卡夫卡的藏书阁【Book1】- 大纲和Kafka基础介绍
缘起
身为铁人赛多年忠实读者的我,没想到有一天会亲自上场,突破舒适圈只需要一股冲动,身为middle码农的我被某人一个推坑,回过神就已经在打这篇开头了。

为什麽选择 Kafka 作为主题
Kafka的命名就是由捷克着名的作家卡夫卡而来,2011年LinkedIn开源出来,2012年被Apache孵化,近几年已经被各大科技公司广泛使用,虽然Kafka已经出来很多年,在survey相关资讯时发现中文资源还是相对偏少,如果可以利用铁人赛将Kafka做个简单介绍,相信对於各位有需要的攻城狮们会有所帮助,或是根本就是半年後的自己。
Kafka 是什麽
A distributed streaming platform
这是 Kafka 官网给自己下的定义,由此可知 Kafka 并只是单纯的一个 Message Queue,而是一个分布式的资讯串流平台,可以让你发布、订阅、处理资料串流,拥有分布性、性能极强、可扩充性很高 I/O 吞吐量,并且在高吞吐量下还可以维持低延迟。
Kafka 的使用场景
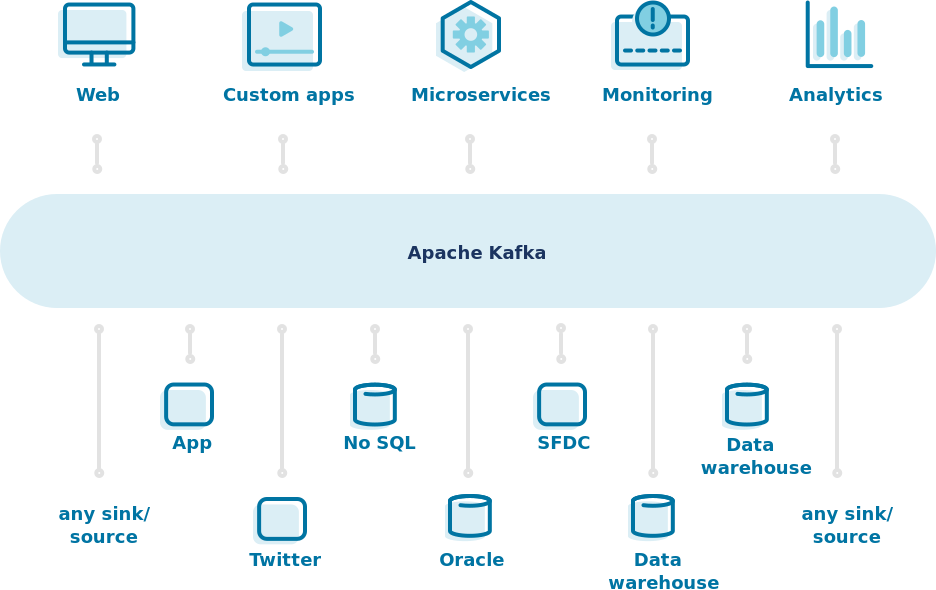
=> 图片引用至 Apache Kafka 官网
- 系统监控:这是 LinkedIn 最一开始开发 Kafka 的使用目的,将每台服务的 CPU数据、IO、request、connect..等资料进行统计分析。
- 讯息系统:一般的使用场景在於异步处理、将纠缠的服务解耦,使用方式类似於常见 ActiveMQ 或是 RabbitMQ。但 Kafka 的优势是拥有低延迟且更大的吞吐量,内建的 partition 和 replica 副本制度,可以保证资料的持久性,这也是一般 MQ 系统所没能拥有的。
- 操作记录:将使用者的各种行为储存下来,并利用即时的发布、订阅系统将资料做立即的处理、监控,或是将资料放到离线的 hadoop 系统作分析。
Kafka 的优点
- 具有扩展性:因为 Kafka 的资料是持久化的,不会因为有消费者消费而消失,并且 Kafka 可以将你复杂的应用系统解耦,因此需要扩张的时候,不需要新增程序,也不需要调整参数,只需要另外增加消费者来处理资料即可。
- 避免峰值:在瞬间大流量的使用场景下,Kafka 可以将避免应用服务的崩溃,不会因为超过负载的流量请求而停止运作。
- 保证其顺序性:这也是 Kafka 读取速度的保证,因为磁碟顺序读取的速度较随机存入快很多,大部分的 MQ 设计本身就是有顺序性的队列,而 Kafka 在这里保证的是每一个 paritition 中资料的顺序性,但不能保证同时读取多个 partition 的顺序性,因此比较适用的场景是不在乎资料前後顺序的使用状况。
- 持久性:使用 MQ 的过程常常会遇到,资料尚未被持久化就遗失的情况,Kafka 可以保证资料已经同步到多个副本後才进行 commit,可以尽量避免资料遗失的状况,在实际使用场景上,像是 Producer 或是 Consumer 连结断线的资料遗失也都有相对性的设定可以极大程度地去避免掉。
Kafka 的缺点
- Kafka 有点肥,你只是单纯需要讯息对列这个功能,那就用 RabbitMQ 吧,如果你系统每天仅需要处理几千、几万条讯息,Kafka 不管是初始的部署和维运都需要不少的成本,因此吞吐量较小的话就不建议使用了
- Kafka 生产者有可能会重复消费讯息
- Kafka 是利用顺序写入来达到高吞吐量,但是其中一台机器挂掉後,就会导致讯息乱序
- 第三方套件未成熟、仍然有很多功能不支援,社群的活跃性交低
- 仅保证单一分区有顺序性,但无法保证多分区的顺序性
- 监控资源不完整,需要额外安装套件
- 依赖 Zookeeper,还要额外花费成本维护 Zookeeper
- 实际上讯息是批次传送,所以并不是绝对的实时的
Your business is in motion. Now, you have a data platform for it. Confluent makes it easy to connect your apps, systems, and your entire organization with real-time data flow and processing.
接下来30天让我们一步步慢慢探索Kafka的世界,目前规划纲要是:基础的介绍、安装和内建的脚本使用、常用指令介绍和设定、进阶使用介绍
希望可以顺利完赛、铁人链成!
资料来源:
https://www.confluent.io/what-is-apache-kafka
[Day 16] 资料产品生命周期管理-预测模型的部署与管理(MLOps)
昨天提到了怎麽开发预测模型,但模型绝对不是开发完就好,後续还有非常多的事情得做。 Deploymen...
爬虫怎麽爬 从零开始的爬虫自学 DAY8 python变数使用
前言 各位早安,书接上回我们了解变数要如何合法取名,也示范了错误取名法,今天我们要来尝试变数到底能用...
从0开始!Python 数据分析(1)|环境安装
我使用Anaconda帮我们管理套件以及不同的开发环境,让程序码可以在特定套件下执行,还可以在不同环...
Day 21. 条件渲染 – v-if、v-show
今天来讲条件渲染(Conditional Rendering),也就是可以依照条件变化改变渲染元素的...
[Day19] NLP会用到的模型(三)-RNN应用
一. 任务类型 RNN可以根据任务类型不同分成一对一、一对多、多对一等模型,如下图(来源): 一对一...