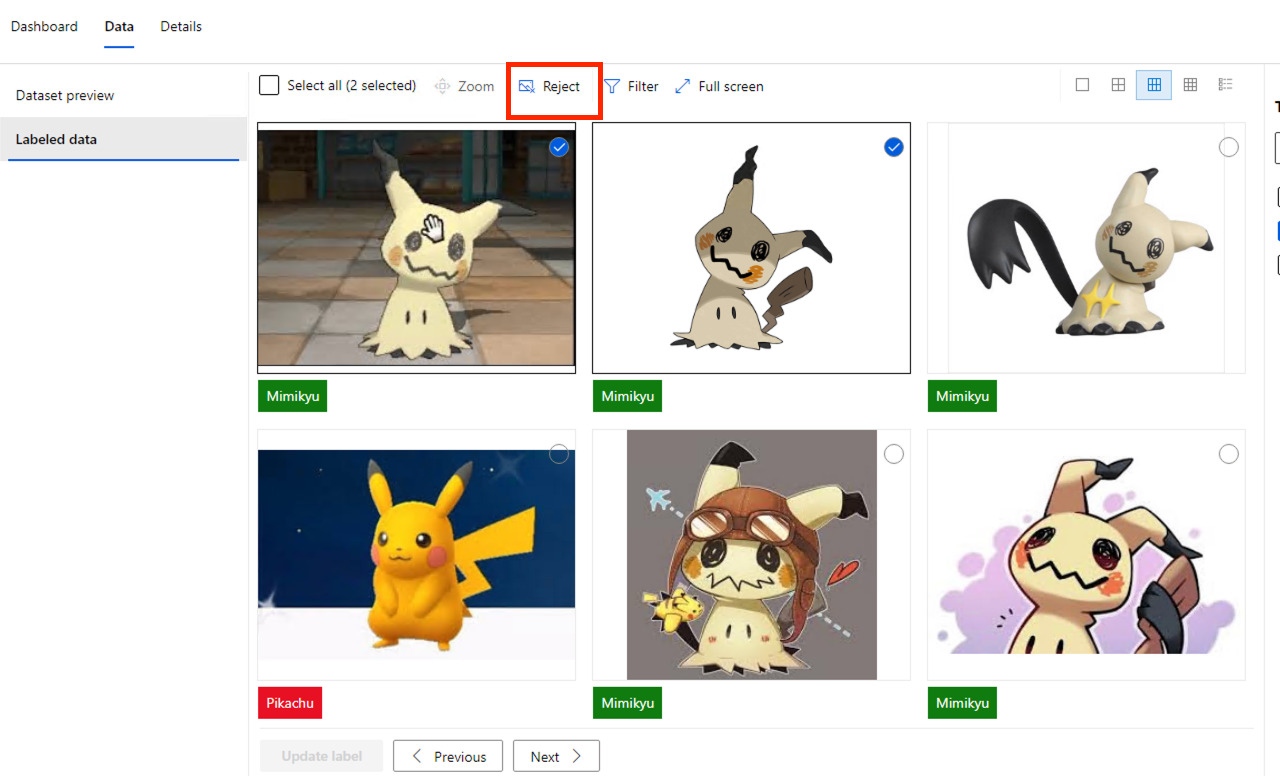
我们离开 Dashboard 的页签,进入 Data 的页签,点左边选单的 Labeled Data,可以来检查这些 Label 是否正确或合格。如果不行的话,可以按 Reject。
-
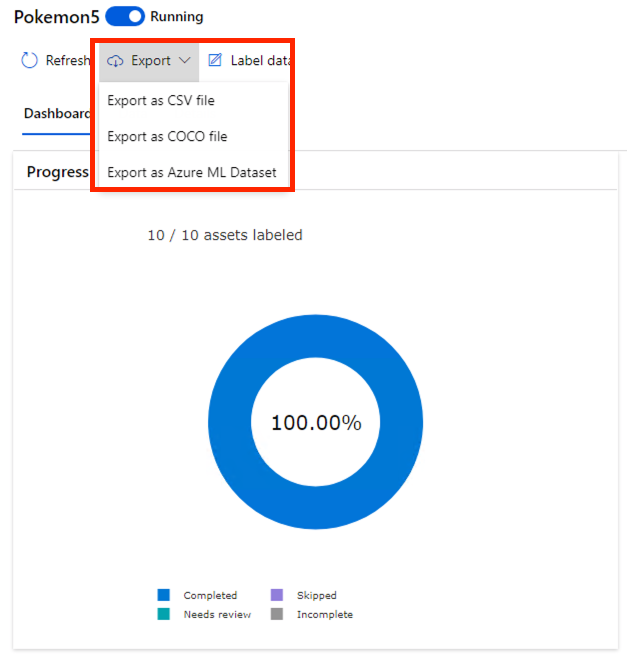
我们把所有的资料标注好之後,回到 Dashboard,点击上方 Export。这里有三种 Export 的格式,CSV 就是 CSV,COCO 是另一种资料集标注的格式,可以参考 COCO Dataset 的网站。我们这里选 Azure ML Dataset。
-
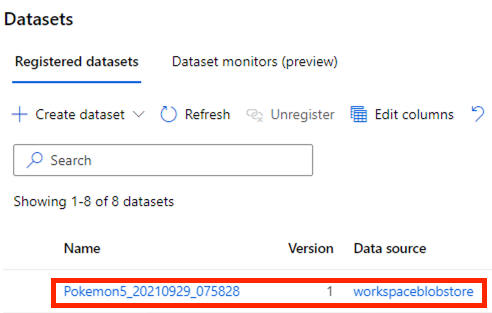
资料量不多的话,很快就会输出好了。我们进到 Datasets 里,就会看到刚刚标记过的资料集啦!
在 AML 里使用影像集资料
-
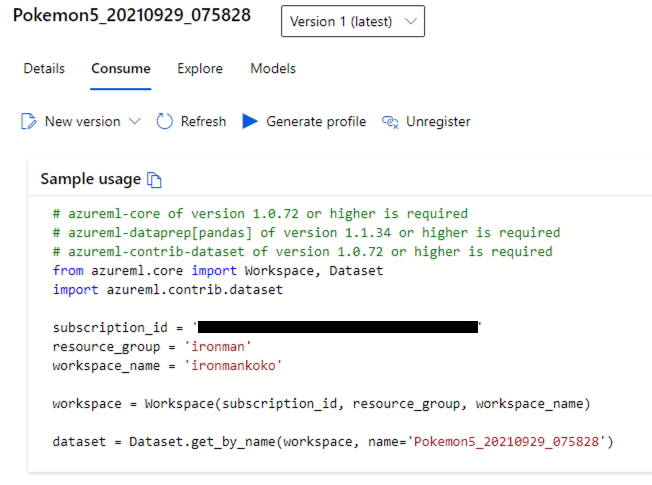
我们点进资料集,到 Consume 的页签,把程序码复制下来。这里的程序码只是把 Dataframe 叫出来而已,还不太符合我们的需求。
-
打开 Notebook 开新档案,我们要用
azureml-contrib-dataset来下载我们的图档。我们输入以下程序码:
(如果没有azureml-contrib-dataset,可以用此指令安装pip install azureml-contrib-dataset)
import azureml.core
import azureml.contrib.dataset
