【Day 05】- Python 字串操作(正规表达式 regexes 、原生基本操作)
前情提要
前一篇文章带大家看了 Python 中的条件判断以及回圈等语法,大家要先把这些基本语法用熟,之後的几天会比较顺利欧。
开始之前
Day 2 有带给大家基本的一些资料型态,其中的字串(str)这个型态在爬虫中会常常被处理到,因此今天我们会带读者们深入研究一下字串的用法。
原生 Python 字串操作
大家可能会发现字串(str)有些操作跟串列(list)很相似,大家可以试试看对字串做 len(str) (回传字串长度)这个操作,看会发生什麽事。
撷取
语法 :str[开始位置:结束位置:间隔位置]
开始位置 : 若为正数代表从字串最左边开始,负数则从最右边往回数。空值代表从 0 开始。
结束位置 : 撷取的字串的结束位置。空值代表撷取到字串尾部。
间隔位置 : 每撷一个字後,离下个字要相差几格。空值代表每次差 1 格。
以下为范例,大家能先把 Output 遮起来看自己有没有答对欧。
text = 'abcdefghijk'
#撷取 index 为 4 到结尾
print(text[4:]) #Output: efghijk
#撷取 index 倒数 5 到结尾
print(text[-5:]) #Output: ghijk
#撷取 index 为 1 到 index 为 2
print(text[1:3]) #Output: bc
#撷取 index 为 0 到 index 为 2
print(text[:3]) #Output: abc
#撷取 index 为 1 到结尾,每次差 2 格
print(text[1::2]) #Output: bdfhj
#撷取 index 为 0 到结尾,每次差 -1 格
print(text[::-1]) #此为常用将字串反转的操作 Output: kjihgfedcba
取代
语法 :str.replace(取代前字串, 取代後字串)
任何符合取代前字串的字串将被取代为取代後的字串
text = 'user:OwOb|passwd:1234lol'
#将 | 取代为 空白
print(text.replace('|', ' '))
'''
user:OwOb passwd:1234lol
'''
#将 | 取代为 \n(\n 为 换行字元,没听过的读者能去 google 「跳脱字元 \n」)
print(text.replace('|', '\n'))
'''
user:OwOb
passwd:1234lol
'''
#将 : 取代为 空白,并将结果字串的 | 取代为 \n
print(text.replace('|', '\n').replace(':', ' '))
'''
user OwOb
passwd 1234lol
'''
寻找
语法 :str.replace(想寻找的字串[, 开始位置, 结束位置])
回传在原字串中第一个符合想寻找的字串的位置(想寻找的字串最开始出现的 index)
若开始位置与结束位置为空则搜寻全部字串
text = '<a href="https://vimsky.com/zh-tw/examples/detail/python-module-email.MIMEMultipart.html">OwO</a>'
#寻找 href 第一次出现的位置
print(text.find('href')) #Output: 3
#寻找 > 第一次出现的位置
print(text.find('>')) #Output: 89
分割
语法 :str.split(分隔字串[, 分隔次数])
将字串以分隔字串分隔开来,将会回传一个串列(list)。
分隔次数若为空值,代表将所有分隔字串分隔。
text1 = 'A|B|C|D|E|F|G'
text2 = 'user:lol'
# 将 text1 以 | 分隔,之後将其回传的串列用 for 回圈遍历逐一将字串印出
processedText1s = text1.split('|')
for processedText1 in processedText1s:
print(processedText1)
'''
A
B
C
D
E
F
G
'''
# 将 text2 以 : 分开,之後将倒数第一个字串印出
print(text2.split(':')[-1])
'''
lol
'''
正规表达式
正规表达式是一个拿来匹配字串极好用的工具,他有独立的语法,并且能透过自己的特定语句规则(Pattern),达到搜寻、萃取、替代满足该条件的字串。
下面做一个找出电话号码的范例
import re
text = 'My phone number is 0987-878887 not 0912-345678. wait a second, is 0987-654321, wait wait wait is 0901-000000 I wrong wrong wrong Orz.'
