Day 8. Compare × G2 × Slate
这一篇是这一系列 Libraries 比较文实质性的最後一篇了,在下一篇稍做总结以後接着我们就要正式进入到 source-code 解析的篇章了!
这篇我们主要会围绕在 Slate 在官网首页提到的 Principles 来介绍它的特色,为了方便读者阅读,我们还是上个截图(单押 x1

Those Principles
我们先从第 1. 2. 7. 这三点开始说明起:
Slate 专案是搭配 Lerna 建立的 mono-repo,它将它的核心模型(core model)独立出来,自成一个 package
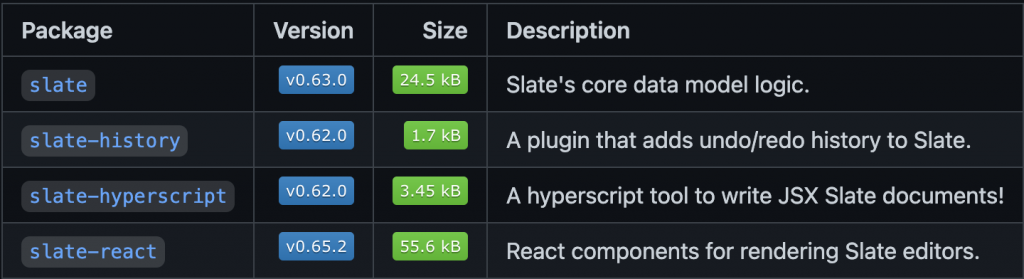
上图就是 Slate 官方完整提供给开发者使用的套件包们,slate package 就是存放着核心模型的套件包,而 slate-react 则是官方提供的 react view layer,这也是我们在上一篇提到过,可以在不同的框架下自己建立的 slate view layer 的原因。
另外 Slate 完全使用 Typescript 开发,基本上所有他提供给你的工具、概念都定义好了一组 extendable 的 base type 让开发者去使用甚至扩充,他提供给开发者的都是底层核心所需用到的最基本的逻辑或是最基本的 use-case 下所需要的工具与 methods,为的都是提供开发者可完全客制化的环境,这同时也是 Slate 自认最重要的特色。
直接来看官方提供,覆盖 editor 的核心 properties 的范例就能深刻感受到他们追求极致客制化的决心了
interface Editor {
children: Node[]
selection: Range | null
operations: Operation[]
marks: Record<string, any> | null
// Schema-specific node behaviors.
isInline: (element: Element) => boolean
isVoid: (element: Element) => boolean
normalizeNode: (entry: NodeEntry) => void
onChange: () => void
// Overrideable core actions.
addMark: (key: string, value: any) => void
apply: (operation: Operation) => void
deleteBackward: (unit: 'character' | 'word' | 'line' | 'block') => void
deleteForward: (unit: 'character' | 'word' | 'line' | 'block') => void
deleteFragment: () => void
insertBreak: () => void
insertFragment: (fragment: Node[]) => void
insertNode: (node: Node) => void
insertText: (text: string) => void
removeMark: (key: string) => void
