[Day 15] 机器学习常胜军 - XGBoost
XGBoost
今日学习目标
- XGBoost 介绍
- XGBoost 是什麽?为什麽它那麽强大?
- XGBoost 优点
- 比较两种整体学习架构差异?
- Bagging vs. Boosting
- Boosting vs. Decision Tree
- Boosting 方法有哪些
- 实作 XGBoost 分类器与回归器
- 比较 Bagging 与 Boosting 两者差别
人人惊奇的 XGBoost
XGboost 全名为 eXtreme Gradient Boosting,是目前 Kaggle 竞赛中最常见到的算法,同时也是多数得奖者所使用的模型。此机器学习模型是由华盛顿大学博士生陈天奇所提出来的,它是以 Gradient Boosting 为基础下去实作,并添加一些新的技巧。它可以说是结合 Bagging 和 Boosting 的优点。XGboost 保有 Gradient Boosting 的做法,每一棵树是互相关联的,目标是希望後面生成的树能够修正前面一棵树犯错的地方。此外 XGboost 是采用特徵随机采样的技巧,和随机森林一样在生成每一棵树的时候随机抽取特徵,因此在每棵树的生成中并不会每一次都拿全部的特徵参与决策。此外为了让模型过於复杂,XGboost 在目标函数添加了标准化。因为模型在训练时为了拟合训练资料,会产生很多高次项的函数,但反而容易被杂讯干扰导致过度拟合。因此 L1/L2 Regularization 目的是让损失函数更佳平滑,且抗杂讯干扰能力更大。最後 XGboost 还用到了一阶导数和二阶导数来生成下一棵树。其中 Gradient 就是所谓的一阶导数,而 Hessian 即为二阶导数。
XGBoost 优点
XGBoost 除了可以做分类也能进行回归连续性数值的预测,而且效果通常都不差。并透过 Boosting 技巧将许多弱决策树集成在一起形成一个强的预测模型。
- 利用了二阶梯度来对节点进行划分
- 利用局部近似算法对分裂节点进行优化
- 在损失函数中加入了 L1/L2 项,控制模型的复杂度
- 提供 GPU 平行化运算
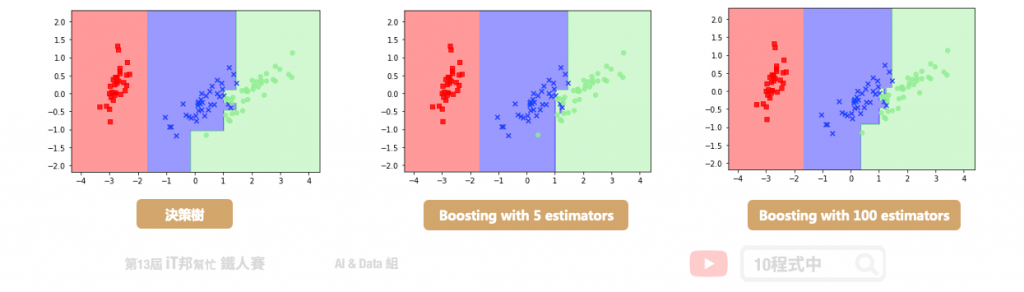
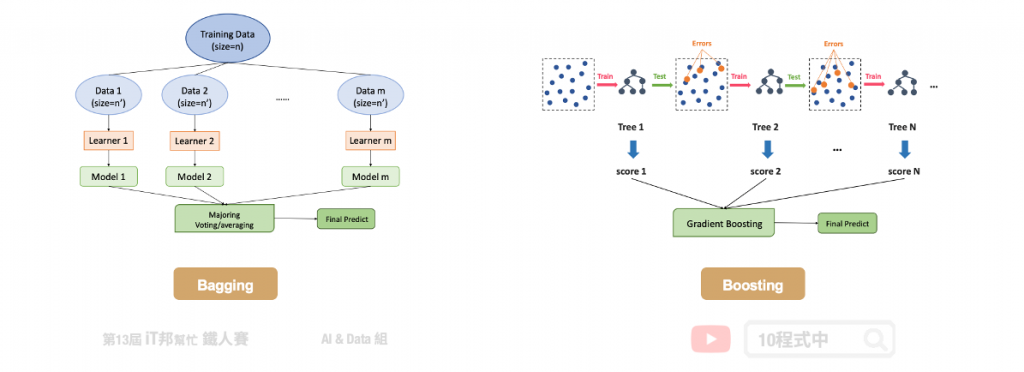
Bagging vs. Boosting
在这里帮大家回顾一下整体学习中的 Bagging 与 Boosting 两者间的差异。首先 Bagging 透过随机抽样的方式生成每一棵树,最重要的是每棵树彼此独立并无关联。先前所提到的随机森林就是 Bagging 的实例。另外 Boosting 则是透过序列的方式生成树,後面所生成的树会与前一棵树相关。本章所提及的 XGBoost 就是 Boosting 方法的其中一种实例。正是每棵树的生成都改善了上一棵树学习不好的地方,因此 Boosting 的模型通常会比 Bagging 还来的精准。
- Bagging 透过抽样的方式生成树,每棵树彼此独立
- Boosting 透过序列的方式生成树,後面生成的树会与前一棵树相关
Boosting vs. Decision Tree