#写好我们的 Pattern 应该不难理解 \d 代表的是数字
Pattern = r'\d\d\d\d-\d\d\d\d\d\d'
#编译我们的 Pattern 使其变为一个 Regex 物件
phoneRegex = re.compile(Pattern)
#透过我们编译的物件在欲寻找的字串中比对并回传符合 Pattern 的所有字串的串列(list)
phones = phoneRegex.findall(text)
print(type(phones))# Output: <class 'list'>
for phone in phones:
print(phone)
'''
0987-878887
0912-345678
0987-654321
0901-000000
'''
在 Python 中内建了 regex expression 的套件 re ,在 python 中 import re 即可引入该套件。
正规表达式包含了两个部分,撰写正规语法跟正规处理函式,分别对应上面例子的 Pattern 跟 findall。下面将这两个分开介绍。
正规语法
这边介绍几个万用字元,有兴趣了解更多或已经很熟的读者能去补充资料那边拿到更多正规语法,读者能根据自己的需求来组出不同的 Pattern。
这边推荐一个网站 https://regex101.com/ 这个网站能够及时将你输入的字串比对你的正规语法,十分方便。
| 万用字元 | 规则 | 例子 |
|---|---|---|
| . | 比对任意字元 | 'OwO' >>> 'O.O' → '**OwO**' |
| ^ | 比对开头位置 | 'Name123Name' >>> '^Name' → '**Name**123Name' |
| * | 比对前一个字元 0 到多次 | 'OTTTTTO' >>> 'OT*O' -> '**OTTTTTO**' |
| ? | 比对前一个字元 0 到 1 次 | 'OTTTTTO' >>> 'OT?O' -> 'OTTTTT**OTO**' |
| + | 比对前一个字元 1 到多次 | 'OTTOOTTTOTO' >>> 'OT?O' -> 'OTT**OO**TTT**OTO**' |
| {m} | 比对前一个字元严格 m 次 | 'OOTTTOOTTOOTTTTO' >>> 'OT{3}O' -> 'O**OTTTO**OTTOOTTTTO*' |
| {m,n} | 比对前一个字元严格 m 到 n 次 | 'TATTAAATTAAT' >>> 'TA{3,4}T' -> 'TAT**TAAAAT**TAAT*' |
| {m,n}? | 比对前一个字元严格 m 到 n 次,尽量取少 | 'OTTTT' >>> 'OT{2,3}?' -> '**OTT**TT*' |
| () | 小括号括住的地方设定为一个分组 | 'OOOwOOO' >>> 'O(OwO)O' -> 'OO*OwO*OO'(代表第一分组的匹配) |
| \\ | 正则表达式用的跳脱字元,用於跳脱万用字元 | 'O.OOwO' >>> 'O\\.O' -> '**O.O**OwO' |
| [] | 字元集,能用 [a-b] 表示 a~b 的所有字元集合 | 'OAOOuOOTOOeOOwO' >>> 'O[ATw]O' -> '**OAO**OuO**OTO**OeO**OwO**' |
| | | 逻辑中的 或, a|b 代表比对 a 或 b | 'OAOOuOOTO' >>> 'OAO\|OTO' -> '**OAO**OuO**OTO**' |
| \w | 比对字母数字及底线,等同於 [A-z0-9_] | 'user:Vin_30;' >>> '\w\w\w\w\w\w' -> 'user:**Vin_30**;' |
| \W | 比对除了字母数字及底线外的字元,等同於 [^A-z0-9_] | 'OwOO%OOTO' >>> 'O\WO' -> 'OwO**O%O**OTO' |
| \d | 比对数字,等同於 [0-9] | 'phone:0912-345678' >>> '\d\d\d\d-\d\d\d\d\d\d' -> 'phone:**0912-345678**' |
| \D | 比对除了数字外的字元,等同於 [^0-9] | 'phone:0912-345678' >>> '\D\D\D\D\D' -> '**phone**:0912-345678' |
正规处理函式
- search
语法 :re.search(pattern, string, flags=0)
匹配全部字串,匹配後即回传(代表只会匹配一组)。若有匹配,回传一个匹配实例,否则回传 None。
对於回传的匹配实例有 group(num=0) groups()
group(num=0) : 回传匹配实例的 num 分组,预设回传第 0 组
groups : 回传所有分组
import re
text = 'nowtime: Fri Sep 17 10:08:54 2021 nowtime: Fri Sep 19 10:09:54 2021'
