【Day 3】分散式系统模型、容错、高可用
上一章我们了解了分散式系统是什麽、为什麽要让系统分散,
也大概知道分散式系统会遇到节点死掉、网路断掉的问题。
接着将更加深入探讨,
2.1、2.2 分别介绍两个思考实验,
2.3 建立系统模型,也就是把各种情况分类,
以便未来在这些假设基础上去设计演算法。
2.4 则谈谈 容错(fault tolerance)与高可用(high availability)的衡量标准。
2.1 The two generals problem
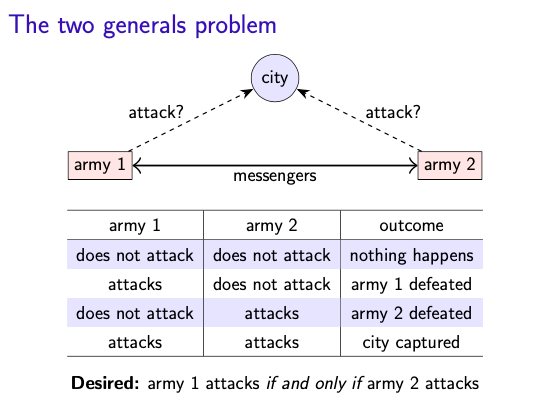
arm1 与 army2 需要同时出动,才能把城市攻打下来。
他们可以透过信使互相确认要出发的日期,但信使可能会被抓走。
- a model of network
- 目标:同时出发攻打城市
- 困难:信使会被抓
No common knowdlege
两位将军永远不能确定另一位会在同一天出动!
试想:
- 将军1 告诉 将军2 出发日期,还没收到将军2 回信
此时将军1 不知道将军2 是没收到讯息,还是返回的信使被抓了,因此不能轻举妄动。 - 当将军1 收到将军2 回信,这样将军1 照时出发是一定安全的。
因为将军2 言出必行! - 将军2 的状况落回 step 1
将军2 并不知道将军 1 是否收到这个回信的回信?如果没收到,将军1 为了不全军覆没,可能会不出兵。
这样就会形成一个无限的 sequence,每次都把全军覆没的风险抛给另一个将军,永远不能确定另一组军队会在同一天出动;就像 distributed system 中的 nodes 没办法确定其他 node 的状态。
顺带一提,这就是 [[TCP 3-way handshakes]] 的情形,基本上只要双方都收到了一次回信,那只要相信对方会出兵,就没问题了。
2.2 The Byzantine generals problem
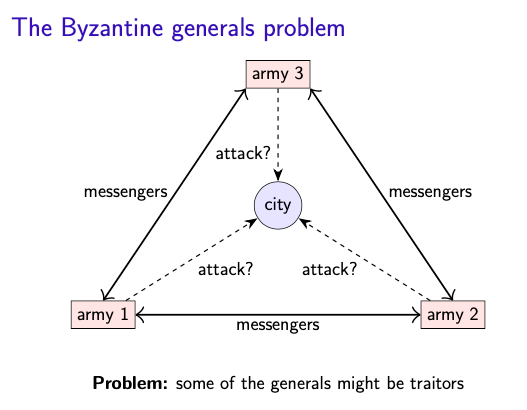
同样是要同时出动、以信使确认出发日期,
这次假设信使一定会送达,但将军之中有叛徒!
- a model of node behavior
- 目标:同时出发攻打城市
- 困难:现在保证信使必达,但将军中有叛徒
可能 scenario
- 将军3 发现将军 1 和 2 说得不一样,但不知道谁说谎,到底要进攻还是撤退?
Theorem 和其他解法?
- Theorem: 3f + 1 个将军可忍受 f 个将军是 malicious
- digital cert 可让 general 2 向 g3 证明当初收到的讯息(g1 签名)来证明 g2 没说谎。
2.3 System model
虽然 2.1 和 2.2 把网路和节点错误分开讨论,但现实中很常两者同时出错!
