使用MLFlow tracking功能比较training结果
在上一篇我们已经完成MLFlow的安装, 这篇我们就来说明如何在jupyter notebook里整合MLFlow.
这次的范例可以在github下载 fastai_mnist_mlflow.ipynb
这次在notebook加上跟MLFlow 有关的部份, 说明如下:
-
安装mlflow
!pip install mlflow -
把MLflow import进来
# Import mlflow import mlflow -
设定MLFlow的主机位置
使用set_tracking_uri函式可以设定MLFlow server的主机位置, 因此可以跳脱个人单机使用, 当多人使用时也可以将不同训练环境的结果记录在同一台主机上, 这样就容易比较不同人、时、地的训练结果.
set_tracking_uri函式可以支援四种型式, 可以参考官网说明:- Local file path
- Database connection
- HTTP server
- Databricks workspace
我们的例子之中, 使用
HTTP server, 输入前一篇所安装好的MLFlow server的IP与portmlflow.set_tracking_uri("http://172.23.180.10:30534") -
设定experiment的名称
如果这个名称不存在则会以这个名称建立一个新的experimentmlflow.set_experiment("fastai_mnist") -
记录训练资料
原本我们执行训练时是执行微调learn.fine_tune, 为了要将每次设定的parameter、metrics记录起来, 我们加入下列内容.设定执行微调的 epoch2 数值
epochs = 1设定staru run的名称 "jack-run-1". 当团队中多人同时针对Dataset进行模型的调校, 则需要请团队成员为每次的设定给个名字, 这个名字可以让团队其他人了解是由谁执行的training
with mlflow.start_run(run_name="jack-run-1"):再把epochs以参数的方式记录起来
mlflow.log_param('epochs', epochs)然後我们再执行一次微调
learn.fine_turn(epochs)执行完微调之後, 我们需要取得metric的结果, 这样我们才能知道每次微调的效果如何. 因为我们所设定的metric是accuracy, 我们以下列方式取得accuracy的数值
先从learn物件取出metrics的物件avgMetric, 而avgMetric是一个清单, 因为我们设定metric只有一项为accruacy, 所以使用 avgMetric[0]取出装有accruary值的物件(accObject), 再由accObject.value.item()取出accuracy的值avgMetric = learn.recorder.metrics print(avgMetric) # a list accOjbect = avgMetric[0] print(accObject) # an object print(accObject.value) # Tensor print(accObject.value.item()) # float然後我们再把accuracy记录在metric中
mlflow.log_metric('accuracy', accObject.value.item()) -
MLFlow UI确认第一次的记录结果
这时我们再去MLFlow UI上看一下, 这时可以看到我们已经将parameter与metric记录起来.
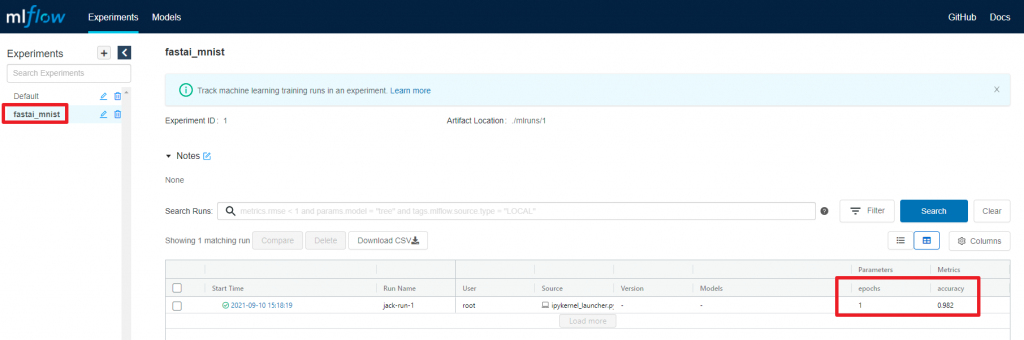
-
调整参数後再执行一次
再来, 我们把epochs改为5, 像这样.
ps:因为将epoch由1调为5, 预期accuracy数值会提高.epochs = 5那後再把 run name改为
jack-run-2再执行一次notebook的内容. 在MLFlow UI可以看到第二次的执行结果.
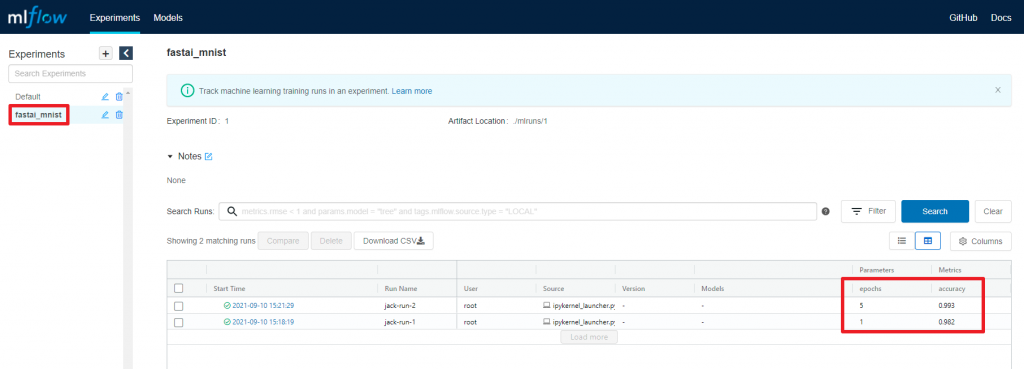
在预期中, accuracy由0.982上升一点点到0.993
这样, 我们就完成使用MLflow将每次执行training的paramter与metric记录起来,这样我们可以很容易的看出每次改了什麽与结果如何, 就可以找出最适合的组合.
这个例子用很简单的方式(只调epoch次数)说明如何使用MLFlow做记录, 在真实的状况下, 资料科学家需要调的参数会更多, 但基本的操作方式则大同小异.
参考资料
https://www.mlflow.org/docs/latest/tracking.html
MS Azure ML02
接着,请回到[Microsoft Azure]的Home,在[Recent resources]处&...
Parser Generator (二)
上一篇我们讲解怎麽产生目标 parser 的 parse 方法,这篇来讲解 generator 的内...
[Day10] Cloud Spanner
Spanner ?,跟 Cloud SQL 一样,是一种 RDBMS (Relational Dat...
[NestJS 带你飞!] DAY10 - Pipe (下)
前一篇有提到如果遇到物件格式的资料要如何做验证这个问题,事实上这个解法只需要使用 DTO、Valid...
Day30 系列文总结与未来
总结与未来 终於走到了今天这一步,过去介绍了很多关於 Apache NiFi 的组成与应用,我们从 ...