[Day 04] 深度学习与神经网路
话说小弟推出孔子和耶稣都讲过「初恋无限美」的「刻骨铭心初恋金银情侣套餐」时,竟被中国厨艺学院105届毕业生唐牛吐槽根本是街边「杂碎面」,还说我煮的面「咖哩鱼蛋没鱼味,咖哩又不入味,失败!猪皮煮得太烂,没咬头,失败!猪红松扑扑,一夹就散,失败!萝卜没挑过都是筋,失败中的失败!最离谱的就是这些大肠,完全没洗乾净,还有块屎,你有没有搅错呀?」,最後还秀了一手,让我重新见识到如何用「心」煮出一碗顶级好吃的杂碎面,真是情何以堪。
现在市面上许多教AI应用的补习班或老师总是为了让学生速成、有感,因此多半只教马上看的到成果的内容和按图施工的步骤,而少教枯燥乏味的原理,导致学生离开老师现成的范例後却无法完成自己应用或搞不懂如何调校的冏境,就像只会用调理包是煮不出一碗内容丰富、刀工精湛且口味有层次的杂碎面。
为了让大家後续自行开发MCU程序码(包括全部自刻或使用Arm Mbed作业系统加上CMSIS函式库)或使用tinyML现成开发平台(如TensorFlow Lite for Microcontroller, Edge Impulse, cAInvas, SensiML等)时都能更加游刃有余。
接下来的章节会依序将MCU、AI及tinyML独立及交集部份逐一分篇说明。大家可能要花个几天了解一下基础知识,以免後续实际操作tinyML时,就像新手开自排车,只知踩油门、刹车和转方向盘就能把车开上路,但搞不懂如何让车子能开的更顺畅,更不容易翻车。
在[Day 02] Fig. 2-1 中已清楚描绘出人工智慧(AI)、机器学习(ML)、神经网路(NN)和深度学习(DL)的层级架构。这里要先了解,tinyML的ML实际上指的不单纯是机器学习或神经网路或深度学习,而是泛指在指定时间内能计算推论出结果的算法,其结果亦包含了耗能,当计算平行度越高或时间越长时就会导致耗能越大,因此更清楚了解模型运作模式就有机会创作出更低耗能、更高效率的Edge AI应用了。
在开始学习应用tinyML之前,我们还是得先了解何谓「神经网路」和「深度学习」,再了解如何「训练」及「推论」模型(或称为网路),才不会後续操作时不知如何下手。话说1950年代,科学家们想让计算机也能像人类一样拥有学习及思考能力,於是仿效了大脑神经元及神经突触相互连结的结构,创造出感知机(Perceptron)。如下图(Fig. 4-1)左方所示,每个神经元可以有多个输入值(Xn),每个输入可以有不同权重值(Weight)(Wn),最後加总所有乘积输出,就成了一个神经元基本单元。
当有很多个神经元时就能组成网路(或称为模型),如Fig. 4-1右侧所示。最简单的人工神经网路(Artificial Neural Network, ANN或简称NN),通常只有三层,输入层(Input Layer)、隐藏层(Hidden Layer)和输出层(Output Layer)。每一层的神经元个数不限,原则上采全连结(Full Connected)方式,就是相邻两层的所有节点必须互连。如图所示,输入层三个、隐藏层三个及输出层两个神经元时,需要的权重值(每条连线)就有(3 x 3) + (3 x 2) = 15组,若以Float数值(4 Byte)来表示,则需要15 x 4 = 60 Byte来储存。当隐藏层的数量增加时,其连结数(权重值)也会瞬大幅提升。
