【2】学习率大小的影响与学习率衰减(Learning rate decay)
大家应该听到烂了,学习率(Learning rate)指的是模型每做完一次 back propagation 後产生的 gradient 再乘上该值来对权重更新,而学习率越大,代表模型权重被更新的变化量也会跟着变大,而这个学习率该设定多少也是个麻烦的超参数,因此也有其他学者从其他面向如不同的优化器 (Optimizers) 来着手研究。但是今天我们比较单纯,我们都使用 SGD 作为优化器,但用不同的学习率来观察训练的结果。
这次我们使用我自己修改较为精简版的 alexnet 头开始训练,但因为怕 oxford_flowers102 过多的分类,导致模型可能需要非常多个 epochs 来跑,所以改用 tfds 提供的 cifar10 当参考,此资料集只有10个分类,训练和测试资料集分别是50000和10000张。

from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPooling2D, Flatten, Dense
def alexnet_modify():
model = Sequential()
model.add(Conv2D(32, (11, 11), padding='valid', input_shape=(227,227,3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(64, (7, 7), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(96, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Flatten())
model.add(Dense(128))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(64))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(NUM_OF_CLASS))
return model
而原先 alexnet 的 input size 是227x227,但 cifar10 这个资料集的解析度都是32x32,所以要做 resize 的动作。
第一个实验,我们将学习率固定为0.1来训练15个 epochs。
LR = 0.1
model = alexnet_modify()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
loss: 0.3053 - sparse_categorical_accuracy: 0.8906 - val_loss: 0.8681 - val_sparse_categorical_accuracy: 0.7557
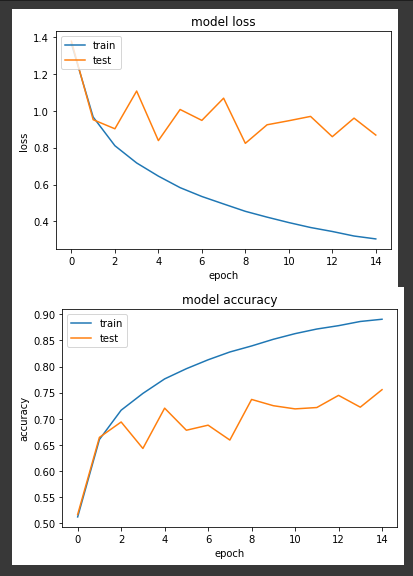
我们可以看到准确度的呈现为震荡向上
第二个实验将学习率缩小固定为0.001,一样15个epochs。
LR = 0.001
model = alexnet_modify()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
loss: 0.8821 - sparse_categorical_accuracy: 0.6962 - val_loss: 0.9843 - val_sparse_categorical_accuracy: 0.6574
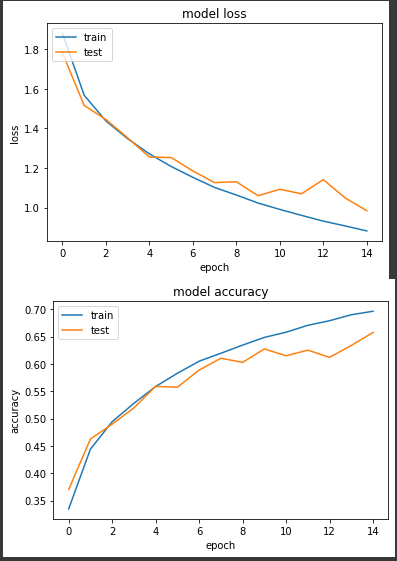
得到的准确度有比较平稳的上升,但同样的 epoch 最後准确度却没有实验一来得高。
第三个实验,我们来实验学习率衰减的做法,简单来说,当模型一开始还是混乱状态时,较高的学习率有助於模型快速收敛,但是到了後期过高的学习率会导致模型不对的在各个局部最佳解中跳耀,而很难继续深入学习,所以我们使用 learning rate decay 这个策略来让学习率随着 epoch 数量增加来降低。
LR = 0.1
model = alexnet_modify()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
def scheduler(epoch):
step = EPOCHS //3
power = (epoch//step)+1
new_lr = LR**(power)
return new_lr
callback = tf.keras.callbacks.LearningRateScheduler(scheduler, verbose=1)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
callbacks=[callback],
verbose=True)
我们降低的原则分成三个部分,前5个 epochs 我们学习率为0.1,中间5个 epochs 为0.01,最後5个 epochs 学习率降至0.001来实验。
loss: 0.3802 - sparse_categorical_accuracy: 0.8687 - val_loss: 0.6588 - val_sparse_categorical_accuracy: 0.7798
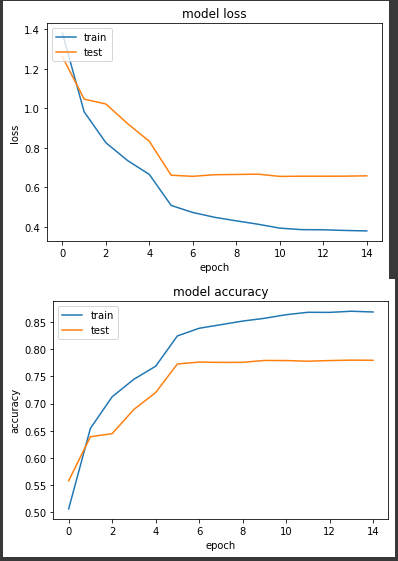
前期准确度稳定上升,但在第6个 epoch 进步趋缓,最终准确度来到77.9%
以上实验结论来看,使用 learning rate decay 可以让模型的训练稳定一些。
Dungeon Mizarka 024
更多的设计参考 今天能花在Dungeon的时间一样很少,没有办法进行程序端的调整。只好再花些时间来看...
[Day 27] 中场休息 - 换边发球,heroku布署完整步骤
上一篇我们介绍完了aws如何一步一步把环境架起来 这一篇我们来顺便把前面heroku的坑也填上吧 这...
【C#】Creational Patterns Singleton Mode
单例是设计模式的其中一种~ 它让程序在同一时间~ 只会有一个实例化的物件~ 设计的思维很简单~ 就是...
【修正模型】4-1 执行上下文(Execution Context)
经过了二十多天,一路上我们从基本的逻辑思考方式到了解 JavaScript 的意义,再从 JavaS...
Alpine Linux Porting (2.1) clock is _not_ ticking
这篇开始基本上是进入持续分析有哪些未完善的部份需要进行补足。 依照这几次的bootlog的部份分析,...