【第二十七天 - Dijkstra 题目分析】
-
先简单回顾一下,今天预计分析的题目:
-
题目连结:https://leetcode.com/problems/path-with-maximum-probability/
-
题目叙述
- 题目给 n 个节点,并且 edges 会储存从 a 点到 b 点的边(无向图),succProb 储存 a 点到 b 点的「成功概率」
- 计算从 start 点到 end 点的最大成功机率,若无法抵达,则回传0

-
测资的 Input/Output
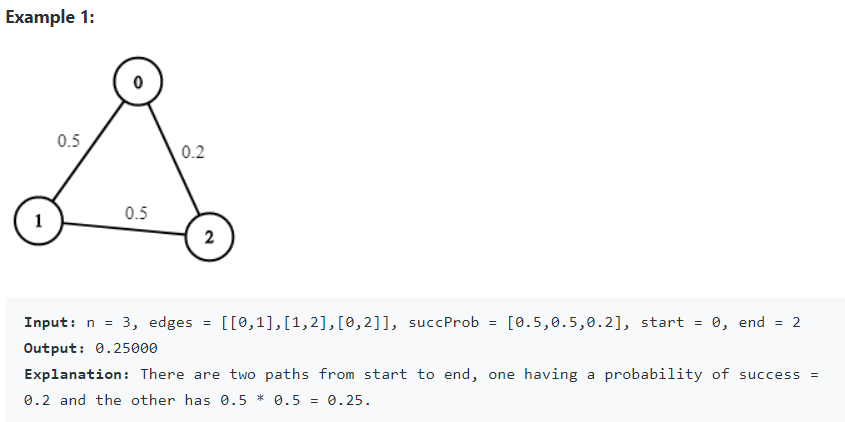
- 如范例1,第0点抵达第2点有两种走法: 0→1→2 与 0→2
- 需要回传 start → end 点最高成功机率: max(0→1→2 ,0→2) = max(0.5*0.5,0.2) = 0.25
程序逻辑
-
由於 n 可能到 10000,用二维阵列储存 edge 的话,效能不佳。因此此处使用 list 的方式纪录每一点存在的边。
mapping = [[] for _ in range(n)] for i in range(len(edges)): (a, b), prob = edges[i], succProb[i] mapping[a].append((b, prob)) mapping[b].append((a, prob)) -
虽然是求最大机率,但由於机率相乘只会越来越小 (因为机率 ≤ 1),正好可以使用 dijkstra 来解此问题。
- dijkstra 找寻最短路径的条件是不能有负权重,也就是每走过一个节点,必然会
新的路径长 ≥ 原始路径长。 - 若是将机率乘以负号,大小反转,正好就变成求最小机率,并且每走过一个节点,
新的权重≥ 原始权重。
- dijkstra 找寻最短路径的条件是不能有负权重,也就是每走过一个节点,必然会
-
使用 dijkstra 演算法,我们需要开一个一维阵列储存最大机率(最短路径)。
maxProb = [0] * n maxProb[start] = 1- 起点走到自己的机率是
100%,因而设为1。 - 换个方式解读就是自己走到自己,路径长仍然不变
1 x 1 = 1。
- 起点走到自己的机率是
-
依据 Dijkstra,每一轮要找出机率最大者进行走访(路径长最小者),然而如果每一轮都要扫描一次找出最大值,会严重影响效能,导致 TLE,此处我们使用 priority queue 来实作。
- 开一个 queue,放入起点及其机率。由於 Python 的 Priority queue 预设是由小到大,为了能取到最大机率,这边将权重放入前後都要乘以负号,反转大小。
pq = [(-1, start)]- 用回圈每次取最大机率者
while pq: curProb, cur = heapq.heappop(pq) curProb = -curProb- 若当前取到的节点为欲计算的终点,则我们已然找到其最大机率,後面就不需要再做下去了。
if cur == end: break -
若还没走到终点,则以现在的节点出发,若能走出更大的机率,就将该节点与机率放入 queue 中。
for i, prob in mapping[cur]: newProb = curProb * prob if newProb > maxProb[i]: maxProb[i] = newProb heapq.heappush(pq, (-newProb, i))- 由於 priority queue 会帮助我们先取到最大机率者,所以即便以前对同个节点放入过较小的机率也无妨,会被自动丢到後面去。
-
最後,回传走到终点最大机率
return maxProb[end] -
完整程序码如下:
class Solution:
def maxProbability(self, n: int, edges: List[List[int]], succProb: List[float], start: int, end: int) -> float:
mapping = [[] for _ in range(n)]
for i in range(len(edges)):
(a, b), prob = edges[i], succProb[i]
mapping[a].append((b, prob))
mapping[b].append((a, prob))
maxProb = [0] * n
maxProb[start] = 1
pq = [(-1, start)]
while pq:
curProb, cur = heapq.heappop(pq)
curProb = -curProb
if cur == end: break
for i, prob in mapping[cur]:
newProb = curProb * prob
if newProb > maxProb[i]:
maxProb[i] = newProb
heapq.heappush(pq, (-newProb, i))
return maxProb[end]
heapq 参考资料:https://docs.python.org/zh-tw/3/library/heapq.html
<<: 【後转前要多久】# Day12 CSS - 盒模型 (margin、padding)
>>: 我们的基因体时代-AI, Data和生物资讯 Day27-进阶人工智慧在分子生物学之应用
[Day 19] Leetcode 1137. N-th Tribonacci Number (C++)
前言 September LeetCoding Challenge 2021今天的题目是1137. ...
那些被忽略但很好用的 Web API / 结语
Web API -- Application Programming Interface for ...
D12 使用者个人文件页
首页完成後 让使用者可以进入使用者个人文件页 列出属於此使用者的文件 我已经先用测试网页塞了测试资料...
day14 : 前半段小结
参赛将近半个月,终於完成了我认为贴近infra的部分,这也是为什麽要做个小结的原因,大部分企业在使用...
k8s开的kubectl logs路径修改
【YC的迷路青春】 如果不要用预设的路径,例如专案是用tomcat起的,我们不想看tomcat的lo...