如果要设计演算法,就要对整个系统有一些假设,这里从 3 个面向来探讨:network, node behavior, timing。
1. network behavior
- reliable (perfect) link
讯息送出一定到达,顺序不计较。 - fair loss link
讯息可能会遗失、重复、顺序乱掉。 - arbitrary link
封包在网路上,每个经过的 node 都可以用 arbitrary 种方式处理(窜改、丢掉、或好好送)
link 可以透过网路协定而「升级」
- arbitrary -> fair loss: TLS
- fair loss -> reliable: retry + dedup
这样好像只要能够一直 retry,讯息总会送达。
但现实中,节点可能会 crash,然後某个讯息就永远的消失。
2. node behavior
- crash-stop
硬体错误之类 - crash-recovery
- byzantine
a node is faulty if deviates from the algorithm.
可能是 crash 了,也可能被骇做出其他恶意行为。
在 byzantine 下,如果所有的 node 都跑同样的程序,而这些程序有同样的 bug,那这个系统是无法 tolerate 的(根据理论,叛徒要少於 1/3)。
node behavior 不像 network 可以透过 protocol 的保证来做模型之间的转换。
3. timing
- synchronous
- partially synchronous
- asynchronous
用 synchronous model 设计演算法会简单,但如果有一点点的差错(超过预设的 bounded latency / execution speed),就会出非常大的问题。
用 asynchronous model 设计的演算法会十分 robust,但有些问题在此模型下无法被解决。
paritially synchronous 是个 compromise。大部分状况都是 synchronous,只有当一些 timing guarantines are off 时,则切换成 async。
无法达成 synchrony 的原因
Networks
通常 latency 是可被预测的,但有时会增加:
- message loss
- 网路很挤,在排队
- network/route reconfiguration
Nodes
通常 node execution speed 是可被预测的,但也有暂停的时候:
- OS scheduling
- stop-the-world garbage collection
- page faults, swap, thrashing
node execution speed 是可被预测的?
因为 instruction 要几个 cpu clock cycle 都是可以知道的,clock speed 也不会差太多 `[note p19]`
所以实际上,使用 synchronous model 来设计演算法,很不可行。
System models summary
If your assumptions are wrong, all bets are off!
2.4 Fault tolerance and high availability
Fault tolerance
- Failure:整个系统烂掉
- Fault:一部份出错(节点或网路)
因此会希望系统能够容错(fault tolerance),也就是在有部分烂掉的状况,还能维持基本系统运作。 - Single point of failure(SPOF):一个 fault 造成整个系统 fail。这是要尽量避免的状况。
High availability
- 讨论可用性时,不会说这个系统可不可用,而是要依据「可用的比率」来判定。
- availability == uptime == fraction of time that a service is functioning correctly
“Two nines” = 99% up = down 3.7 days/year
“Three nines” = 99.9% up = down 8.8 hours/year
“Four nines” = 99.99% up = down 53 minutes/year
“Five nines” = 99.999% up = down 5.3 minutes/year
- Service level objective (SLO)
例如 "99.9% of requests in a day get a response in 200 ms" - Service level agreement (SLA)
标明 SLO 的合约,公司若没达成可能要赔钱。
<<: [Day03 - 规划与设计] 建立 Wireframe 让你开发不迷路
>>: Re: 新手让网页 act 起来: Day03 - 再次了解React.createElement()
Day14 用python写UI-聊聊Scale
今天迈入第14天了,耶~~~今天的内容我也是很喜欢,尤其是自己调整背景颜色的实作,真的觉得非常有趣~...
DAY29:开启API服务(完赛)
部署及开启API服务-flask 导入套件 import base64 import datetim...
[Day12] 以神经网络进行时间序列预测 — LSTM
本篇详细介绍 LSTM 及如何以 LSTM 建模预测时间序列。 本日大纲 LSTM 介绍 LSTM ...
安装imutils与影像简单处理
OpenCV安装之後 还需要imutils 这个主要是要用来进行影像处理 像是平移, 旋转, 缩放,...
DAY 15 - 哥布林 (2)
大家好~ 我是五岁~~ 今天让我们来把哥布林完成吧~~!!! 目标是把昨天的哥布林上色卡通化~~ 第...