from azureml.core import Dataset, Workspace
from azureml.contrib.dataset import FileHandlingOption
from azureml.core import Workspace, Dataset
import azureml.contrib.dataset
subscription_id = '<Your subscription ID>'
resource_group = '<Your resource group>'
workspace_name = '<Your workspace name>'
workspace = Workspace(subscription_id, resource_group, workspace_name)
pokemon_dataset = Dataset.get_by_name(workspace, name='<Your dataset name>')
pokemon_pd = pokemon_dataset.to_pandas_dataframe(file_handling_option=FileHandlingOption.DOWNLOAD, target_path='./download/', overwrite_download=True)
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#从 dataframe 里把图档读出来
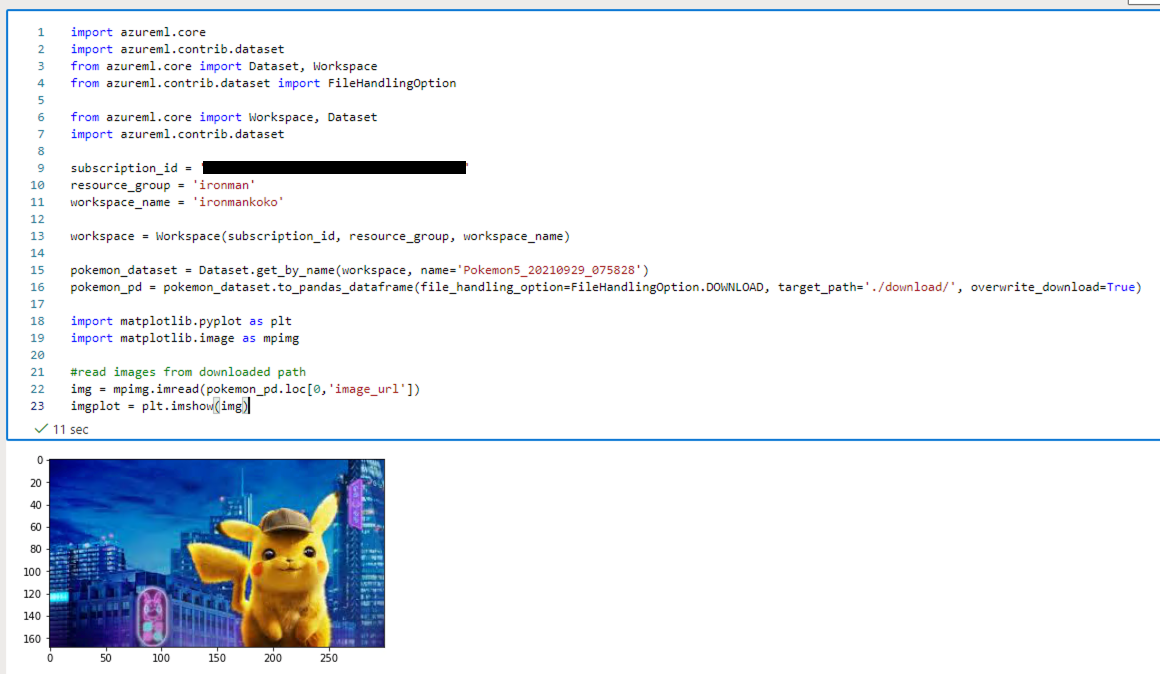