除此之外,通常还会在神经元加上一个偏置量(Bias)及在输出端加上一个可微分的非线性函数,称为「激励函数(Activation Function)」,经过转换後通常会使输出值限缩在0 ~ 1(如Sigmoid)或-1 ~ +1(如Hyperbolic Tangent, tanh)之间,相当於变相将下一级输入的值进行正规化。关於模型训练问题就留待後面章节再进行说明。
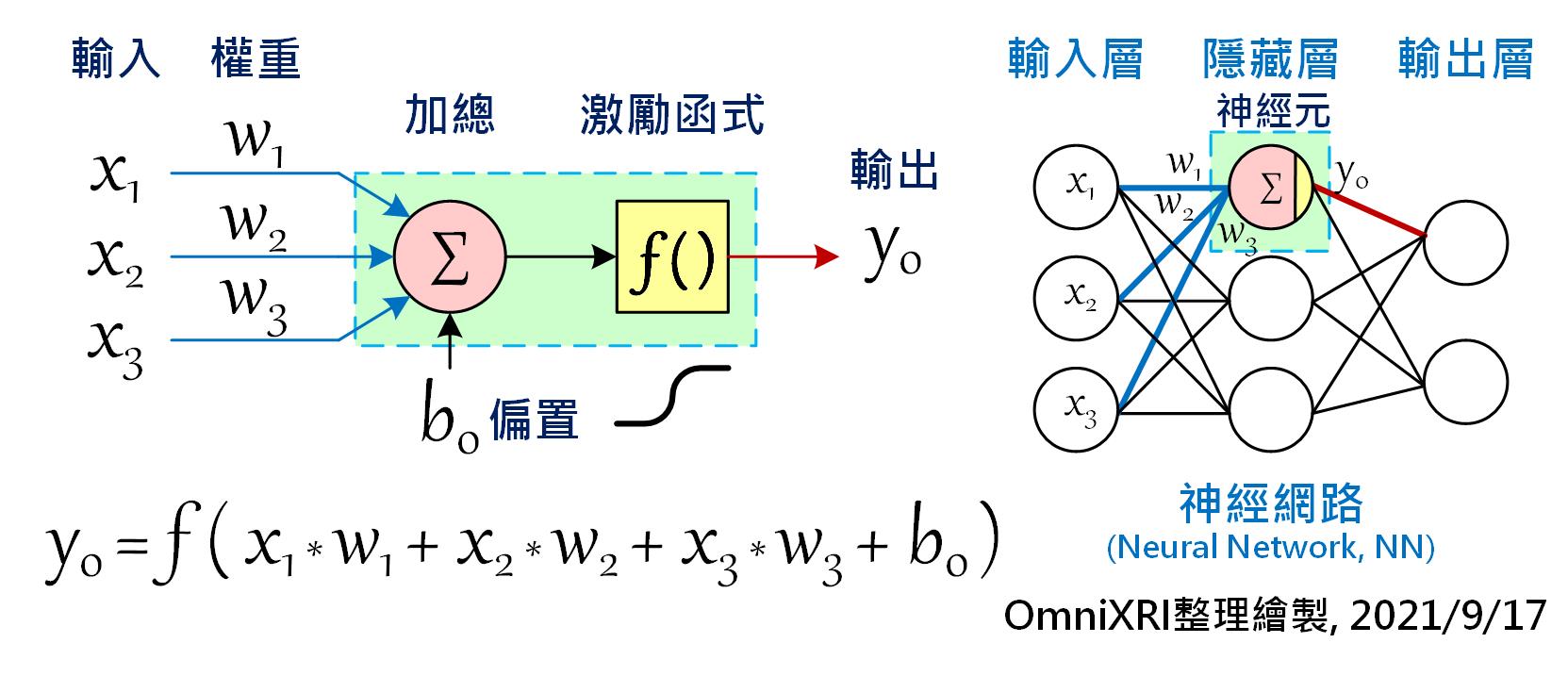
Fig. 4-1 神经元与神经网路。(OmniXRI整理绘制, 2021/9/17)
以下为C语言格式参考示意程序,当然这段程序很容移植到Arm Cortex-M的MCU上。透过程序码也可初步了解到,一个有三个输入值,三个权重值、一个偏置量及一个输出值的神经元至少需要占用4个Float共16 Byte的程序码区,和5个Float共20 Byte的随机记忆体(SRAM)来供计算时使用。因为通常训练好的权重值和偏置量是不会变动的,放到程序码区即可,而输入和最後的输出值会一直变动所以要放到SRAM中。而除了输入值、权重值及偏置量外,程序码及SRAM最後会占用多少则和程序码写法及编译器设定有关,这里就暂不分析,待後续完整范例介绍时再行说明。
// 以常数值方式宣告已训练完成的权重值及偏置量
const float w[3] = {7.3, 0.6, 2.6}; // 权重值
const float b0 = 2.1; // 偏置量
// Sigmoid激励函式 (输出 0.0 ~ 1.0)
sigmoid(float val)
{
return(1 / (1 + exp(val)));
}
// 主程序,计算基本神经元输出
main()
{
float x[3] = {1,2,3}; // 输入值
float y0 = 0.0; // 输出值
float sum = 0.0; // 加总值
// 加总所有输入乘权重值
for(int n=0, n<3; n++){
sum += (x[n] * w[n]);
}
sum += b0; // 加上偏置量
y0 = sigmoid(sum); // 以sigmoid激励函式作为输出转换
}
ps. 为让文章更活泼传达硬梆梆的技术内容,所以引用了经典电影「食神」的桥段,希望小弟戏剧性的二创不会引起电影公司的不悦,在此对星爷及电影公司致上崇高的敬意,敬请见谅。
>>: [Day 04] 眼前的黑不是黑,你说的白是什麽白?(直方图均衡化)
C语言工具使用,GDB个人学习笔记
gdb 简介 除错器(debugger),可以在一个精准受控的环境下执行另一个程序。例如: 单步执行...
D3JsDay05Bar拉BarBarBar,作伙来画吧—画个bar chart长条图
用D3绘制长条图 我们现在可以尝试着用已经学到的SVG来画长条图,只不过是透过D3Js的操作来新增S...
学习Vim、VSCodeVim的历程&写书探索的一些经历
学习Vim、VSCodeVim的历程&写书探索的一些经历 [系列文目录] 相信不少人最早接触Vim,...
Day21 - 轻前端 Vue - 动态 新增/删除 Collection 项目(四)
Case01 与 Day20 重点差异的部份: Controller 内 Action: [Http...
Day 16 中场休息,来做点酷东西
好的,Max 的课程进行到这边,是时候来休息一下,整合前面所学的东西了。要来做的是一个可以让使用者新...