}
? 是 editor 的 base interface。补充说明一下 editor 就是 slate 提供给开发者开发编辑器时的操作器,比如: children 里存放着主要资料、 selection 里存放着使用者在页面上的反白区域、 normalizeNode 提供对节点进行正规化的方法、 addMark, apply ... 等等的是提供给开发者操作编辑器资料的方法之一。
更详细的介绍放在之後的篇章,目前读者先对它大致有个轮廓就好了。
const { isInline } = editor
editor.isInline = element => {
return element.type === 'link' ? true : isInline(element)
}
? 接着是 override base editor 中 "isInline" 这个 property 的范例。
import { createEditor } from 'slate'
const withImages = editor => {
const { isVoid } = editor
editor.isVoid = element => {
return element.type === 'image' ? true : isVoid(element)
}
return editor
}
const editor = withImages(createEditor())
? 甚至你也能选择透过 "plugin" 的方式在建立 editor 时覆写它的 property
几乎所有我们在 slate package 里看到的一切 methods 甚至资料本身都能轻易地扩充,一些试图扩充所容易导致的 error case 它们也会特别注明,可谓是花费了不小的心力。
接着我们来看看 3.,这边的 document model 指的就是 slate 的资料层,我们曾在 Day3 附上范例图,这边再重放一次帮读者回忆一下,也方便我们介绍
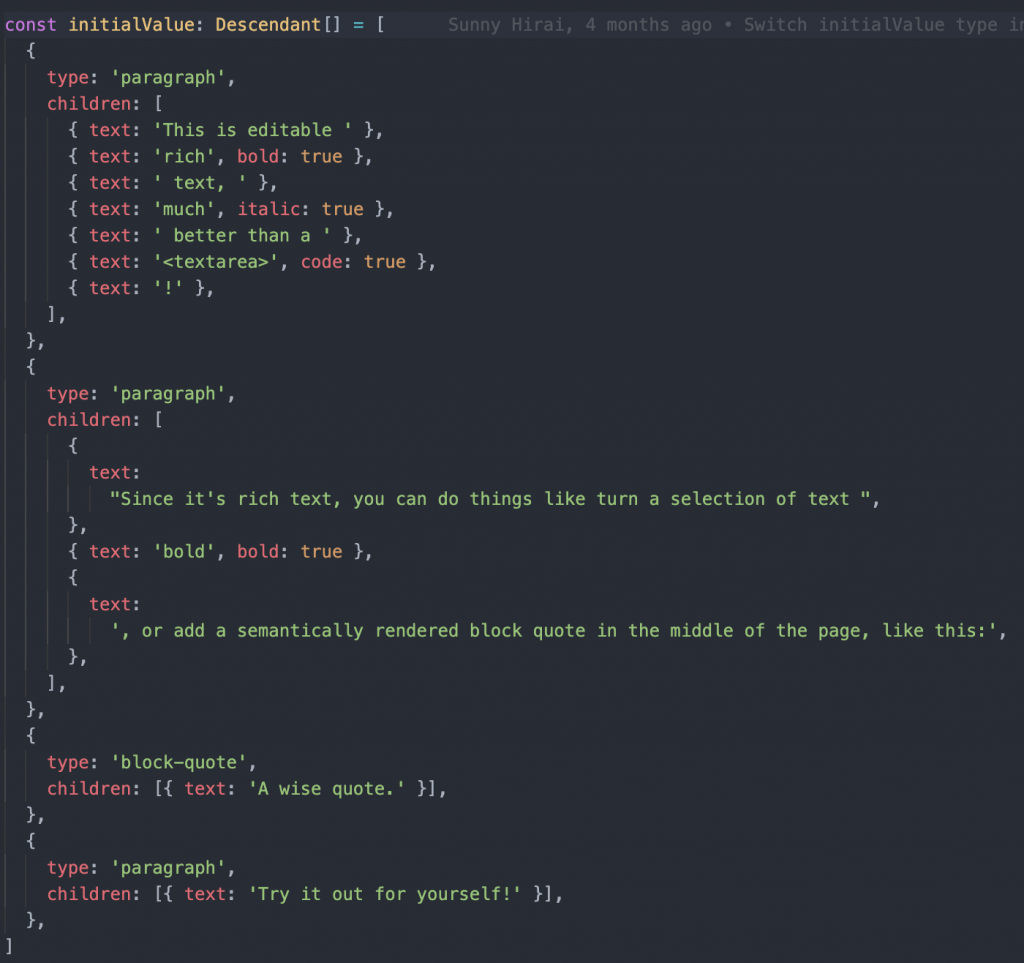
我们会在後续深入解析的章节时再详细介绍,目前先记得结论就好:Slate 采用的 document model (也是开发者主要要操作的资料)是一个近似於 DOM ,巢状且递回的树状结构。只要符合格式规范,它完全不在乎你在 document 里放了哪些资料,以上图为例:
- 与
children同层的 siblings 被归类为Elementtype,只要有符合规范的children栏位,其他栏位都是自定义的,你可以把type这个栏位换成别的名字、别的类别,甚至删掉或新增别的栏位也都没问题。 - 与
text同层的 siblings 被归类为Texttype,只要有符合规范的text栏位,其他栏位也都是自定义的,诸如bold、italic、code这些栏位也都是随便你改,想删掉或增加新的也都没问题,直接想成是 DOM attribute 能更快理解一些。 - 在
Elementtype 的children栏位底下再放上另外一个Elementtype 也是没问题的
也因为这个特性让它在建立 table 或是 nested block quotes 等需要二维以上资料结构的功能时相较於 Draft 显得特别直观。
