【5】超参数 Batch size 与 Learning rate 的关系实验
昨天探讨了 Batch size 的问题和前天的 Warm-up 问题後,其实在我心中还是有个好奇的问题,也就是 Batch size 和 Learning rate 之间的关系,这是我之前在浏览某个 Repo 时发现的,该作者的 Learning rate decay 是根据 Batch size 大小来调整,而且和 Warm-up 提到的 Linear Scaling Rule 相反,他的策略是当 Batch size 越大时,整体训练的学习率设置的越低。
其实会有这样的想法感觉也挺正常的,因为当 Batch size 变大时,每次 gradient 的步伐也变大了,某种程度也像是调高了 Learning Rate,所以直觉会把 Learning Rate 也调小与之抗衡?
所以基於好奇,我也在 Colab 上设置几个参数来观察:
实验一:Batch size=128, Learning rate=0.1
SHUFFLE_SIZE=1000
EPOCHS = 50
BATCH_SIZE=128
LR = 0.1
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
loss: 0.0032 - sparse_categorical_accuracy: 1.0000 - val_loss: 2.3630 - val_sparse_categorical_accuracy: 0.4500
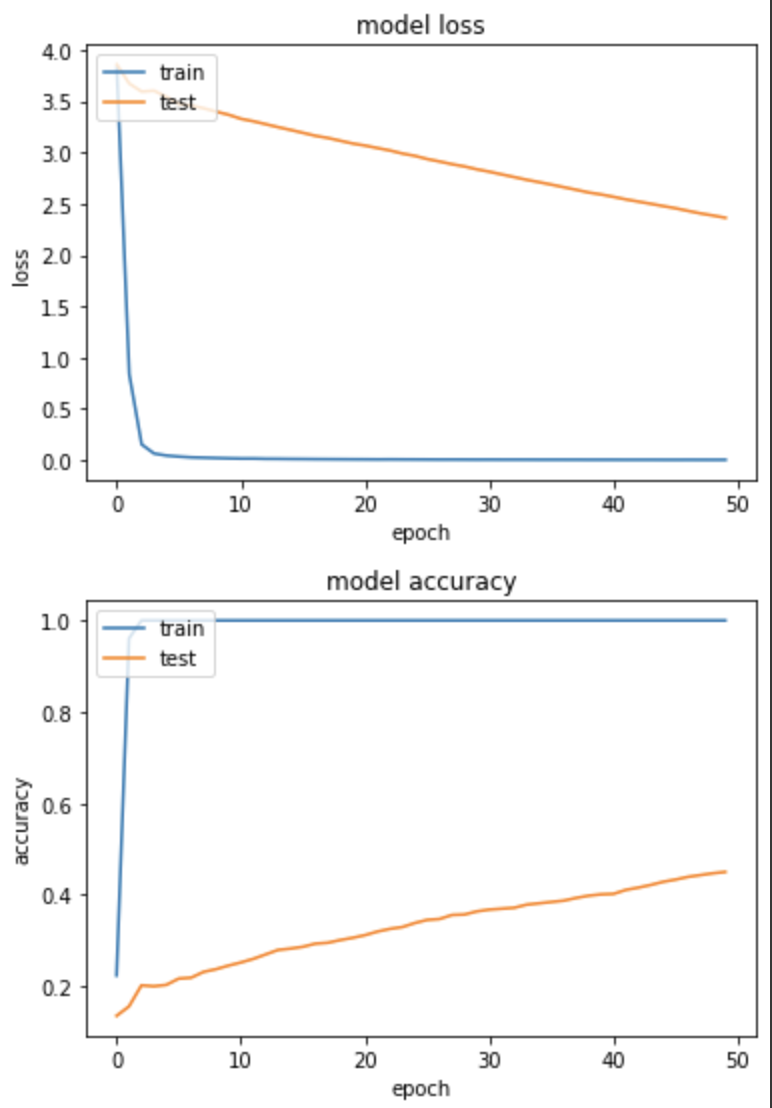
训练集和验证集的 loss 下降很不一致,且得出的 Accuracy 并不大理想,仅有45%。
实验二:Batch size=128, Learning rate=0.001 (以下程序码略过,并竟只有参数有差)
loss: 1.9535 - sparse_categorical_accuracy: 0.8559 - val_loss: 3.7203 - val_sparse_categorical_accuracy: 0.2196
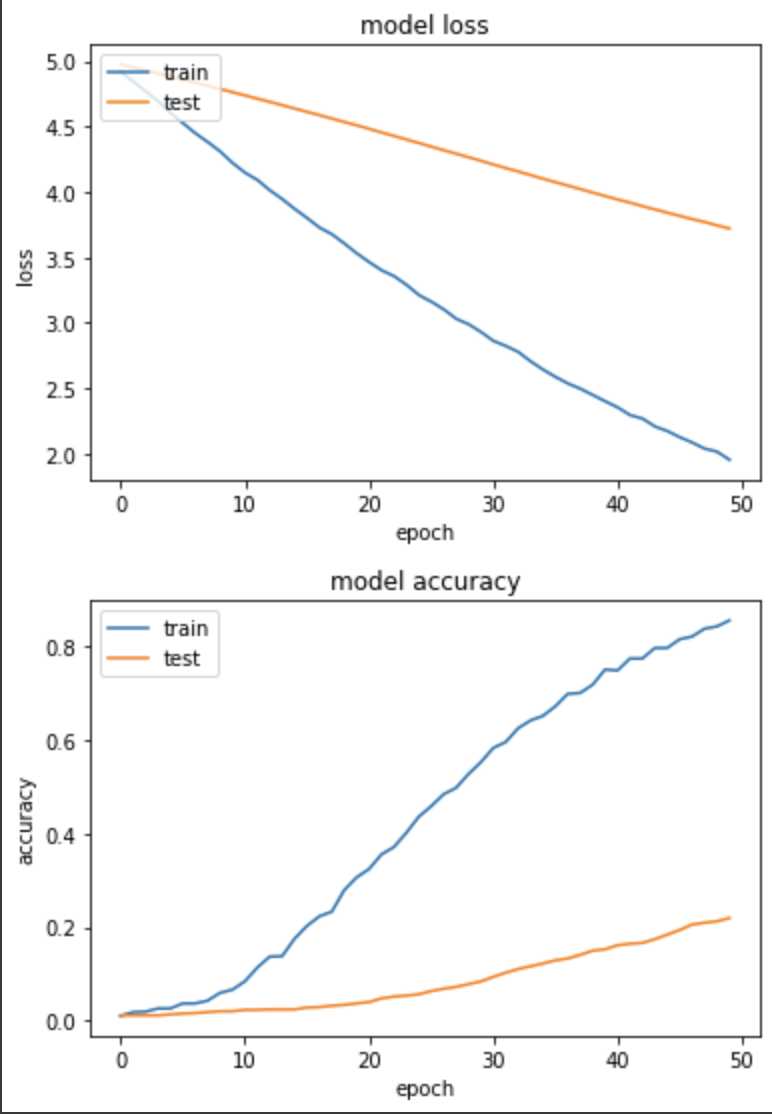
虽训练集和验证集 loss 下降较为一致,但进步速度非常缓慢,Accuracy不及上个实验,可能真的是 Learning rate 太低了!
实验三:Batch size=32, Learning rate=0.1
loss: 8.4681e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.5873 - val_sparse_categorical_accuracy: 0.8382