img = mpimg.imread(pokemon_pd.loc[0,'image_url'])
imgplot = plt.imshow(img)
然後可以看到如下图的结果。
- Refresh 左边选单,可以看到那些图档都被我们下载下来的。
以上就是连续三天的资料标记和取用啦!有没有觉得更贴近真实世界 AI 专案的需求了呢?
明天我们开始来谈 AML 多人协作的功能,这个是组建一个 AI 团队不可或缺的功能!
>>: 【没钱买ps,PyQt自己写】Day 14 - 使用 QSlider 制作可拖曳的滑条
Day 02 HTML<表格标签>
表格标签主要用来显示以及展示数据,可用表格标签排版後让数据更容易阅读 1. 表格基础标签简易介绍 (...
[Python 爬虫这样学,一定是大拇指拉!] DAY02 - 关於 Python (1)
所谓工欲善其事,必先利其器。 选择 Python 的理由又是什麽? 那我们得先从语言的特性及优缺点来...
Day08 X 浏览器架构演进史 & 渲染机制
「在未来,浏览器会变得越来越强,以後我们可以在浏览器做越来越多事。」 身为常与浏览器共舞的 Web...
[PoEAA] Data Source Architectural Pattern - Active Record
本篇同步发布於个人Blog: [PoEAA] Data Source Architectural P...
Day 13:杂凑表(hash table)
在通讯录或朋友列表里,我们可以搜寻一个名字,就找到电话或页面,只需要O(1)。如果想要实现这样的操作...