Multidimensional Scaling(MDS)
今天想来谈谈一个把高维度资料可视化的应用:MDS,MDS是一种unsupervised machine learning approach 用来降低资料的维度,也有另一个说法叫做Principal Coordinate Analysis(PCoA)。
MDS原理
当MDS要把高维的资料降低成低维度时,会确保样本间的距离保持不变,而如果今天我们把维度降为2,那我们就可以把降维样本画出2D图像来看分布情形。可以应用在侦测资料有没有outliers,或是在做cluster之前也可以先画MDS看看资料分布。
MDS主要的原则是保持“距离”不变,但这里的距离是可以变换的,我们可以使用最简单的euclidean distance,也可以使用第一天提到的DTW,要注意的是如果使用euclidean distance,跑出的分布结果会和PCA相同。另外一个要注意的地方是因为牵涉到距离,所以要执行MDS的资料必须要先标准化(normalization)。
Python
来用有名的iris dataset举例:
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.manifold import MDS
from sklearn.preprocessing import MinMaxScaler
data = load_iris()
X = data.data
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
MDS的重要参数有:
- n_components:想要降低成几维度的资料
- dissimilarity(default=’euclidean’):若要放入别的distance metric则输入‘precomputed’,并在fit_transform语法中放入metric
mds = MDS(n_components=2,random_state=0)
X_2d = mds.fit_transform(X_scaled)
colors = ['red','green','blue']
for i in np.unique(data.target):
subset = X_2d[data.target == i]
x = [row[0] for row in subset]
y = [row[1] for row in subset]
plt.scatter(x,y,c=colors[i],label=data.target_names[i])
plt.legend()
plt.show()
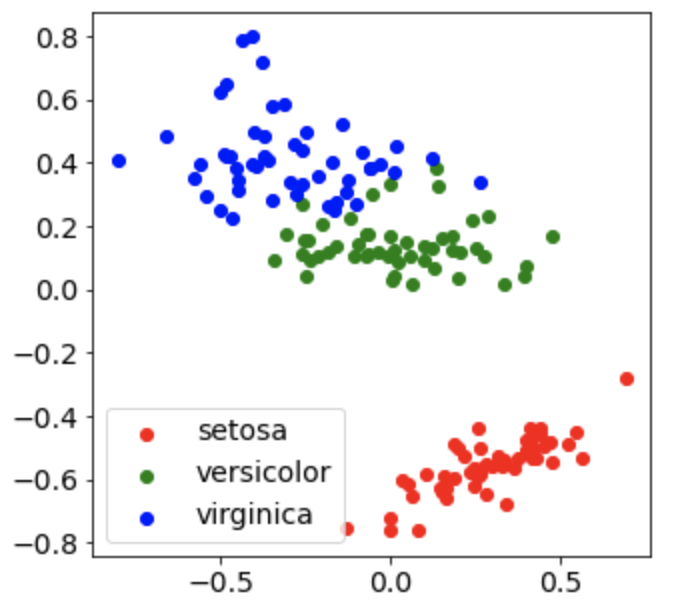
最後要注意的是,上图中的x与y轴能代表每个资料转换後的座标,并没有实质上的解读意义呦!
references:
https://www.youtube.com/watch?v=GEn-_dAyYME
https://towardsdatascience.com/visualize-multidimensional-datasets-with-mds-64d7b4c16eaa
https://scikit-learn.org/stable/modules/generated/sklearn.manifold.MDS.html
Day 7【钱包登入区 - Login Button】Kitten or Ice Cream?
【前言】 先来回顾一下 Day2 Project 分析的使用者流程,今天先来做第一步的 「登入按钮...
[ Day 17 ] React 中的事件处理
结束了 React Hooks 的章节之後,今天要进入到网页互动少不了的事件处理部分了。 在 Re...
【Day12】特殊性营运流程篇-专案
#odoo #开源系统 #数位赋能 #E化自主 当我们提起「专案」一词,我还是比较喜欢美国专案管理学...
谈谈 Log 的定义以及使用 - part1
Spring Boot 内部所有日志记录是使用 Commons Logging 实现,同时默认配置也...
DAY2 - 找寻生活中的问题
好了,开始做side project了,但是要做什麽呢? 相信这是大多数人的问题 做 side pr...