我们再与最一开始所提的决策树做比较。决策树通常为一棵复杂的树,而在 Boosting 是产生非常多棵的树,但是每一棵的树都很简单的决策树。Boosting 希望新的树可以针对旧的树预测不太好的部分做一些补强。最终我们要把所有简单的树合再一起才能当最後的预测输出。
Boosting 方法有哪些
AdaBoost 是由 Yoav Freund 和 Robert Schapire 於 1995 年提出。所谓的自适应是表示根据弱学习的学习误差率表现来更新训练样本的权重,然後基於调整权重後的训练集来训练第二个弱学习器,藉由此方法不断的迭代下去。
- AdaBoost(Adaptive Boosting)
Gradient Boosting 由 Friedman 於 1999 年提出。其中 GBDT (Gradient Boosting Decision Tree) 的弱学习器仅限於只能使用 CART 决策树模型,并采用加法模型的前向分步算法来解决分类和回归问题。
- Gradient Boosting
接下来介绍三个近年三个强大的开源机器学习专案。首先 XGBoost 最初是由陈天奇於 2014 年 3 月发起的一个研究项目,并在短时间内成为竞赛中的热门的模型。接着於 2017 年 1 月微软发布了第一个稳定的 LightGBM 版本。它是一个基於 Gradient Boosting 的轻量级的演算法,优点在於使用少量资源、更快的训练效率得到更好的准确度。另外在同年的 4 月,俄罗斯的一家科技公司 Yandex 发布了 CatBoost,其核心依然使用了 Gradient Boosting 技巧,并为类别型的特徵做特别的转换并产生新的数值型特徵。

未来几天将会介绍 LightGBM 与 CatBoost 哦!
[程序实作]
XGBoost 分类器
Parameters:
- n_estimators: 总共迭代的次数,即决策树的个数。预设值为100。
- max_depth: 树的最大深度,默认值为6。
- booster: gbtree 树模型(预设) / gbliner 线性模型
- learning_rate: 学习速率,预设0.3。
- gamma: 惩罚项系数,指定节点分裂所需的最小损失函数下降值。
Attributes:
- feature_importances_: 查询模型特徵的重要程度。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- predict_proba: 预测每个类别的机率值。
from xgboost import XGBClassifier
# 建立 XGBClassifier 模型
xgboostModel = XGBClassifier(n_estimators=100, learning_rate= 0.3)
# 使用训练资料训练模型
xgboostModel.fit(X_train, y_train)
# 使用训练资料预测分类
predicted = xgboostModel.predict(X_train)
使用Score评估模型
我们可以直接呼叫 score() 直接计算模型预测的准确率。