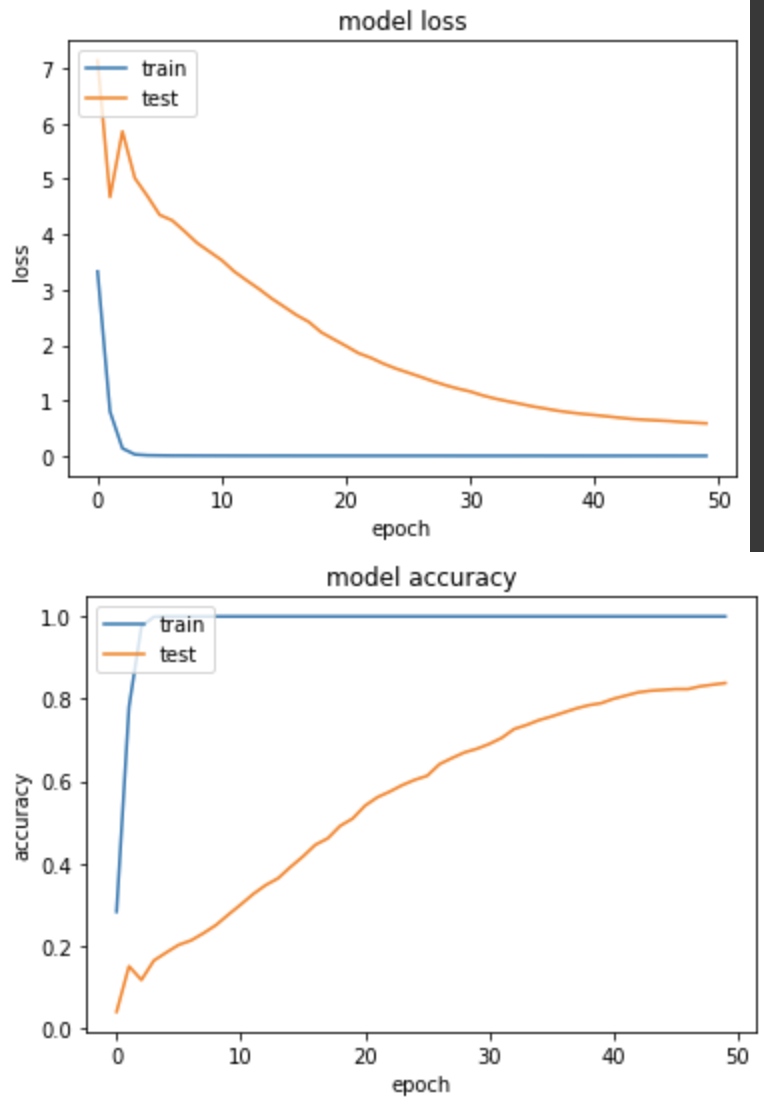
训练集和验证集的 loss 都下降很快,模型表现不错,Accuracy到83.8%
实验四:Batch size=32, Learning rate=0.001
loss: 0.3136 - sparse_categorical_accuracy: 0.9990 - val_loss: 1.7577 - val_sparse_categorical_accuracy: 0.6902
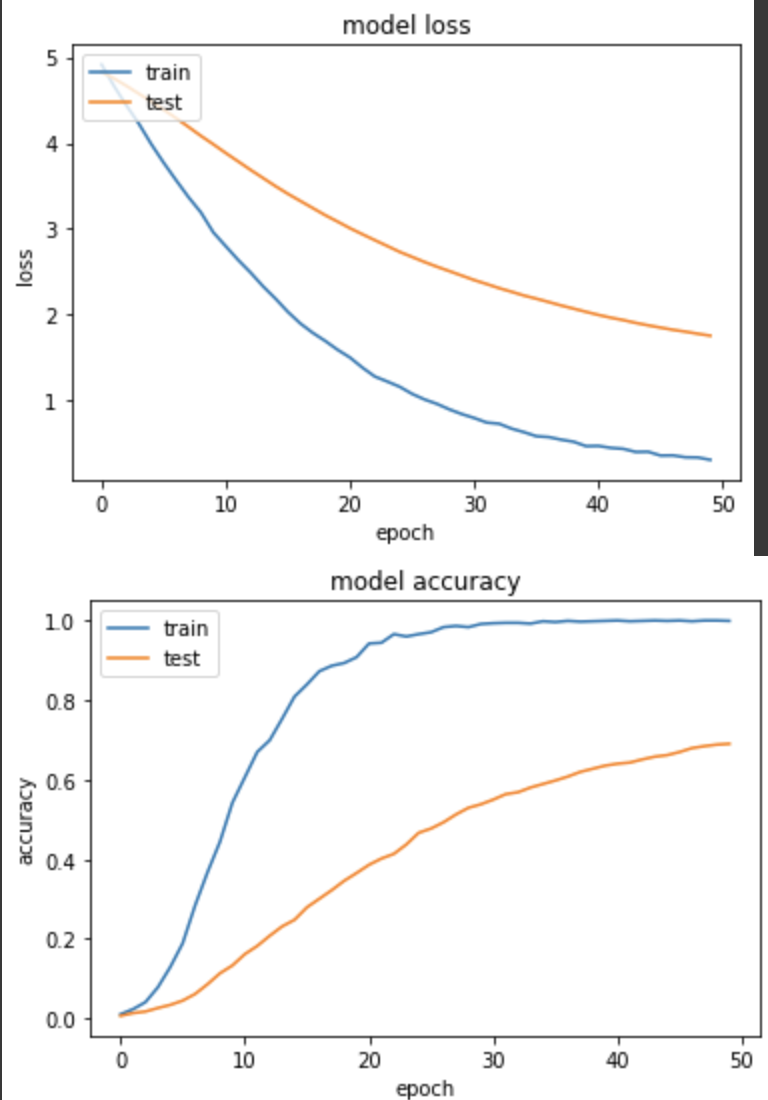
训练集和验证集的 loss 下降的很健康,和实验三相比,准确度上升慢很多,但因为 learning rate 很小,可能需要更多epoch来训练。
实验五:Batch size=64, Learning rate=0.01
loss: 0.0218 - sparse_categorical_accuracy: 1.0000 - val_loss: 1.7184 - val_sparse_categorical_accuracy: 0.6441
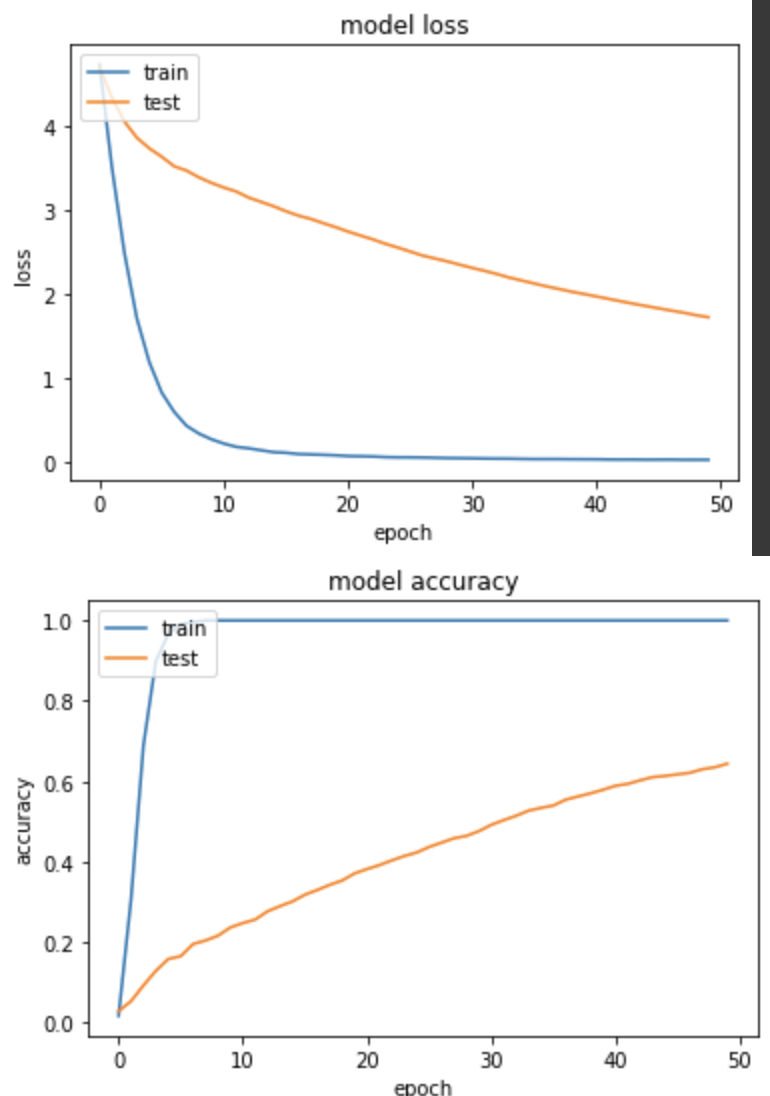
loss 下降的并不是很好,训练集相对验证集还是跑太快,最後 accuracy 得到64.4%
从本次实验来看,挑选一的对的 learning rate 还是对模型学习比较健康,较大的 batch size 用较小的 learning rate 并没有太大进步的效果。
<<: Day14:内建的 suspend 函式,好函式不用吗? (3)
【从实作学习ASP.NET Core】Day07 | 後台 | 复杂的商品模型
前面花了点时间介绍了 MVC,今天终於要进入正题啦! 我会以一个电玩专卖店的购物网站为主题,并且从後...
Swift纯Code之旅 Day11. 「TableView(3) - 实作Delegate & DataSource」
前言 昨天已经将 addAlarmTableViewCell 在 addAlarmTableView...
Day 33 - 实作 S3 驱动 Lambda 函数进行镜像
Day 33 - 实作 S3 驱动 Lambda 函数进行镜像 AWS 有个教学课程,教学课程:使用...
[Day 01] 勇闯新手村的菜鸟 - 用 .Net Core 3.1 玩转永丰API是否搞错了什麽? (目标规划)
人家都转生当勇者了,我才刚转职成菜鸟工程师QQ 如题,从初学C#到成功转职为後端工程师还不到一年的...
【Vue】params vs. query | Vue Router
params - 命名的路由,加上参数让路由建立 url 动态的参数前要加上冒号 ":&q...