Day6:最邻近点规则(k-Nearest Neighbor,KNN
最邻近点规则(以下简称为KNN,因为每个人对此的中文称呼不一样)是在一个地方上有很多个点,将所有点都分类好,而产生不同的区域。若之後有新的点加入,则计算该未知点至其他的所有已知点的距离,得知该点较为偏向哪种区域。
举例来说,有一个二维座标,上面6个样本,每个样本分布在不同的游戏种类,目前就两个种类分别是动作类以及爱情类,x轴象徵格斗,y轴象徵交往,分数越高表示其在游戏中比例越重。其比重以及分布如下。
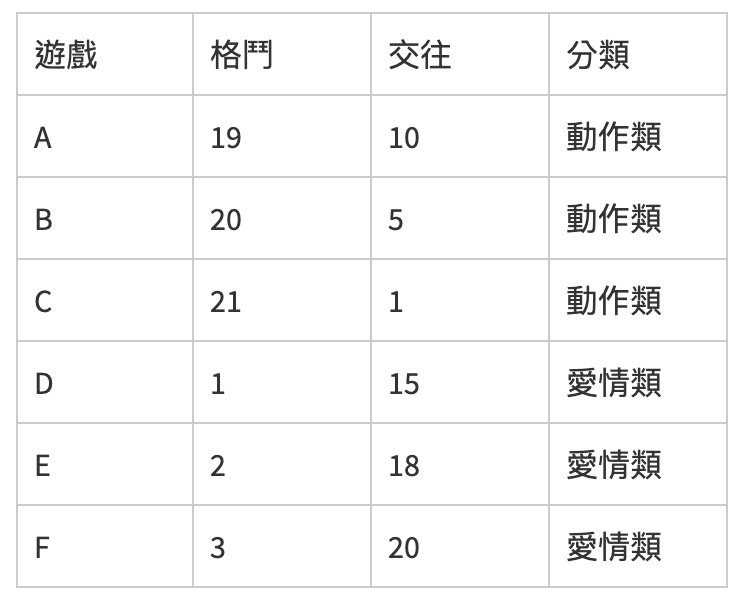
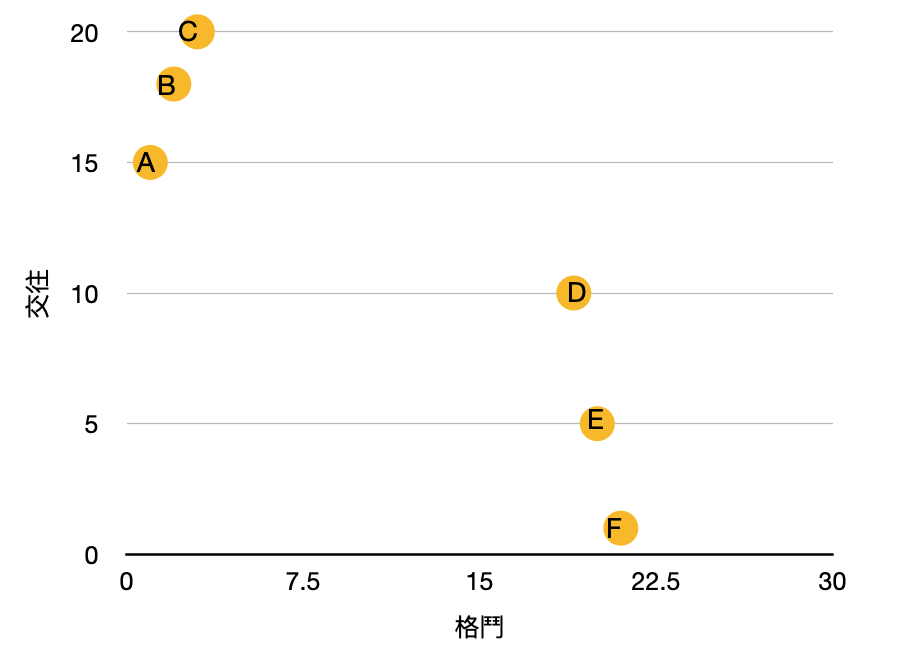
如今有个样本G加入,其格斗15,交往4,计算它与A、B、C、D、E、F之间的距离分别为:3、4、5、14、13、12,若取前四个接近的样本,则有三个为动作类,一个是爱情累,因此判断G距离动作类较为接近,把 G归类在动作类游戏。
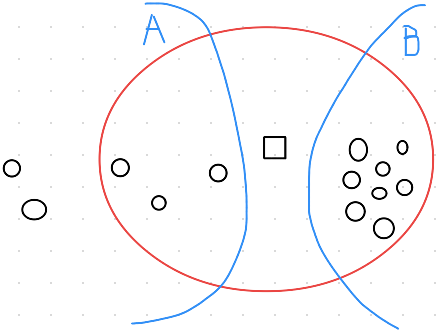
这方法用在归类上很方便,但是如果其中一个种类的样本数很多,可能在一定距离以内,该种类样本数较多,因此就被归类在较多的样本数中了,但并非有最接近的样本,示意图如下:中间正方形是未知的样本,可以看到红圈是距离下AB有的样本数,显然A有更接近正方形,可是其样本数反而B比较多,因此未知的样本就会被归类在B区。
用这方法可以很轻松的机器学习,但如果当样本数多、区域多的时候,可能分类的效果就没那麽好了。
<<: [铁人赛 Day01] 文章架构、预计内容,以及适用范围
Day 6 网路宝石:AWS VPC 架构 Routes & Security (下)
NACL vs SG 的安全设定介绍 当请求想进出在 Private Subnet 内的 EC2 ...
人人有矿挖
故事简述如下 国外小伙 Abada 致力於挖矿普及,到星爸爸喝咖啡、溜自制挖矿平台、顺便再接别人家的...
Day25|【Git】git stash 暂存档案
可能会遇到使用 git stash 指令情境: 假想今天可能在公司进行手中任务时,突然接收到老板或是...
Day 22 来写一个简单e2e测试
今天我们来写一个简单的form来当作测试吧,首先我们刻出一个简单的画面 const App: FC ...
2021年破框计画,一起犇向更好的自己
假期过後,我们如何能比2020年的自己,过得更踏实自信? 最近,在樊登读书APP上听到一本书 觉得非...