[自然语言处理基础] 语法分析与资讯检索 (II)
前言
上一回我们将词性标签依序排列建构出片语组块( phrase chunk ),描绘出相应的分析树,藉由简单的文法结构来分析句子。当我们在进行语块分析时并不会要求建构出完整的分析树,因此语块分析属於浅层句法分析( shallow parsing )的范畴。我们今天将延续对於语块分析的探讨,以及如何利用构造简短的语块就能在文本资料中搜寻并提取必要的资讯,实现资讯检索( information retrieval, IR )。
Not all applications require a complete syntactic analysis, and often a full parse provides more information than needed. One example is Information Retrieval, for which it may be enough to find simple noun phrases and verb phrases. Text chunking usually provides enough syntactic information for several such applications.
文字出处:A Machine Learning Approach for Portuguese Text Chunking (2011)
文法解析(Parsing)-续
不同的分块方式会得到不同的分析树
图片出处:New open access resource will support text mining and natural language processing

词块滤除(Chunking Filtering)
一般而言,体现任何文法结构的语块都可以被形式上表示为:
chunk = "grammar_name: {<.*>+}"
前面的 grammar_name 表示语块的名称,我们可自行命名,例如 NP ( noun phrase :名词片语)、 RC ( relative clause :关系子句)等等;後面{ }中表示代表词性标签序列的正则表达式,例如<VB>表示一般原形动词( verb, base form )、<CC>则表示对等连接词( coordinating conjunction )。
之前我们透过了蒐集欲比对的词性标签,按顺序进行排列,以建构符合某一文法的片语分块。这次我们不妨逆向思考,考虑滤除不想要的词性来构造语块。以名词片语为例,具有名词功能的词组应当是不包含任何动词以及介系词(如 in 、 with 、 among 等)且不等於从属连接词(如 before 、 when 、 where )的。因此考虑所有不等於 <VB.?> 且不等於 <IN> 的词性标签,就构成了名词片语的分块:
# alternative of a noun phrase chunk
np_chunk = """NP: {<.*>+} # any part of speech
}<VB.?|IN>+{ # any verb, preposition or subordinating conjunction """
{ }里摆放的是欲蒐集的词性标签,} {中则摆放不想蒐集的词性标签,这个技巧是为语块滤除( chunk filtering ),正是集合的差集运算。
自然语言分析手法
自然语言处理中有大致可分为两类分析手法:
- 成分句法分析( Constituency Parsing ):根据片语的文法结构来进行文句解析,以上介绍的语块分析即属於此类。
基於成分句法分析的分析树
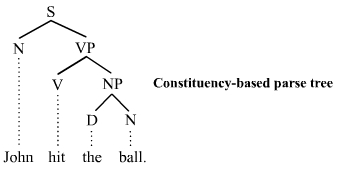
- 依存句法分析( Dependency Parsing ):不只比照句法结构,还考虑了语意的相依性。
基於依存句法分析的分析树
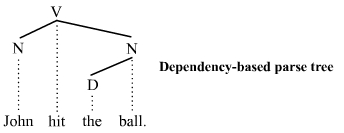
应用实例:文章资讯检索
介绍完了文法解析之後,我们接下来浏览一篇新闻报导,藉由一系列前处理、词性标签以及语块分析的技巧,找出文本中的关键资讯。
我们预先写好两个模组:tokenise_words.py 以及 chunk_counters.py
以下为 tokenise_words 模组:将清理过的字串进行断句与断词
# filename: tokenise_words.py
from nltk.tokenize import PunktSentenceTokenizer, word_tokenize
def word_sentence_tokenise(text):
"""
text: clean text
-----------------------------
Step 1: sentence segmenation
Step 2: tokenisation
"""
sentence_tokeniser = PunktSentenceTokenizer(text)
# sentence tokenise text
sentence_tokenised = sentence_tokeniser.tokenize(text)
# create a list to hold word tokenised sentences
word_tokenised = list()
# for-loop through each tokenized sentence in sentence_tokenized
for tokenized_sentence in sentence_tokenised:
# word tokenize each sentence and append to word_tokenized
word_tokenised.append(word_tokenize(tokenized_sentence))
return word_tokenised
接下来是计算 chunk_counters 模组:
# filename: chunk_counters.py
from collections import Counter
def np_chunk_counter(chunked_sentences, rmvStopWords = True):
"""
Pulls chunks out of chunked sentence and finds the most common chunks
"""
chunks = list()
# extract NP chunks
for chunked_sentence in chunked_sentences:
for subtree in chunked_sentence.subtrees(filter = lambda t: t.label() == "NP"):
chunks.append(tuple(subtree))
chunk_counter = Counter()
for chunk in chunks:
# increase counter of specific chunk by 1
chunk_counter[chunk] += 1