a = re.search(r': ([A-z]{3} [A-z]{3} \d{2}) (\d+:\d+:\d+ \d+)', text)
#这边要注意 除了匹配 : [A-z]{3} [A-z]{3} \d{2} \d+:\d+:\d+ \d+ 外
#还有在 ([A-z]{3} [A-z]{3} \d{2}) (\d+:\d+:\d+ \d+) 设定为分组
#让我们在 group 能够选取到我们想要的地方
print('group0:', a.group(0))
print('group1:', a.group(1))
print('group2:', a.group(2))
print('groups:', a.groups())
#另外一个注意的点是他只回传了第一个匹配的
'''
group0: : Fri Sep 17 10:08:54 2021
group1: Fri Sep 17
group2: 10:08:54 2021
groups: ('Fri Sep 17', '10:08:54 2021')
'''
- match
语法 : re.match(pattern, string, flags=0)
只匹配字串的开始位置,而不匹配每行开始。若有匹配,回传一个匹配实例,否则回传 None。
text = 'nowtime1: Fri Sep 17 10:08:54 2021 nowtime2: Fri Sep 19 10:09:54 2021'
a = re.match(r'nowtime[0-9]', text)
print('group0:', a.group())
'''
group0: nowtime1
'''
- findall
语法 :re.findall(pattern, string, flags=0)
回传所有符合的字串,不用使用group() groups() 来选取想要使用的字串。
import re
text = 'nowtime: Fri Sep 17 10:08:54 2021 nowtime: Fri Sep 19 10:09:54 2021'
founds = re.findall(r': ([A-z]{3} [A-z]{3} \d{2} \d+:\d+:\d+ \d+)', text)
for found in founds:
print(found)
'''
Fri Sep 17 10:08:54 2021
Fri Sep 19 10:09:54 2021
'''
- sub
语法 :re.sub(pattern, replace, string, count=0, flags=0)
将符合的字串替换为 replace 。
import re
text = '0912345678'
newText = re.sub(r'^\d{2}', '+886', text)
print(newText)
'''
+88612345678
'''
对想挑战的读者,这边是海豹在 R2S CTF 出的一题 How Regular is This, 要透过想出那些字串会被行/列的 pattern 匹配,完成这个填字游戏。
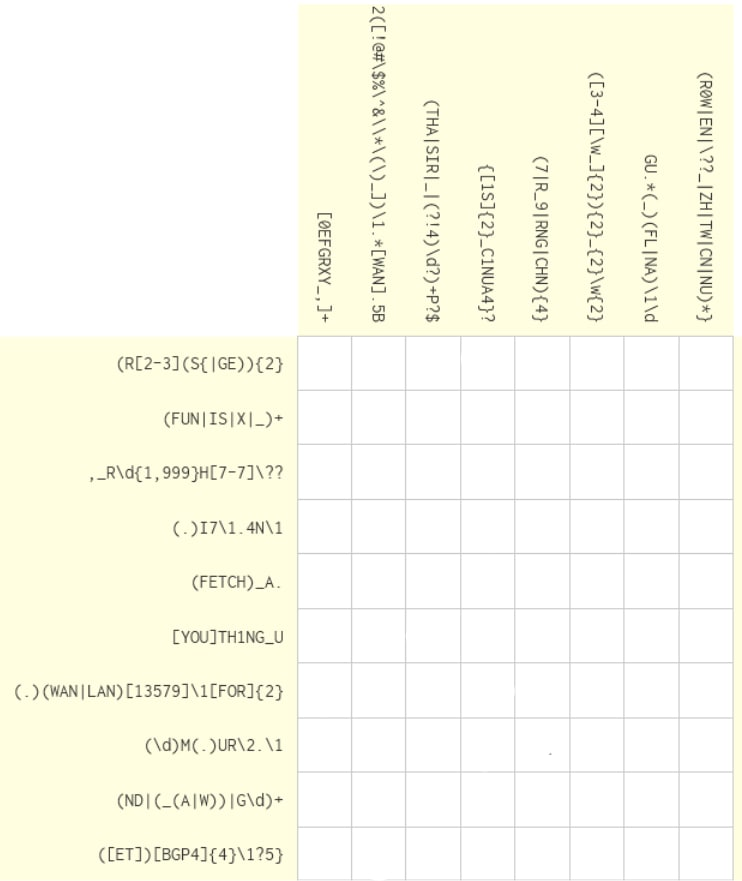
▲题目(下面附答案)

▲答案
ref: seadog007 on R2S CTF
结语
今天跟读者们介绍了 Python 中字串的基本用法及正规表达式的基本应用,熟练正规表达式後,了解一下就会发现它在很多语言皆有出现,能够很方便的将想要提取出来的文字提取出来。
明日内容
明天将会带给网页开发工具的介绍。有不小心按过 F12 或有听别人说用 F12 就能当骇客的读者能持续追踪後续内容欧。
补充资料
正规表达式线上测试 : https://regex101.com/
正规表达法 python regular expression 教学及用法 : http://python-learnnotebook.blogspot.com/2018/10/python-regular-expression.html
Python 速查手册 12.1 正规运算式 re : http://kaiching.org/pydoing/py/python-library-re.html
>>: DAY5 - Side Project 主题:90天原子习惯挑战
新增表单/编辑表单,共用?或分开?
目前我们写好了一个新增的画面 需求 接下来,常见的需求是,人员的新增之後是人员的编辑。 新增用的画面...
多国语系魔术
今天要来介绍多国语系的处理,想要建立一个国际化网站,多国语系可以说是基本需求,那我们就来看如何在 B...
【Day29】谈谈软件工程师 - 8 大战略角色及 7 大能力对应的 26 项指标 (3) 案例分享
30 天 redesign 心目中的 LINE 的章节已经结束罗,有兴趣的话可以点此看看总回顾,现...
Day 24 - 用 canvas 画个时钟
前述 今天来画个时钟~!一样利用 requestAnimationFrame,再判断当前时间,每一秒...
如果我是主力,我会怎样割韭菜
所谓的主力,就是有绝对多的资金,或是大量持有某一档股票,最大的优势就是容易操控股票价格。 今年一堆散...