# 预测成功的比例
print('训练集: ',xgboostModel.score(X_train,y_train))
print('测试集: ',xgboostModel.score(X_test,y_test))
输出结果:
训练集: 1.0
测试集: 0.9333333333333333
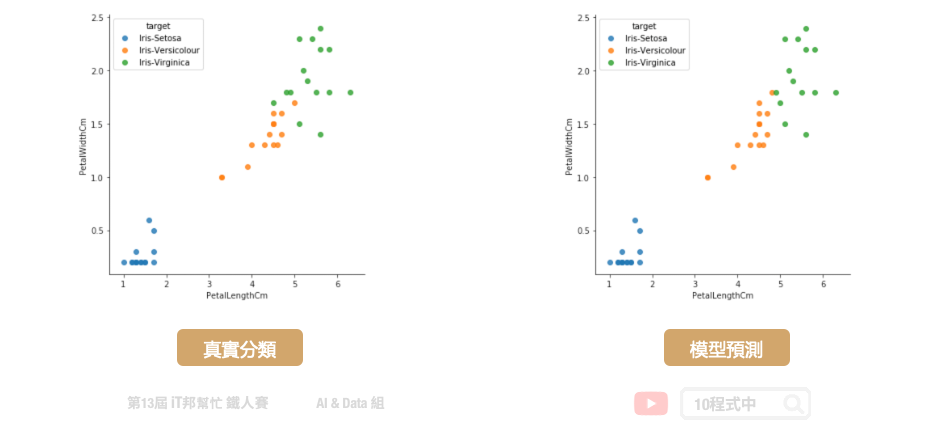
大家可以试着与前几天的决策树和随机森林两个模型相比较。是不是 XGBoost 有着更好的预测结果呢?因为有了 Gradient Boosting 学习机制,大幅提升了预测能力。在学习过程中将预测不好的地方,尤其是橘色 (Versicolour) 与绿色 (Virginica) 交界处有更好的评估能力。
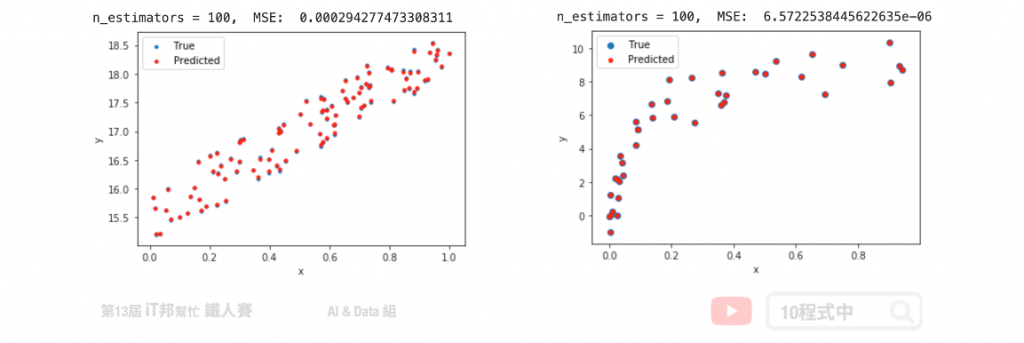
XGBoost (回归器)
Parameters:
- n_estimators: 总共迭代的次数,即决策树的个数。预设值为100。
- max_depth: 树的最大深度,默认值为6。
- booster: gbtree 树模型(预设) / gbliner 线性模型
- learning_rate: 学习速率,预设0.3。
- gamma: 惩罚项系数,指定节点分裂所需的最小损失函数下降值。
Attributes:
- feature_importances_: 查询模型特徵的重要程度。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- predict_proba: 预测每个类别的机率值。
import xgboost as xgb
# 建立 XGBRegressor 模型
xgbrModel=xgb.XGBRegressor()
# 使用训练资料训练模型
xgbrModel.fit(x,y)
# 使用训练资料预测
predicted=xgbrModel.predict(x)
Reference
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: [Day13]程序菜鸟自学C++资料结构演算法 – 二元树的储存与实作
【Day01】数据输入元件 - Button
参赛前言 第一次参赛是 2019铁人赛(连结),也是刚接触 React 不久,透过那次真的觉得收获良...
[职场]拒绝做白工!让自己的努力效益最大化
如果不会表达,那麽你的功劳不是你的功劳。 我想很多人跟笔者一样,从小就被教导谦虚是美德、不要去邀功...
【Day 19】 实作 - 透过 AWS 服务 Glue Job 调整 Partition 以及档案格式
昨天我们已经透过 AWS Glue Crawler 自动建立 VPC Log 资料表,并且我们也看到...
.NET Core第26天_ScriptTagHelper的使用
ScriptTagHelper (脚本标签帮助程序):是针对HTML原生<script> tag的...
那些被忽略但很好用的 Web API / RequestIdleCallback
时间管力大师就是要忙里偷闲 各位应该知道 JavaScript 是单执行绪(单线程)的程序语言,也...