课堂笔记 - 深度学习 Deep Learning (18)
上一篇有提到关於如何在向量中求梯度下降的公式,
因此此篇要来讲为什麽要向量v跟f(x,y)的偏微分作内积:
- Properties of the Directional Derivative
首先我们已经知道内积可以有两种算法:
假设现在有 A[a1,a2] 和 B[b1,b2] 要作内积,
- 直接爆开互乘,A dot B = a1 * b1 + a2 * b2
- 长度 * A和B之间的cos夹角,A dot B = |A| * |B| * cosΘ
在这边我们要使用的是第二种方式,
首先假设我们知道公式是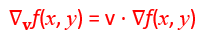 ,
,
也就是v跟f(x,y)的偏微分作内积,
因此把它展开看可以知道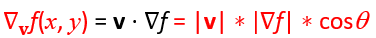
v在这边不重要,因为v只是代表我们在那个向量v带入时所得到的梯度下降,所以这边就先假设他是1,可以得到:
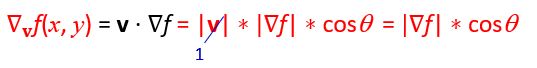
现在可以知道当我们要求出梯度上升的极大值的话,唯一的变数就是cosΘ,而当 Θ = 0°时会有最大值cosΘ = 1,
也就是说当向量v跟f(x,y)重叠时,会有最大的上升值。

相反的,当我们要校正它并测量梯度下降的时候, Θ = 180°时会有最大值cosΘ = -1,
也就是说当向量v向量v跟f(x,y)相反方向时,会有最大的下降值。
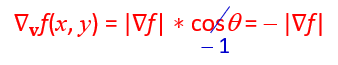
- Gradient Descent of Error Function
於是当我们要透过梯度下降找到最小值的Error Function时,便会采用 ,
,
也就是透过对E(w,b)作偏微分,找到error function自己的梯度关系曲线。
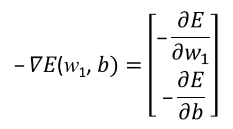
<<: 企业资料通讯Week5 (4) |DNS (网域名称系统)[一]
>>: 课堂笔记 - 深度学习 Deep Learning (19)
12. 使用 async & await (Fetch API)
【9.14补充内容】增加了fetch API的应用,然後修改了一些async & await...
Day 22: Recurrent Neural Network — 循环精神网路初探(上)
Recurrent Neural Network 循环精神网路 RNN是一种专门设计用以解决时间序列...
Day2:AWS Shared Responsibility Model
只要谈到AWS资安议题绝对不能不提到 AWS Shared Responsibility Model...
[Day 27]-【STM32系列】UART/USART RX 资料接收篇(下)
昨日[Day 26]-【STM32系列】UART/USART TX 资料传送篇(上)我们体验了UAR...
Day 9 合格了吗?
启动引擎,把车开回夜晚的车阵中,虽然可能只是处在车流中,默默无名的行驶着,或者快速的疾驶着,又或者处...