print("chunk_counter:", chunk_counter)
# return 30 most frequent chunks
return chunk_counter.most_common(30)
def vp_chunk_counter(chunked_sentences, rmvStopWords = True):
"""
Pulls chunks out of chunked sentence and finds the most common chunks
"""
chunks = list()
# extract VP chunks
for chunked_sentence in chunked_sentences:
for subtree in chunked_sentence.subtrees(filter = lambda t: t.label() == "VP"):
chunks.append(tuple(subtree))
chunk_counter = Counter()
for chunk in chunks:
# increase counter of specific chunk by 1
chunk_counter[chunk] += 1
# remove stop words from statistical result
print("chunk_counter:", chunk_counter)
# return 30 most frequent chunks
return chunk_counter.most_common(30)
回到主函式 main.py ,引入 NLTK 模组以及我们刚刚定义好的函式:
# filename: main.py
from nltk import pos_tag, RegexpParser
from tokenise_words import word_sentence_tokenise
from chunk_counters import np_chunk_counter, vp_chunk_counter
我们引用了今日的BBC新闻 Facebook under fire over secret teen research 做为欲检索的资料,以下引入之并进行前处理(小写转换 → 断句 → 断词):
with open("data/bbc_news.txt", encoding = "utf-8") as f:
text = f.read().lower()
word_tokenised_text = word_sentence_tokenise(text)
下一步,标注词性:
pos_tagged_text = list()
for word_tokenised_sent in tokenised_text:
pos_tagged_text.append(pos_tag(word_tokenised_sent))
定义名词片语分块和动词片语分块并且建构语法剖析器( parser ):
# define chunk grammars
np_chunk_grammar = "NP: {<DT>?<JJ>*<NN>}"
vp_chunk_grammar = "VP: {<DT>?<JJ>*<NN><VB.?><RB.?>?}"
# creates chunk parsers
np_chunk_parser = RegexpParser(np_chunk_grammar)
vp_chunk_parser = RegexpParser(vp_chunk_grammar)
紧接着,开始分析每一个已经进行断词的句子( chunking ):
np_chunked_text = list()
vp_chunked_text = list()
for pos_tagged_sentence in pos_tagged_text:
np_chunked_text.append(np_chunk_parser.parse(pos_tagged_sentence))
vp_chunked_text.append(vp_chunk_parser.parse(pos_tagged_sentence))
最後,利用稍早定义在模组 chunk_counters 的函式 np_chunk_counter 取出最常出现的名词片语:
# List the most common 30 NP chunks
most_common_np_chunks = np_chunk_counter(np_chunked_text, rmvStopWords = rmvStopWords)
print(most_common_np_chunks)
显示出现频率最高的名词片语排名:
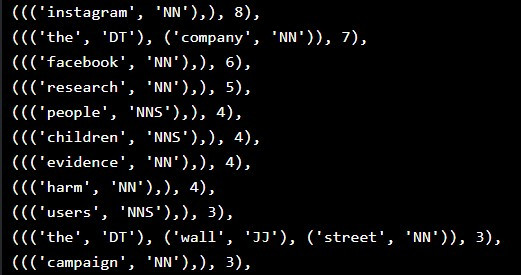
以及最常出现的动词片语:
# List the most common 30 VP chunks
most_common_vp_chunks = vp_chunk_counter(vp_chunked_text, rmvStopWords = rmvStopWords)
print(most_common_vp_chunks)
显示出现频率最高的名词片语排名:

由名词和动词片语分析的结果,我们可以推估这篇文章主要传达的资讯为:「 研究指出 Facebook 、 Instagram 等社群平台对青少年造成不良的影响。」
有了语块分析的技巧,我们可以在未真正阅读文本之前即先检索关键资讯,这样能够帮助我们筛选目标,例如在图书馆查询书籍等等。此时此刻,我们已经踏入自然语言处理的大门,自然语言处理基础也告一段落。从明天开始,我将会介绍自然语言的量化手法以及常见的模型。おやすみなさい!
阅读更多
- NLP and POS based chunking to generate Amazon style Key phrases from Reviews
- Understanding Language Syntax and Structure: A Practitioner’s Guide to NLP
>>: 周末雨会(四):自定义资料类别 Defined Data Class
Spring Framework X Kotlin Day 21 WebSocket
GitHub Repo https://github.com/b2etw/Spring-Kotlin...
Day 29 Polymorphism
多型是物件导向程序设计中第三个重要的概念,他建立在继承的概念上,多型是一种型别,可以解释为具有多个不...
【Day27】建立一个 QA Bot
今天要来跟各位一起解析 QnA Maker Bot,以下简称 QA Bot。 今天是参考 官方范例程...
Day16-sklearn(1)正规化StandardScaler、MinMaxScaler、MaxAbsScaler
正规化 缩小资料的呈现比例 可使数值呈现在一定的范围内 使我们在训练模型时,增加梯度下降的容易度并提...
伸缩自如的Flask [day 29] Line Messaging API
只要再撑过这一天,就只要写结语就可以达成30天的目标了。 本来已经快想不到可以写甚麽了,那就来拿Li...