额外补充 Slate 也内建支援对 HTML 的 serialization 与 de-serialization,这也是归功於这种资料模型让这件事能轻易达成。
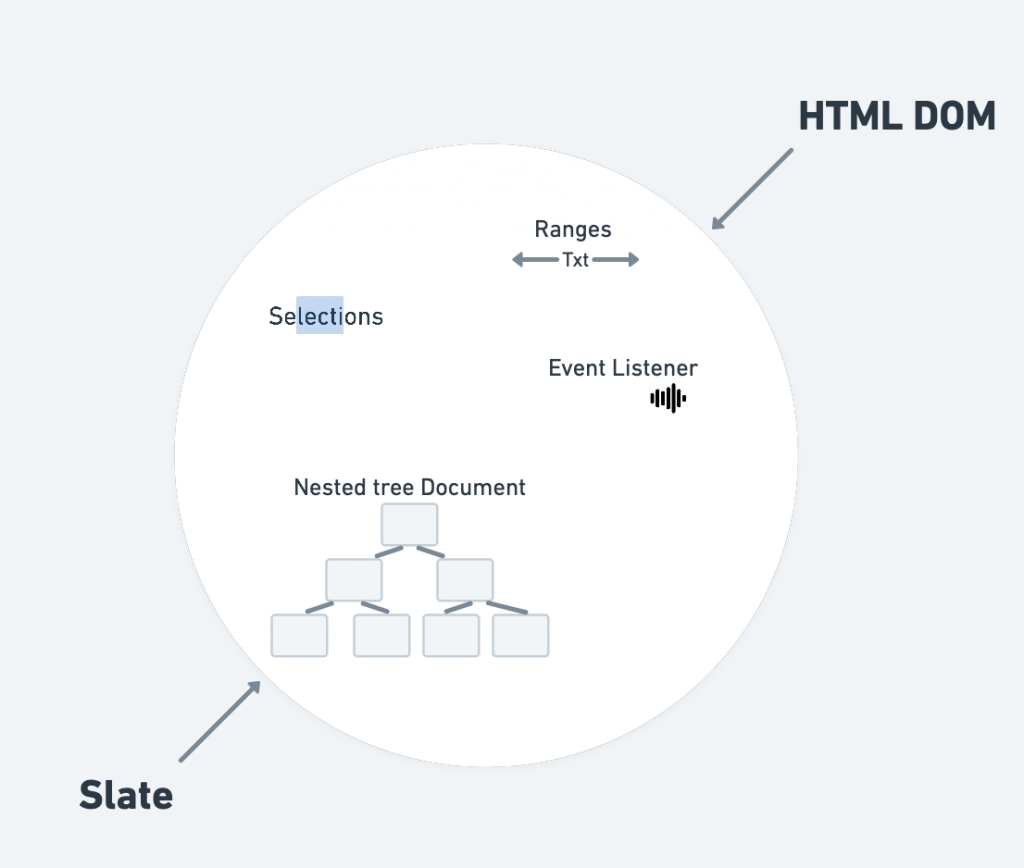
再来是 4. ,Slate 的主要设计原则之一就是要平行於 DOM 开发,它由里到外都被设计地与 DOM 非常相近,为的就是让开发者在开发时能更直观些。
也因此能经常从中挖掘出与 DOM 相似的概念,如: selections 、 ranges 、 offset ... 等等,除此之外无论是 document 设计为 nested tree,再到提供的 methods api 让开发者能各种 access data model ,以及标准的 event handlers 都能在 Slate 中使用,都能看出 Slate 以 DOM 为目标的设计理念,一言以敝之就是基本上在 DOM 上你能做到的任何事,你都能在 Slate 中做到。
这也让它的学习曲线不会到真的那麽抖,虽然操作上与 DOM 的差异依旧存在,但你仍可以以 DOM 的角度去理解与学习,而不用疯狂爬文或开脑洞去学习全新的概念
剩下的 5. 读者可以自行去它的 source-code 意会一下 XD
- 因为官方也没有提供实际范例,笔者也还没有真正开发过这个功能,所以这边就不多做介绍了。
再来还是要聊一下缺点,维持公平公正客观。
主要就是『成熟度』这点上面:
Slate 目前仍在 beta 版本,光是这点就完全无法与其他 libraries 的成熟度作比较了,test coverage 不高,github 上也能看到不少 edge cases 的 issues ,大部分遇到的问题要马自己去 source code 里找答案查 command,不然就是在 issues 跟尚未被 merge 的 pr 里找答案,很多实际踩过雷以後才会厘清的问题存在,而这对於寻求专案稳定度的人来说可能就不太适合。(哪天突然宣布个 breaking changes 工程师就准备加班了 ?
本篇的特色介绍就到此为止,希望能多少引起读者们对它的兴趣,愿意跟我一起深入其中一亏究竟XD
Slate 所提供的功能当然不只如此,我们也会在後续逐步解析 source-code 的过程中慢慢挖掘。
咱们一样下一篇文章见~
<<: Day 11 阿里云架设网站-DNS & 智能流量分流
30天程序语言研究
今天是30天程序语言研究的第九天,研究的语言一样是python,今天主要学习的是档案的写入和写出 网...
DAY 27 Big Data 5Vs – Value(价值) – QuickSight(1)
最後一个「价值Value」也是资料分析最重要的阶段,很重要是因为,只有在资料分析後可以产生比原始资料...
D13 - 彭彭的课程# Python 函式基础:定义并呼叫函式(2)
今天有新闻说北部某医院疫苗注射没有稀释到 各位夥伴我之前也是在北部某联医注射AZ结果院方给我少打剂量...
# Day28--让commit像战国时代一样分分合合
上一篇我们学到怎麽使用Vim,还有修改commit message,这次要做的事情呢,就是要来合并跟...
【Day8】ERP核心模组篇-Invoicing
#odoo #开源系统 #数位赋能 #E化自主 在台湾的中小企业实务上,企业内之会计作业人员基本上都...